 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARPA: A Testability-Driven, Literature-Grounded Framework for Research Ideation
Oct 01, 2025While there has been a surge of interest in automated scientific discovery (ASD), especially with the emergence of LLMs, it remains challenging for tools to generate hypotheses that are both testable and grounded in the scientific literature. Additionally, existing ideation tools are not adaptive to prior experimental outcomes. We developed HARPA to address these challenges by incorporating the ideation workflow inspired by human researchers. HARPA first identifies emerging research trends through literature mining, then explores hypothesis design spaces, and finally converges on precise, testable hypotheses by pinpointing research gaps and justifying design choices. Our evaluations show that HARPA-generated hypothesis-driven research proposals perform comparably to a strong baseline AI-researcher across most qualitative dimensions (e.g., specificity, novelty, overall quality), but achieve significant gains in feasibility(+0.78, p$<0.05$, bootstrap) and groundedness (+0.85, p$<0.01$, bootstrap) on a 10-point Likert scale. When tested with the ASD agent (CodeScientist), HARPA produced more successful executions (20 vs. 11 out of 40) and fewer failures (16 vs. 21 out of 40), showing that expert feasibility judgments track with actual execution success. Furthermore, to simulate how researchers continuously refine their understanding of what hypotheses are both testable and potentially interesting from experience, HARPA learns a reward model that scores new hypotheses based on prior experimental outcomes, achieving approx. a 28\% absolute gain over HARPA's untrained baseline scorer. Together, these methods represent a step forward in the field of AI-driven scientific discovery.
HypER: Literature-grounded Hypothesis Generation and Distillation with Provenance
Jun 15, 2025



Large Language models have demonstrated promising performance in research ideation across scientific domains. Hypothesis development, the process of generating a highly specific declarative statement connecting a research idea with empirical validation, has received relatively less attention. Existing approaches trivially deploy retrieval augmentation and focus only on the quality of the final output ignoring the underlying reasoning process behind ideation. We present $\texttt{HypER}$ ($\textbf{Hyp}$othesis Generation with $\textbf{E}$xplanation and $\textbf{R}$easoning), a small language model (SLM) trained for literature-guided reasoning and evidence-based hypothesis generation. $\texttt{HypER}$ is trained in a multi-task setting to discriminate between valid and invalid scientific reasoning chains in presence of controlled distractions. We find that $\texttt{HypER}$ outperformes the base model, distinguishing valid from invalid reasoning chains (+22\% average absolute F1), generates better evidence-grounded hypotheses (0.327 vs. 0.305 base model) with high feasibility and impact as judged by human experts ($>$3.5 on 5-point Likert scale).
Adaptive political surveys and GPT-4: Tackling the cold start problem with simulated user interactions
Mar 12, 2025



Adaptive questionnaires dynamically select the next question for a survey participant based on their previous answers. Due to digitalisation, they have become a viable alternative to traditional surveys in application areas such as political science. One limitation, however, is their dependency on data to train the model for question selection. Often, such training data (i.e., user interactions) are unavailable a priori. To address this problem, we (i) test whether Large Language Models (LLM) can accurately generate such interaction data and (ii) explore if these synthetic data can be used to pre-train the statistical model of an adaptive political survey. To evaluate this approach, we utilise existing data from the Swiss Voting Advice Application (VAA) Smartvote in two ways: First, we compare the distribution of LLM-generated synthetic data to the real distribution to assess its similarity. Second, we compare the performance of an adaptive questionnaire that is randomly initialised with one pre-trained on synthetic data to assess their suitability for training. We benchmark these results against an "oracle" questionnaire with perfect prior knowledge. We find that an off-the-shelf LLM (GPT-4) accurately generates answers to the Smartvote questionnaire from the perspective of different Swiss parties. Furthermore, we demonstrate that initialising the statistical model with synthetic data can (i) significantly reduce the error in predicting user responses and (ii) increase the candidate recommendation accuracy of the VAA. Our work emphasises the considerable potential of LLMs to create training data to improve the data collection process in adaptive questionnaires in LLM-affine areas such as political surveys.
Fast and Adaptive Questionnaires for Voting Advice Applications
Apr 02, 2024



