 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024



We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024



We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models
May 23, 2022
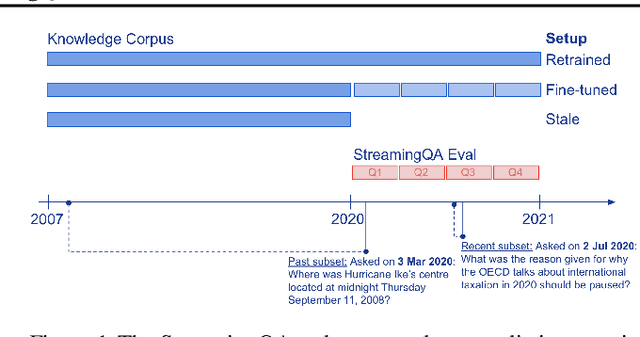

Knowledge and language understanding of models evaluated through question answering (QA) has been usually studied on static snapshots of knowledge, like Wikipedia. However, our world is dynamic, evolves over time, and our models' knowledge becomes outdated. To study how semi-parametric QA models and their underlying parametric language models (LMs) adapt to evolving knowledge, we construct a new large-scale dataset, StreamingQA, with human written and generated questions asked on a given date, to be answered from 14 years of time-stamped news articles. We evaluate our models quarterly as they read new articles not seen in pre-training. We show that parametric models can be updated without full retraining, while avoiding catastrophic forgetting. For semi-parametric models, adding new articles into the search space allows for rapid adaptation, however, models with an outdated underlying LM under-perform those with a retrained LM. For questions about higher-frequency named entities, parametric updates are particularly beneficial. In our dynamic world, the StreamingQA dataset enables a more realistic evaluation of QA models, and our experiments highlight several promising directions for future research.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
A Systematic Investigation of Commonsense Understanding in Large Language Models
Oct 31, 2021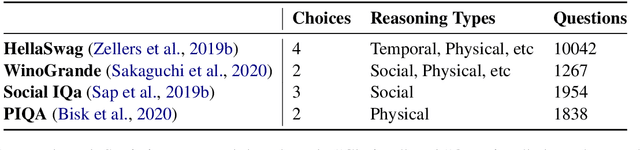
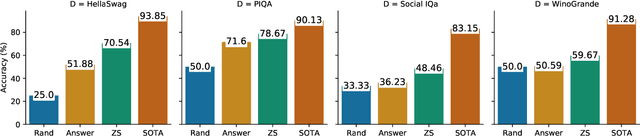

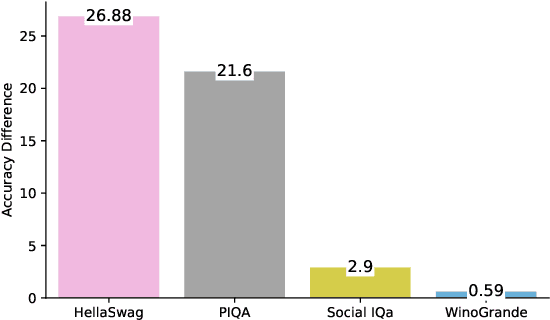
Large language models have shown impressive performance on many natural language processing (NLP) tasks in a zero-shot setting. We ask whether these models exhibit commonsense understanding -- a critical component of NLP applications -- by evaluating models against four commonsense benchmarks. We find that the impressive zero-shot performance of large language models is mostly due to existence of dataset bias in our benchmarks. We also show that the zero-shot performance is sensitive to the choice of hyper-parameters and similarity of the benchmark to the pre-training datasets. Moreover, we did not observe substantial improvements when evaluating models in a few-shot setting. Finally, in contrast to previous work, we find that leveraging explicit commonsense knowledge does not yield substantial improvement.
