 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRacka: Efficient Hungarian LLM Adaptation on Academic Infrastructure
Jan 03, 2026We present Racka, a lightweight, continually pretrained large language model designed to bridge the resource gap between Hungarian and high-resource languages such as English and German. Racka employs parameter-efficient continual pretraining via Low-Rank Adaptation (LoRA) on a Qwen-3 4B backbone, making the recipe practical on A100 (40GB)-based HPC clusters with low inter-node bandwidth. To better match the training distribution, we replace and adapt the tokenizer, achieving substantially improved tokenization fertility for Hungarian while maintaining competitive performance in English and German. The model is trained on 160B subword tokens drawn from a mixture of internet and high-quality curated sources, with a composition of 44% Hungarian, 24% English, 21% German, and 11% code. This data mix is chosen to mitigate catastrophic forgetting and preserve high-resource language capabilities during continual pretraining. Our preliminary results indicate modest but stable results in language adaptation.
Evaluating Contextualized Language Models for Hungarian
Feb 22, 2021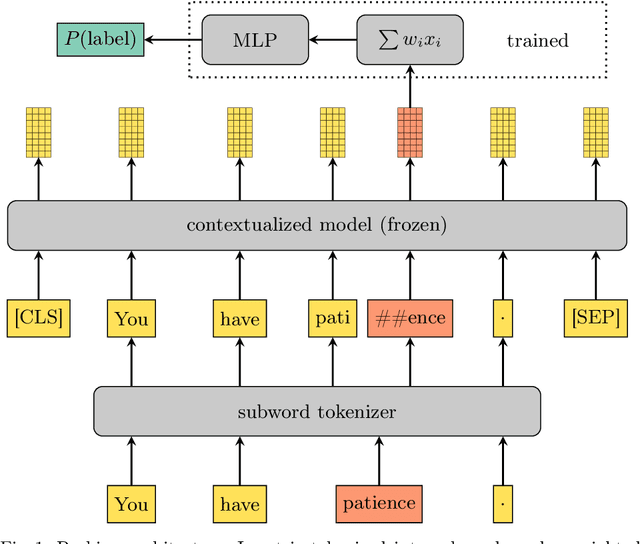
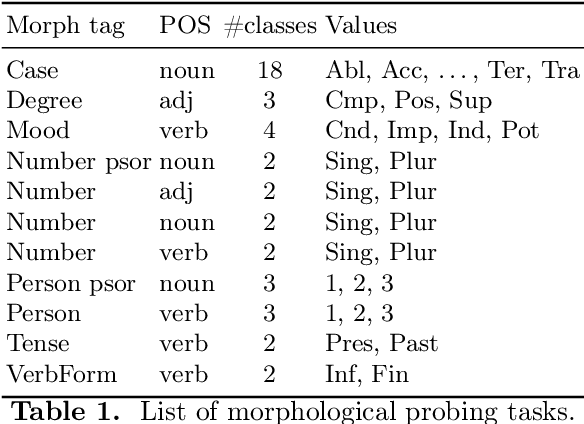

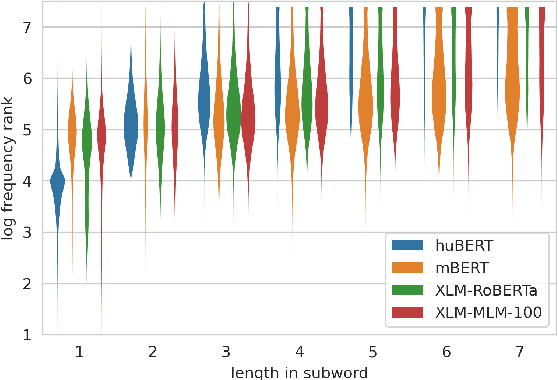
We present an extended comparison of contextualized language models for Hungarian. We compare huBERT, a Hungarian model against 4 multilingual models including the multilingual BERT model. We evaluate these models through three tasks, morphological probing, POS tagging and NER. We find that huBERT works better than the other models, often by a large margin, particularly near the global optimum (typically at the middle layers). We also find that huBERT tends to generate fewer subwords for one word and that using the last subword for token-level tasks is generally a better choice than using the first one.
emLam -- a Hungarian Language Modeling baseline
Jan 26, 2017



This paper aims to make up for the lack of documented baselines for Hungarian language modeling. Various approaches are evaluated on three publicly available Hungarian corpora. Perplexity values comparable to models of similar-sized English corpora are reported. A new, freely downloadable Hungar- ian benchmark corpus is introduced.
* Additional resources: - the emLam repository: https://github.com/DavidNemeskey/emLam - the emLam corpus: http://hlt.bme.hu/en/resources/emLam