 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriAct: Beyond Verifiability -- Agentic Synthesis of Correct and Complete Formal Specifications
Mar 31, 2026Formal specifications play a central role in ensuring software reliability and correctness. However, automatically synthesizing high-quality formal specifications remains a challenging task, often requiring domain expertise. Recent work has applied large language models to generate specifications in Java Modeling Language (JML), reporting high verification pass rates. But does passing a verifier mean that the specification is actually correct and complete? In this work, we first conduct a comprehensive evaluation comparing classical and prompt-based approaches for automated JML specification synthesis. We then investigate whether prompt optimization can push synthesis quality further by evolving prompts through structured verification feedback. While optimization improves verifier pass rates, we find a clear performance ceiling. More critically, we propose Spec-Harness, an evaluation framework that measures specification correctness and completeness through symbolic verification, revealing that a large fraction of verifier-accepted specifications, including optimized ones, are in fact incorrect or incomplete, over- or under-constraining both inputs and outputs in ways invisible to the verifier. To push beyond this ceiling, we propose VeriAct, a verification-guided agentic framework that iteratively synthesizes and repairs specifications through a closed loop of LLM-driven planning, code execution, verification, and Spec-Harness feedback. Our experiments on two benchmark datasets show that VeriAct outperforms both prompt-based and prompt-optimized baselines, producing specifications that are not only verifiable but also correct and complete.
Bridging the Gap: Empowering Small Models in Reliable OpenACC-based Parallelization via GEPA-Optimized Prompting
Jan 12, 2026OpenACC lowers the barrier to GPU offloading, but writing high-performing pragma remains complex, requiring deep domain expertise in memory hierarchies, data movement, and parallelization strategies. Large Language Models (LLMs) present a promising potential solution for automated parallel code generation, but naive prompting often results in syntactically incorrect directives, uncompilable code, or performance that fails to exceed CPU baselines. We present a systematic prompt optimization approach to enhance OpenACC pragma generation without the prohibitive computational costs associated with model post-training. Leveraging the GEPA (GEnetic-PAreto) framework, we iteratively evolve prompts through a reflective feedback loop. This process utilizes crossover and mutation of instructions, guided by expert-curated gold examples and structured feedback based on clause- and clause parameter-level mismatches between the gold and predicted pragma. In our evaluation on the PolyBench suite, we observe an increase in compilation success rates for programs annotated with OpenACC pragma generated using the optimized prompts compared to those annotated using the simpler initial prompt, particularly for the "nano"-scale models. Specifically, with optimized prompts, the compilation success rate for GPT-4.1 Nano surged from 66.7% to 93.3%, and for GPT-5 Nano improved from 86.7% to 100%, matching or surpassing the capabilities of their significantly larger, more expensive versions. Beyond compilation, the optimized prompts resulted in a 21% increase in the number of programs that achieve functional GPU speedups over CPU baselines. These results demonstrate that prompt optimization effectively unlocks the potential of smaller, cheaper LLMs in writing stable and effective GPU-offloading directives, establishing a cost-effective pathway to automated directive-based parallelization in HPC workflows.
Memorization: A Close Look at Books
Apr 17, 2025



To what extent can entire books be extracted from LLMs? Using the Llama 3 70B family of models, and the "prefix-prompting" extraction technique, we were able to auto-regressively reconstruct, with a very high level of similarity, one entire book (Alice's Adventures in Wonderland) from just the first 500 tokens. We were also able to obtain high extraction rates on several other books, piece-wise. However, these successes do not extend uniformly to all books. We show that extraction rates of books correlate with book popularity and thus, likely duplication in the training data. We also confirm the undoing of mitigations in the instruction-tuned Llama 3.1, following recent work (Nasr et al., 2025). We further find that this undoing comes from changes to only a tiny fraction of weights concentrated primarily in the lower transformer blocks. Our results provide evidence of the limits of current regurgitation mitigation strategies and introduce a framework for studying how fine-tuning affects the retrieval of verbatim memorization in aligned LLMs.
