 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Deep Learning for Instance Segmentation
Aug 24, 2020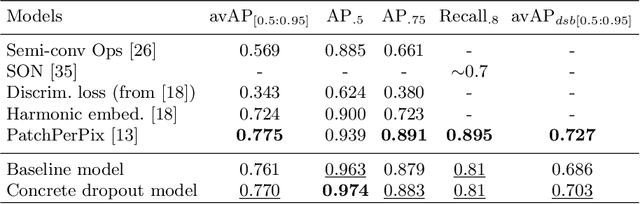

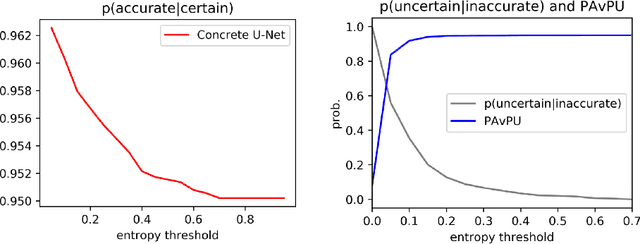
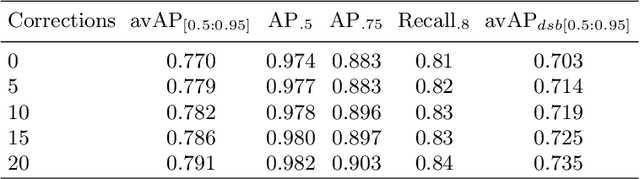
Probabilistic convolutional neural networks, which predict distributions of predictions instead of point estimates, led to recent advances in many areas of computer vision, from image reconstruction to semantic segmentation. Besides state of the art benchmark results, these networks made it possible to quantify local uncertainties in the predictions. These were used in active learning frameworks to target the labeling efforts of specialist annotators or to assess the quality of a prediction in a safety-critical environment. However, for instance segmentation problems these methods are not frequently used so far. We seek to close this gap by proposing a generic method to obtain model-inherent uncertainty estimates within proposal-free instance segmentation models. Furthermore, we analyze the quality of the uncertainty estimates with a metric adapted from semantic segmentation. We evaluate our method on the BBBC010 C.\ elegans dataset, where it yields competitive performance while also predicting uncertainty estimates that carry information about object-level inaccuracies like false splits and false merges. We perform a simulation to show the potential use of such uncertainty estimates in guided proofreading.
An Auxiliary Task for Learning Nuclei Segmentation in 3D Microscopy Images
Feb 07, 2020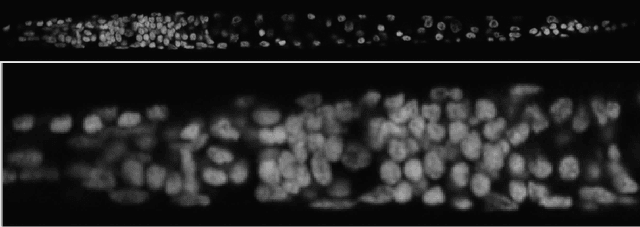
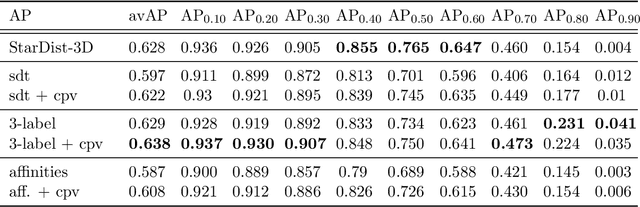

