 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2VLM: Adapting Text-Only Datasets to Evaluate Alignment Training in Visual Language Models
Jul 28, 2025The increasing integration of Visual Language Models (VLMs) into AI systems necessitates robust model alignment, especially when handling multimodal content that combines text and images. Existing evaluation datasets heavily lean towards text-only prompts, leaving visual vulnerabilities under evaluated. To address this gap, we propose \textbf{Text2VLM}, a novel multi-stage pipeline that adapts text-only datasets into multimodal formats, specifically designed to evaluate the resilience of VLMs against typographic prompt injection attacks. The Text2VLM pipeline identifies harmful content in the original text and converts it into a typographic image, creating a multimodal prompt for VLMs. Also, our evaluation of open-source VLMs highlights their increased susceptibility to prompt injection when visual inputs are introduced, revealing critical weaknesses in the current models' alignment. This is in addition to a significant performance gap compared to closed-source frontier models. We validate Text2VLM through human evaluations, ensuring the alignment of extracted salient concepts; text summarization and output classification align with human expectations. Text2VLM provides a scalable tool for comprehensive safety assessment, contributing to the development of more robust safety mechanisms for VLMs. By enhancing the evaluation of multimodal vulnerabilities, Text2VLM plays a role in advancing the safe deployment of VLMs in diverse, real-world applications.