The effectiveness of Voting Advice Applications (VAA) is often compromised by the length of their questionnaires. To address user fatigue and incomplete responses, some applications (such as the Swiss Smartvote) offer a condensed version of their questionnaire. However, these condensed versions can not ensure the accuracy of recommended parties or candidates, which we show to remain below 40%. To tackle these limitations, this work introduces an adaptive questionnaire approach that selects subsequent questions based on users' previous answers, aiming to enhance recommendation accuracy while reducing the number of questions posed to the voters. Our method uses an encoder and decoder module to predict missing values at any completion stage, leveraging a two-dimensional latent space reflective of political science's traditional methods for visualizing political orientations. Additionally, a selector module is proposed to determine the most informative subsequent question based on the voter's current position in the latent space and the remaining unanswered questions. We validated our approach using the Smartvote dataset from the Swiss Federal elections in 2019, testing various spatial models and selection methods to optimize the system's predictive accuracy. Our findings indicate that employing the IDEAL model both as encoder and decoder, combined with a PosteriorRMSE method for question selection, significantly improves the accuracy of recommendations, achieving 74% accuracy after asking the same number of questions as in the condensed version.
Implementations in Machine Ethics: A Survey
Jan 21, 2020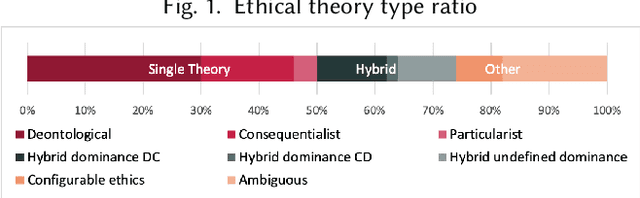
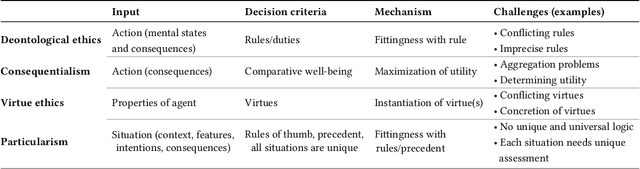
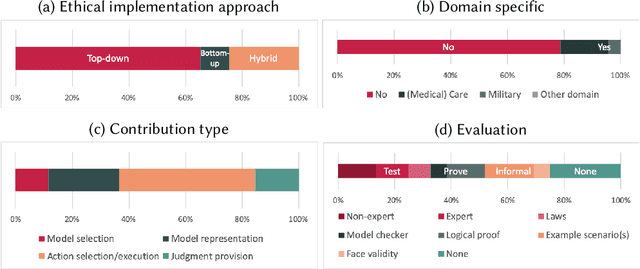
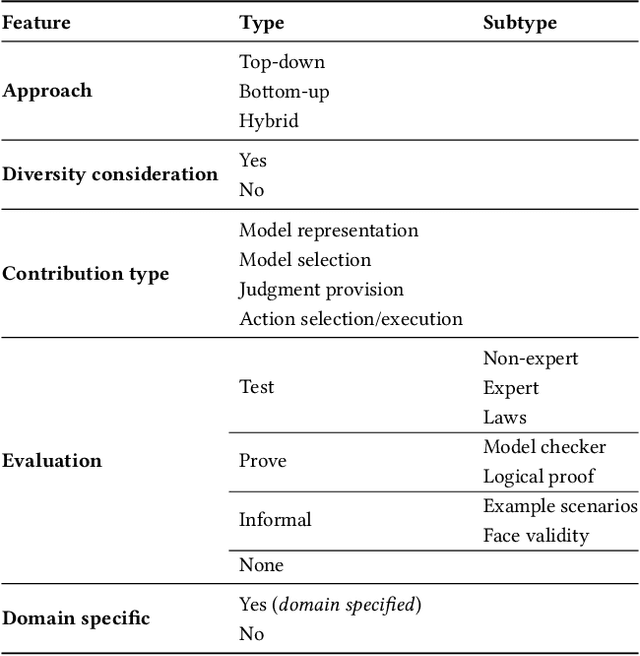
Increasingly complex and autonomous systems require machine ethics to maximize the benefits and minimize the risks to society arising from the new technology. It is challenging to decide which type of ethical theory to employ and how to implement it effectively. This survey provides a threefold contribution. Firstly, it introduces a taxonomy to analyze the field of machine ethics from an ethical, implementational, and technical perspective. Secondly, an exhaustive selection and description of relevant works is presented. Thirdly, applying the new taxonomy to the selected works, dominant research patterns and lessons for the field are identified, and future directions for research are suggested.