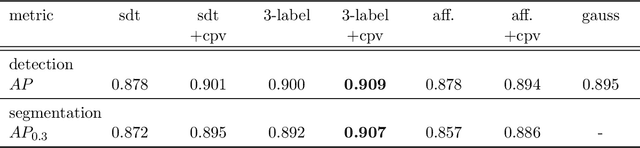
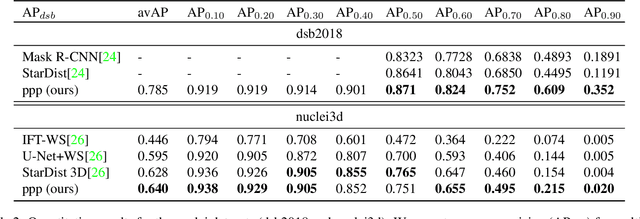
Segmentation of cell nuclei in microscopy images is a prevalent necessity in cell biology. Especially for three-dimensional datasets, manual segmentation is prohibitively time-consuming, motivating the need for automated methods. Learning-based methods trained on pixel-wise ground-truth segmentations have been shown to yield state-of-the-art results on 2d benchmark image data of nuclei, yet a respective benchmark is missing for 3d image data. In this work, we perform a comparative evaluation of nuclei segmentation algorithms on a database of manually segmented 3d light microscopy volumes. We propose a novel learning strategy that boosts segmentation accuracy by means of a simple auxiliary task, thereby robustly outperforming each of our baselines. Furthermore, we show that one of our baselines, the popular three-label model, when trained with our proposed auxiliary task, outperforms the recent StarDist-3D. As an additional, practical contribution, we benchmark nuclei segmentation against nuclei detection, i.e. the task of merely pinpointing individual nuclei without generating respective pixel-accurate segmentations. For learning nuclei detection, large 3d training datasets of manually annotated nuclei center points are available. However, the impact on detection accuracy caused by training on such sparse ground truth as opposed to dense pixel-wise ground truth has not yet been quantified. To this end, we compare nuclei detection accuracy yielded by training on dense vs. sparse ground truth. Our results suggest that training on sparse ground truth yields competitive nuclei detection rates.
PatchPerPix for Instance Segmentation
Jan 21, 2020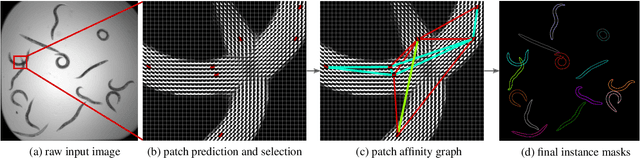
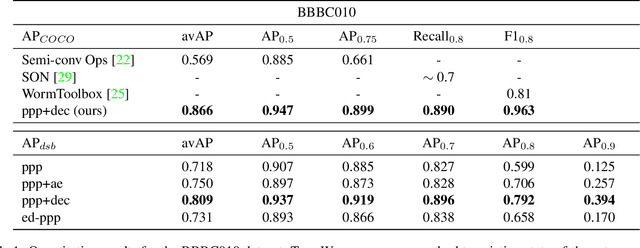
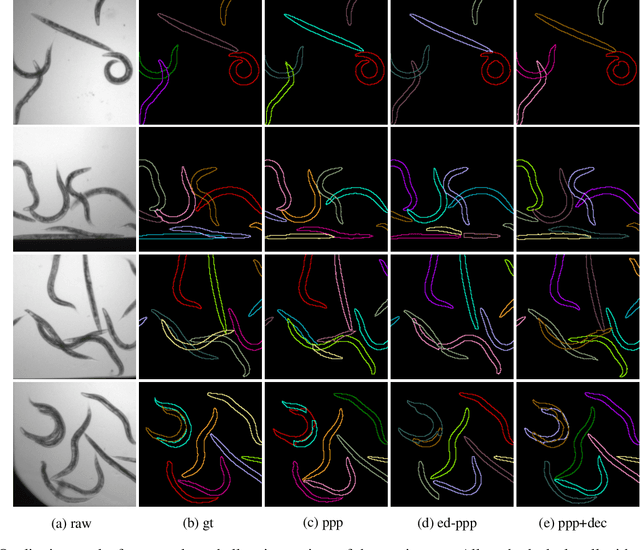
In this paper we present a novel method for proposal free instance segmentation that can handle sophisticated object shapes that span large parts of an image and form dense object clusters with crossovers. Our method is based on predicting dense local shape descriptors, which we assemble to form instances. All instances are assembled simultaneously in one go. To our knowledge, our method is the first non-iterative method that guarantees instances to be composed of learnt shape patches. We evaluate our method on a variety of data domains, where it defines the new state of the art on two challenging benchmarks, namely the ISBI 2012 EM segmentation benchmark, and the BBBC010 C. elegans dataset. We show furthermore that our method performs well also on 3d image data, and can handle even extreme cases of complex shape clusters.
Mapping Auto-context Decision Forests to Deep ConvNets for Semantic Segmentation
Aug 13, 2018