CLARITY -- Comparing heterogeneous data using dissimiLARITY
May 29, 2020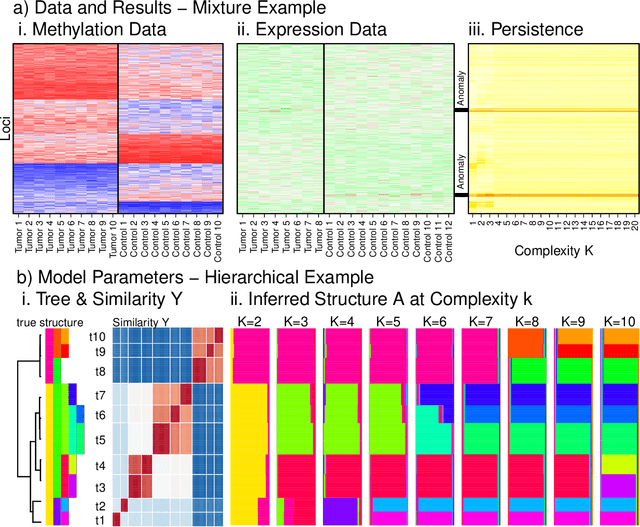
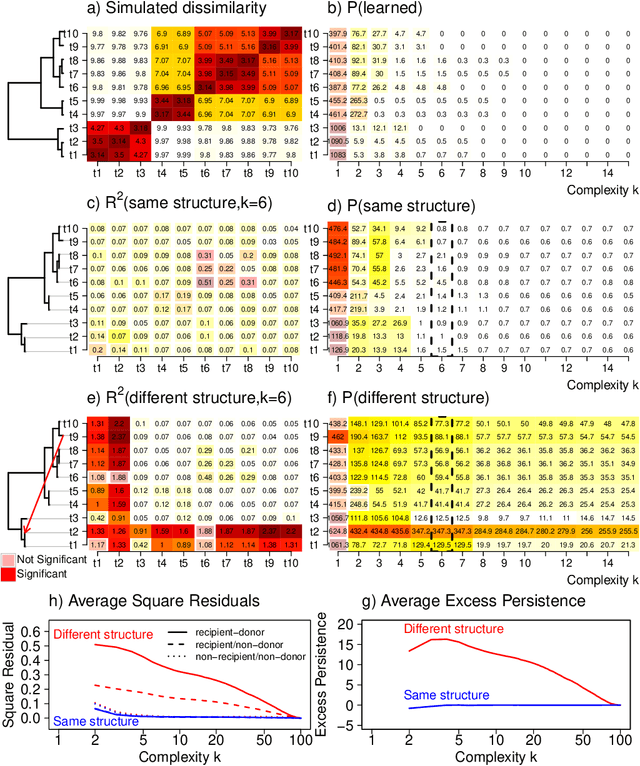
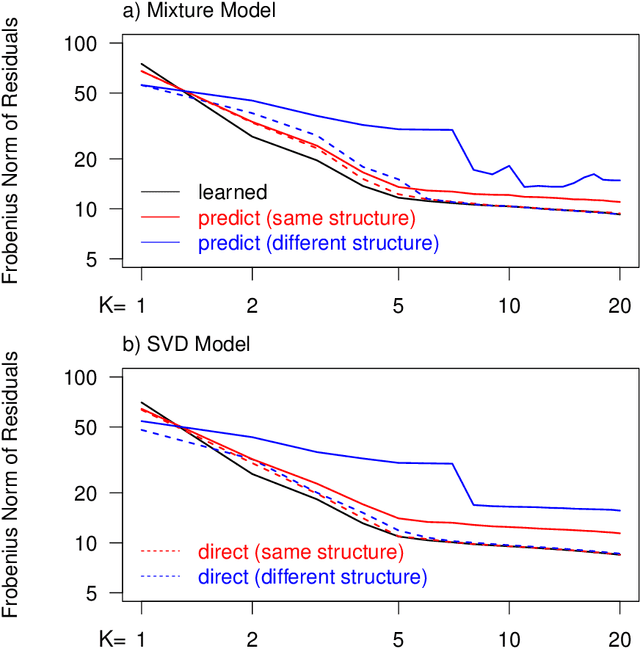
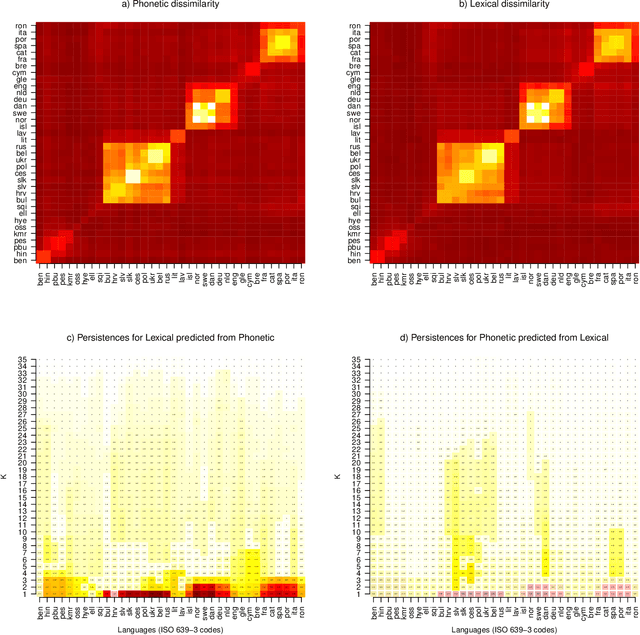
Integrating datasets from different disciplines is hard because the data are often qualitatively different in meaning, scale, and reliability. When two datasets describe the same entities, many scientific questions can be phrased around whether the similarities between entities are conserved. Our method, CLARITY, quantifies consistency across datasets, identifies where inconsistencies arise, and aids in their interpretation. We explore three diverse comparisons: Gene Methylation vs Gene Expression, evolution of language sounds vs word use, and country-level economic metrics vs cultural beliefs. The non-parametric approach is robust to noise and differences in scaling, and makes only weak assumptions about how the data were generated. It operates by decomposing similarities into two components: the `structural' component analogous to a clustering, and an underlying `relationship' between those structures. This allows a `structural comparison' between two similarity matrices using their predictability from `structure'. The software, CLARITY, is available as an R package from https://github.com/danjlawson/CLARITY.