Adaptive Semiparametric Language Models
Feb 04, 2021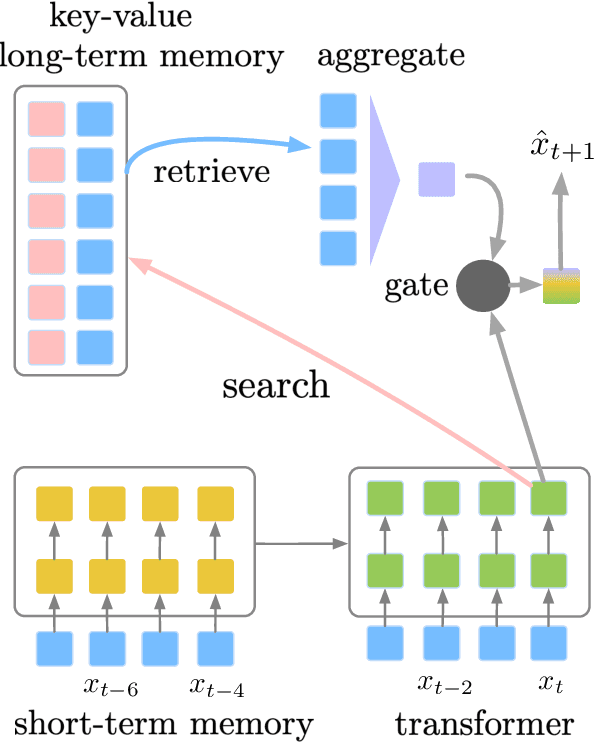
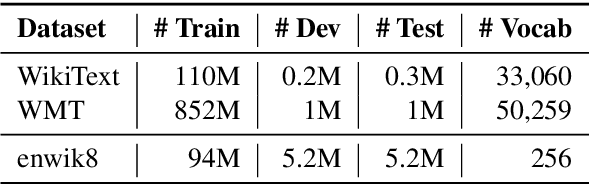
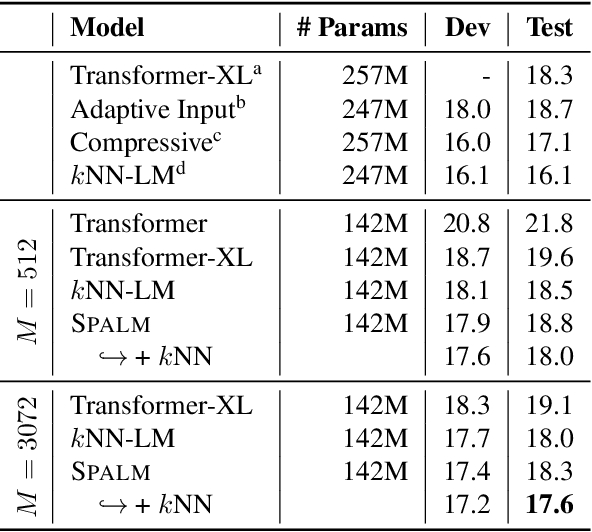
We present a language model that combines a large parametric neural network (i.e., a transformer) with a non-parametric episodic memory component in an integrated architecture. Our model uses extended short-term context by caching local hidden states -- similar to transformer-XL -- and global long-term memory by retrieving a set of nearest neighbor tokens at each timestep. We design a gating function to adaptively combine multiple information sources to make a prediction. This mechanism allows the model to use either local context, short-term memory, or long-term memory (or any combination of them) on an ad hoc basis depending on the context. Experiments on word-based and character-based language modeling datasets demonstrate the efficacy of our proposed method compared to strong baselines.
Pitfalls of Static Language Modelling
Feb 03, 2021
Our world is open-ended, non-stationary and constantly evolving; thus what we talk about and how we talk about it changes over time. This inherent dynamic nature of language comes in stark contrast to the current static language modelling paradigm, which constructs training and evaluation sets from overlapping time periods. Despite recent progress, we demonstrate that state-of-the-art Transformer models perform worse in the realistic setup of predicting future utterances from beyond their training period -- a consistent pattern across three datasets from two domains. We find that, while increasing model size alone -- a key driver behind recent progress -- does not provide a solution for the temporal generalization problem, having models that continually update their knowledge with new information can indeed slow down the degradation over time. Hence, given the compilation of ever-larger language modelling training datasets, combined with the growing list of language-model-based NLP applications that require up-to-date knowledge about the world, we argue that now is the right time to rethink our static language modelling evaluation protocol, and develop adaptive language models that can remain up-to-date with respect to our ever-changing and non-stationary world.