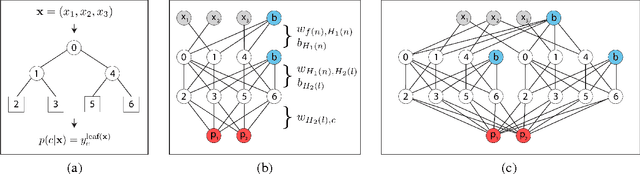
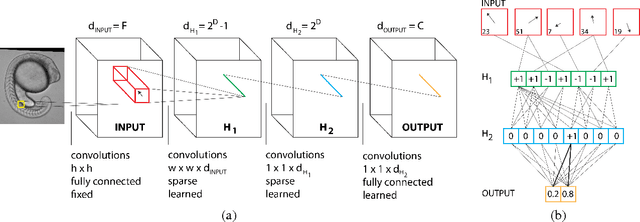
We consider the task of pixel-wise semantic segmentation given a small set of labeled training images. Among two of the most popular techniques to address this task are Decision Forests (DF) and Neural Networks (NN). In this work, we explore the relationship between two special forms of these techniques: stacked DFs (namely Auto-context) and deep Convolutional Neural Networks (ConvNet). Our main contribution is to show that Auto-context can be mapped to a deep ConvNet with novel architecture, and thereby trained end-to-end. This mapping can be used as an initialization of a deep ConvNet, enabling training even in the face of very limited amounts of training data. We also demonstrate an approximate mapping back from the refined ConvNet to a second stacked DF, with improved performance over the original. We experimentally verify that these mappings outperform stacked DFs for two different applications in computer vision and biology: Kinect-based body part labeling from depth images, and somite segmentation in microscopy images of developing zebrafish. Finally, we revisit the core mapping from a Decision Tree (DT) to a NN, and show that it is also possible to map a fuzzy DT, with sigmoidal split decisions, to a NN. This addresses multiple limitations of the previous mapping, and yields new insights into the popular Rectified Linear Unit (ReLU), and more recently proposed concatenated ReLU (CReLU), activation functions.
A Study of Lagrangean Decompositions and Dual Ascent Solvers for Graph Matching
Jan 12, 2017
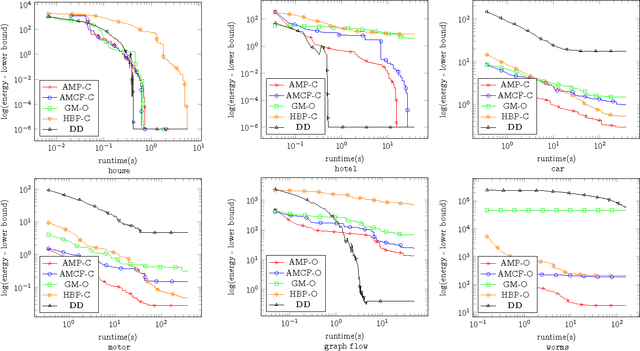
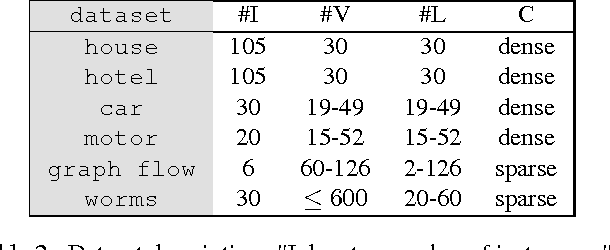
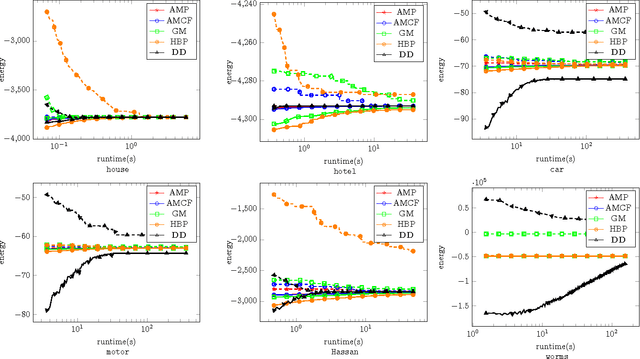
We study the quadratic assignment problem, in computer vision also known as graph matching. Two leading solvers for this problem optimize the Lagrange decomposition duals with sub-gradient and dual ascent (also known as message passing) updates. We explore s direction further and propose several additional Lagrangean relaxations of the graph matching problem along with corresponding algorithms, which are all based on a common dual ascent framework. Our extensive empirical evaluation gives several theoretical insights and suggests a new state-of-the-art any-time solver for the considered problem. Our improvement over state-of-the-art is particularly visible on a new dataset with large-scale sparse problem instances containing more than 500 graph nodes each.
Convexity Shape Constraints for Image Segmentation
Sep 07, 2015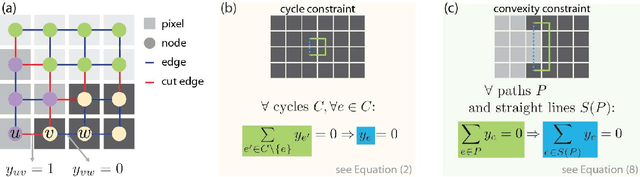

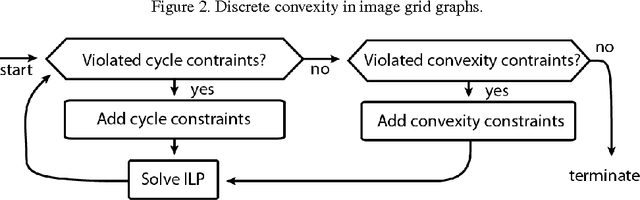

Segmenting an image into multiple components is a central task in computer vision. In many practical scenarios, prior knowledge about plausible components is available. Incorporating such prior knowledge into models and algorithms for image segmentation is highly desirable, yet can be non-trivial. In this work, we introduce a new approach that allows, for the first time, to constrain some or all components of a segmentation to have convex shapes. Specifically, we extend the Minimum Cost Multicut Problem by a class of constraints that enforce convexity. To solve instances of this APX-hard integer linear program to optimality, we separate the proposed constraints in the branch-and-cut loop of a state-of-the-art ILP solver. Results on natural and biological images demonstrate the effectiveness of the approach as well as its advantage over the state-of-the-art heuristic.