Neutral evolution and turnover over centuries of English word popularity
Mar 30, 2017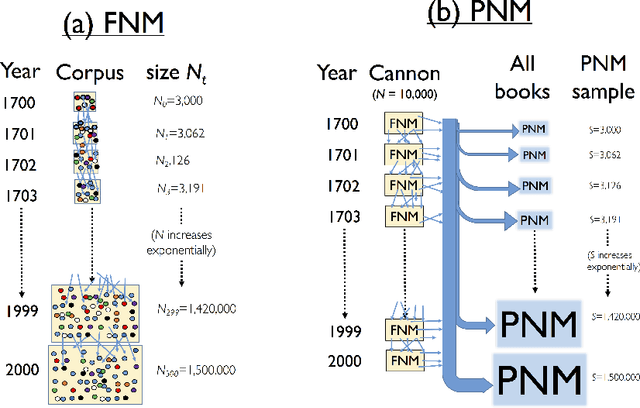
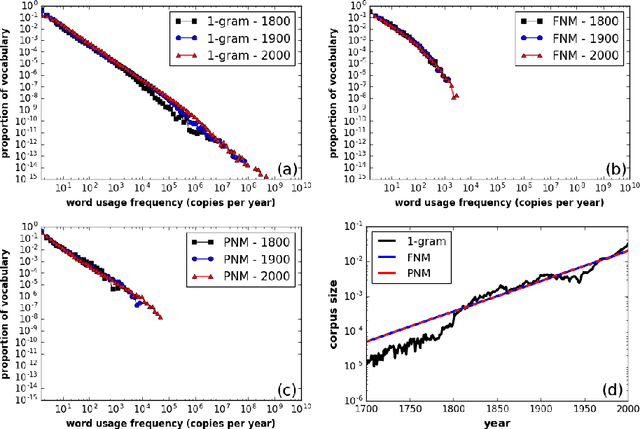
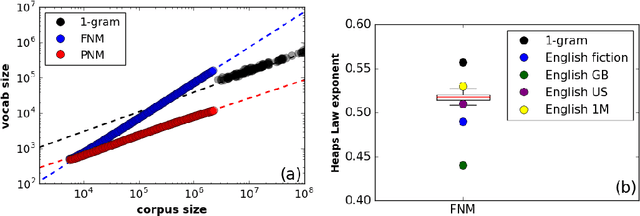
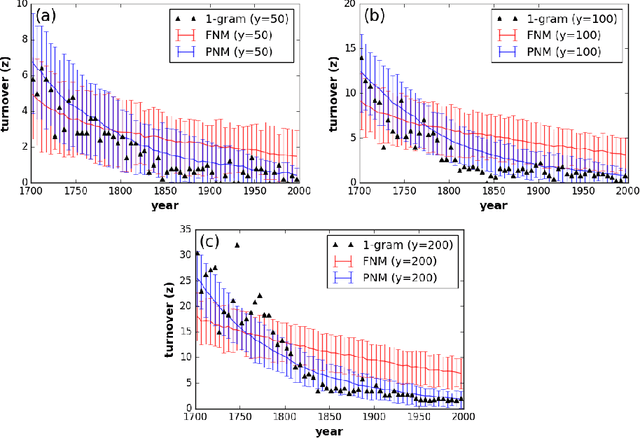
Here we test Neutral models against the evolution of English word frequency and vocabulary at the population scale, as recorded in annual word frequencies from three centuries of English language books. Against these data, we test both static and dynamic predictions of two neutral models, including the relation between corpus size and vocabulary size, frequency distributions, and turnover within those frequency distributions. Although a commonly used Neutral model fails to replicate all these emergent properties at once, we find that modified two-stage Neutral model does replicate the static and dynamic properties of the corpus data. This two-stage model is meant to represent a relatively small corpus (population) of English books, analogous to a `canon', sampled by an exponentially increasing corpus of books in the wider population of authors. More broadly, this mode -- a smaller neutral model within a larger neutral model -- could represent more broadly those situations where mass attention is focused on a small subset of the cultural variants.