A Mutual Information Maximization Perspective of Language Representation Learning
Nov 26, 2019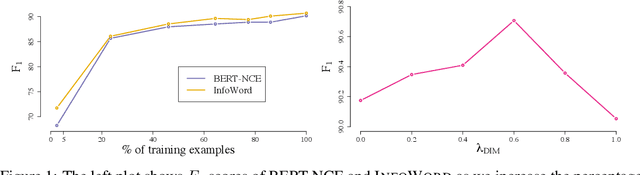
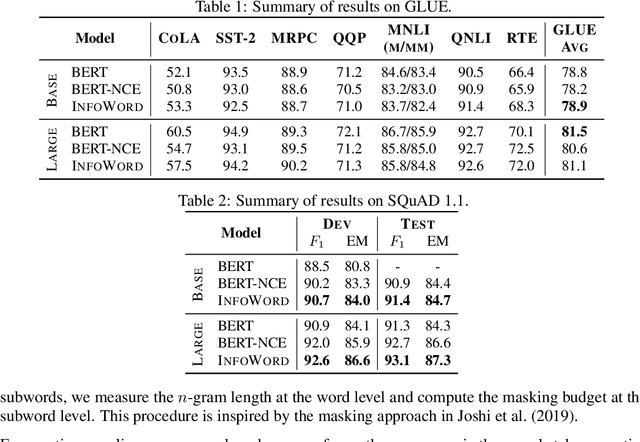
We show state-of-the-art word representation learning methods maximize an objective function that is a lower bound on the mutual information between different parts of a word sequence (i.e., a sentence). Our formulation provides an alternative perspective that unifies classical word embedding models (e.g., Skip-gram) and modern contextual embeddings (e.g., BERT, XLNet). In addition to enhancing our theoretical understanding of these methods, our derivation leads to a principled framework that can be used to construct new self-supervised tasks. We provide an example by drawing inspirations from related methods based on mutual information maximization that have been successful in computer vision, and introduce a simple self-supervised objective that maximizes the mutual information between a global sentence representation and n-grams in the sentence. Our analysis offers a holistic view of representation learning methods to transfer knowledge and translate progress across multiple domains (e.g., natural language processing, computer vision, audio processing).
Episodic Memory in Lifelong Language Learning
Jun 03, 2019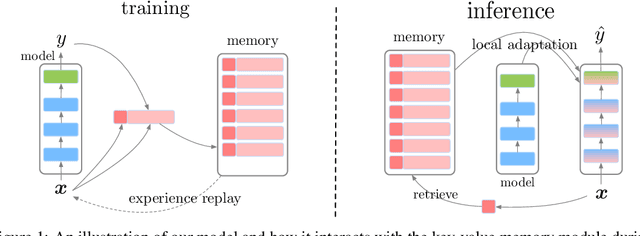
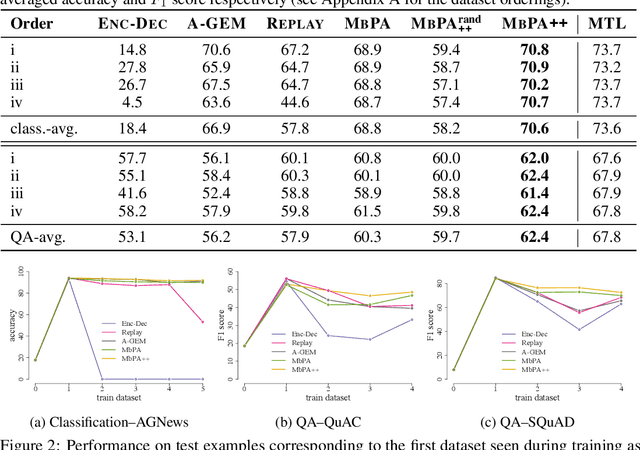

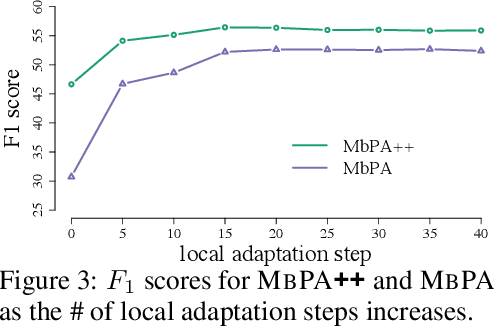
We introduce a lifelong language learning setup where a model needs to learn from a stream of text examples without any dataset identifier. We propose an episodic memory model that performs sparse experience replay and local adaptation to mitigate catastrophic forgetting in this