Information Design in Crowdfunding under Thresholding Policies
Mar 28, 2018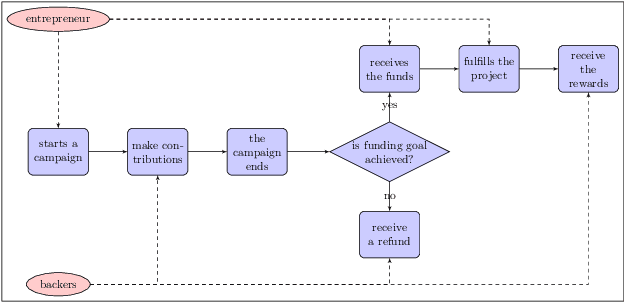
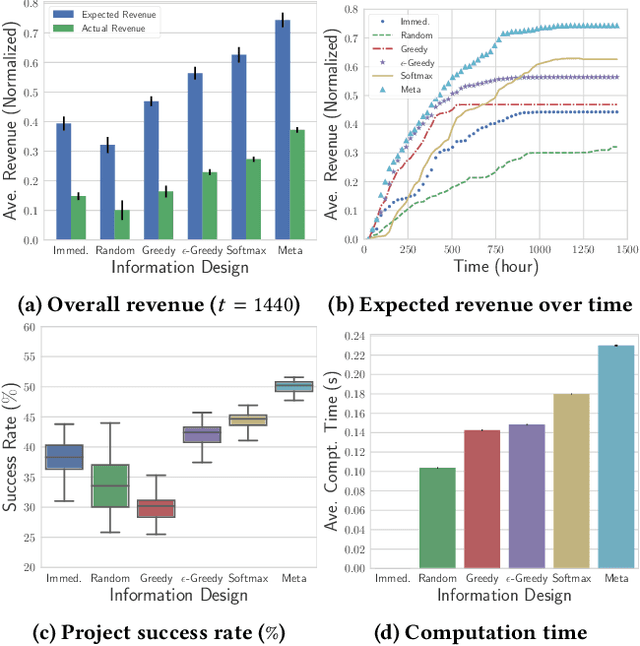
Crowdfunding has emerged as a prominent way for entrepreneurs to secure funding without sophisticated intermediation. In crowdfunding, an entrepreneur often has to decide how to disclose the campaign status in order to collect as many contributions as possible. Such decisions are difficult to make primarily due to incomplete information. We propose information design as a tool to help the entrepreneur to improve revenue by influencing backers' beliefs. We introduce a heuristic algorithm to dynamically compute information-disclosure policies for the entrepreneur, followed by an empirical evaluation to demonstrate its competitiveness over the widely-adopted immediate-disclosure policy. Our results demonstrate that the immediate-disclosure policy is not optimal when backers follow thresholding policies despite its ease of implementation. With appropriate heuristics, an entrepreneur can benefit from dynamic information disclosure. Our work sheds light on information design in a dynamic setting where agents make decisions using thresholding policies.
An Online Mechanism for Ridesharing in Autonomous Mobility-on-Demand Systems
Mar 02, 2017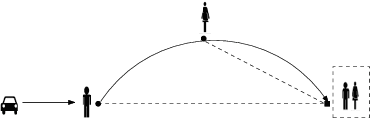
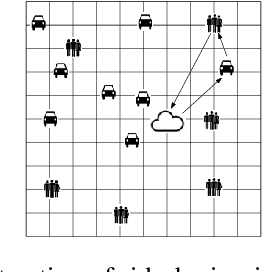
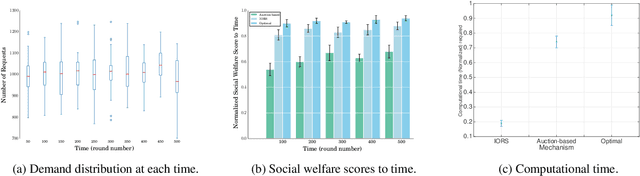
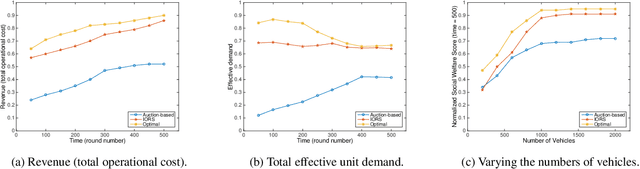
With proper management, Autonomous Mobility-on-Demand (AMoD) systems have great potential to satisfy the transport demands of urban populations by providing safe, convenient, and affordable ridesharing services. Meanwhile, such systems can substantially decrease private car ownership and use, and thus significantly reduce traffic congestion, energy consumption, and carbon emissions. To achieve this objective, an AMoD system requires private information about the demand from passengers. However, due to self-interestedness, passengers are unlikely to cooperate with the service providers in this regard. Therefore, an online mechanism is desirable if it incentivizes passengers to truthfully report their actual demand. For the purpose of promoting ridesharing, we hereby introduce a posted-price, integrated online ridesharing mechanism (IORS) that satisfies desirable properties such as ex-post incentive compatibility, individual rationality, and budget-balance. Numerical results indicate the competitiveness of IORS compared with two benchmarks, namely the optimal assignment and an offline, auction-based mechanism.