 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Saliency-based Convolutional Neural Network for Table and Chart Detection in Digitized Documents
Apr 17, 2018
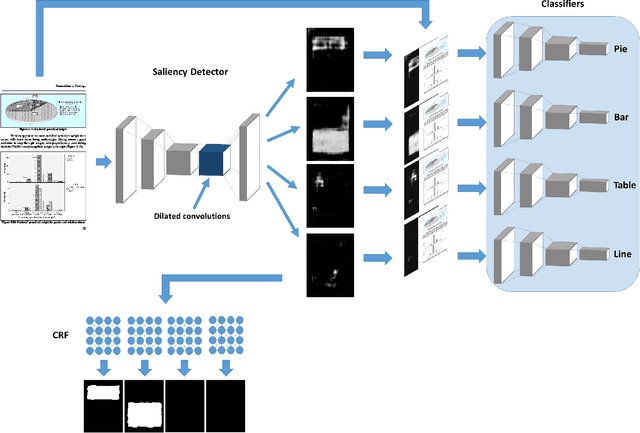


Deep Convolutional Neural Networks (DCNNs) have recently been applied successfully to a variety of vision and multimedia tasks, thus driving development of novel solutions in several application domains. Document analysis is a particularly promising area for DCNNs: indeed, the number of available digital documents has reached unprecedented levels, and humans are no longer able to discover and retrieve all the information contained in these documents without the help of automation. Under this scenario, DCNNs offers a viable solution to automate the information extraction process from digital documents. Within the realm of information extraction from documents, detection of tables and charts is particularly needed as they contain a visual summary of the most valuable information contained in a document. For a complete automation of visual information extraction process from tables and charts, it is necessary to develop techniques that localize them and identify precisely their boundaries. In this paper we aim at solving the table/chart detection task through an approach that combines deep convolutional neural networks, graphical models and saliency concepts. In particular, we propose a saliency-based fully-convolutional neural network performing multi-scale reasoning on visual cues followed by a fully-connected conditional random field (CRF) for localizing tables and charts in digital/digitized documents. Performance analysis carried out on an extended version of ICDAR 2013 (with annotated charts as well as tables) shows that our approach yields promising results, outperforming existing models.
VOS-GAN: Adversarial Learning of Visual-Temporal Dynamics for Unsupervised Dense Prediction in Videos
Mar 24, 2018
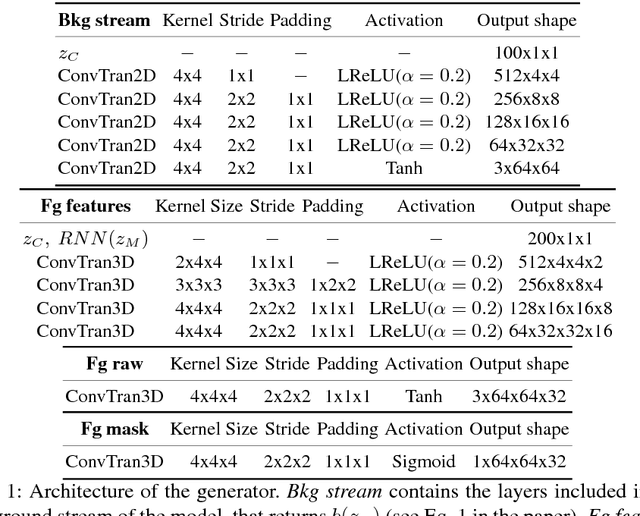
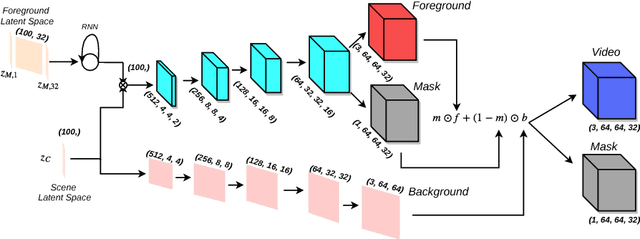
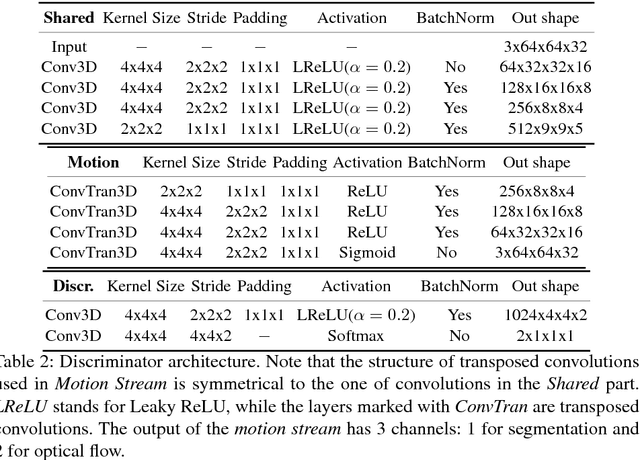
Recent GAN-based video generation approaches model videos as the combination of a time-independent scene component and a time-varying motion component, thus factorizing the generation problem into generating background and foreground separately. One of the main limitations of current approaches is that both factors are learned by mapping one source latent space to videos, which complicates the generation task as a single data point must be informative of both background and foreground content. In this paper we propose a GAN framework for video generation that, instead, employs two latent spaces in order to structure the generative process in a more natural way: 1) a latent space to generate the static visual content of a scene (background), which remains the same for the whole video, and 2) a latent space where motion is encoded as a trajectory between sampled points and whose dynamics are modeled through an RNN encoder (jointly trained with the generator and the discriminator) and then mapped by the generator to visual objects' motion. Additionally, we extend current video discrimination approaches by incorporating in the learning procedure motion estimation and, leveraging the peculiarity of the generation process, unsupervised pixel-wise dense predictions. Extensive performance evaluation showed that our approach is able to a) synthesize more realistic videos than state-of-the-art methods, b) learn effectively both local and global video dynamics, as demonstrated by the results achieved on a video action recognition task over the UCF-101 dataset, and c) accurately perform unsupervised video object segmentation on standard video benchmarks, such as DAVIS, SegTrack and F4K-Fish.