setup. Experiments on text classification and question answering demonstrate the complementary benefits of sparse experience replay and local adaptation to allow the model to continuously learn from new datasets. We also show that the space complexity of the episodic memory module can be reduced significantly (~50-90%) by randomly choosing which examples to store in memory with a minimal decrease in performance. We consider an episodic memory component as a crucial building block of general linguistic intelligence and see our model as a first step in that direction.
Training language GANs from Scratch
May 23, 2019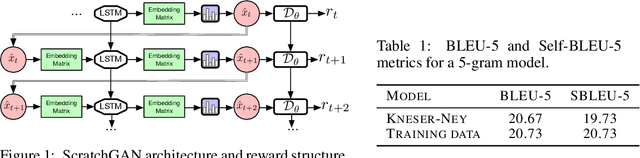
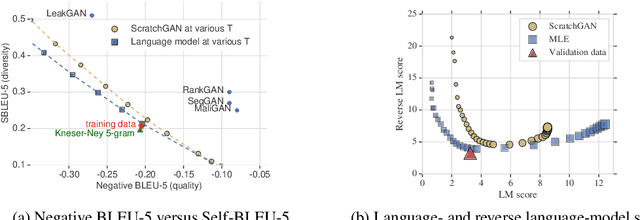
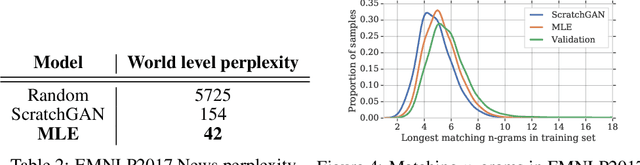
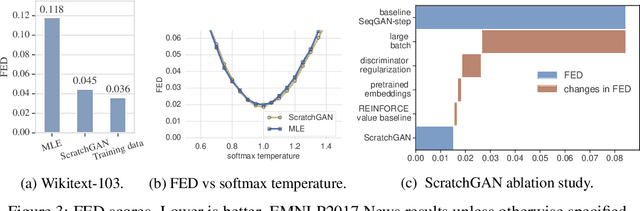
Generative Adversarial Networks (GANs) enjoy great success at image generation, but have proven difficult to train in the domain of natural language. Challenges with gradient estimation, optimization instability, and mode collapse have lead practitioners to resort to maximum likelihood pre-training, followed by small amounts of adversarial fine-tuning. The benefits of GAN fine-tuning for language generation are unclear, as the resulting models produce comparable or worse samples than traditional language models. We show it is in fact possible to train a language GAN from scratch -- without maximum likelihood pre-training. We combine existing techniques such as large batch sizes, dense rewards and discriminator regularization to stabilize and improve language GANs. The resulting model, ScratchGAN, performs comparably to maximum likelihood training on EMNLP2017 News and WikiText-103 corpora according to quality and diversity metrics.