 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Deep Q-learning methods robust to time discretization
Jan 29, 2019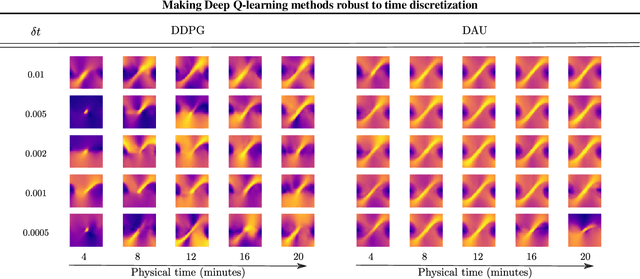
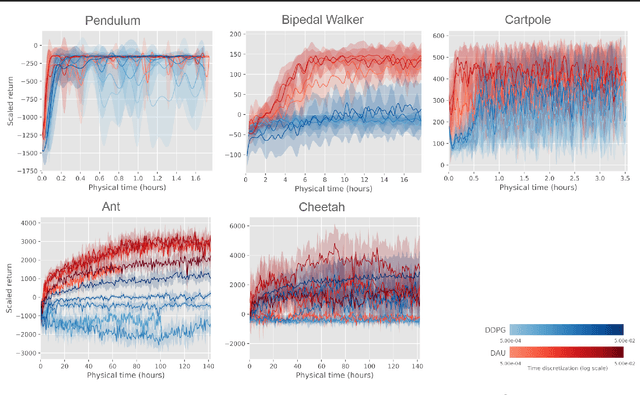
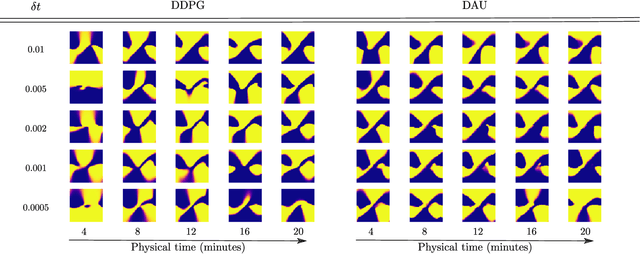
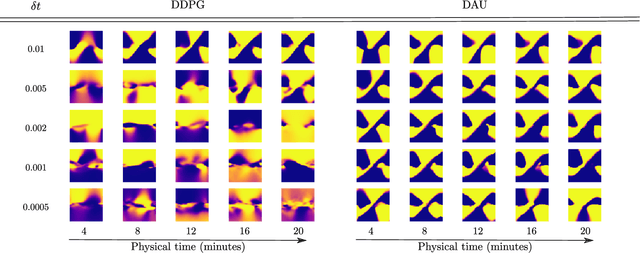
Despite remarkable successes, Deep Reinforcement Learning (DRL) is not robust to hyperparameterization, implementation details, or small environment changes (Henderson et al. 2017, Zhang et al. 2018). Overcoming such sensitivity is key to making DRL applicable to real world problems. In this paper, we identify sensitivity to time discretization in near continuous-time environments as a critical factor; this covers, e.g., changing the number of frames per second, or the action frequency of the controller. Empirically, we find that Q-learning-based approaches such as Deep Q- learning (Mnih et al., 2015) and Deep Deterministic Policy Gradient (Lillicrap et al., 2015) collapse with small time steps. Formally, we prove that Q-learning does not exist in continuous time. We detail a principled way to build an off-policy RL algorithm that yields similar performances over a wide range of time discretizations, and confirm this robustness empirically.
Mixed batches and symmetric discriminators for GAN training
Jun 19, 2018

Generative adversarial networks (GANs) are pow- erful generative models based on providing feed- back to a generative network via a discriminator network. However, the discriminator usually as- sesses individual samples. This prevents the dis- criminator from accessing global distributional statistics of generated samples, and often leads to mode dropping: the generator models only part of the target distribution. We propose to feed the discriminator with mixed batches of true and fake samples, and train it to predict the ratio of true samples in the batch. The latter score does not depend on the order of samples in a batch. Rather than learning this invariance, we introduce a generic permutation-invariant discriminator ar- chitecture. This architecture is provably a uni- versal approximator of all symmetric functions. Experimentally, our approach reduces mode col- lapse in GANs on two synthetic datasets, and obtains good results on the CIFAR10 and CelebA datasets, both qualitatively and quantitatively.
Can recurrent neural networks warp time?
Mar 23, 2018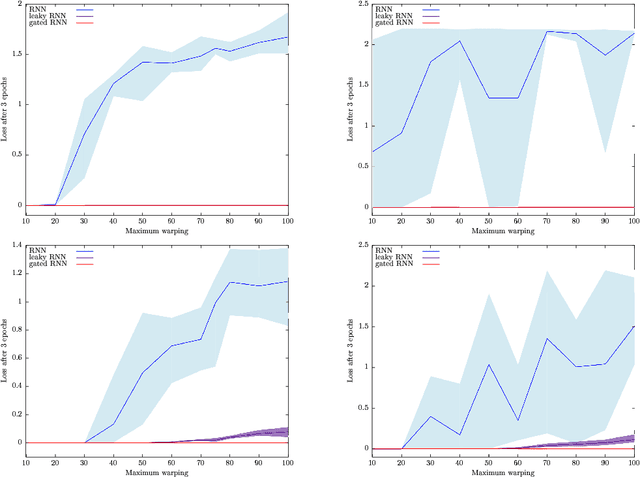
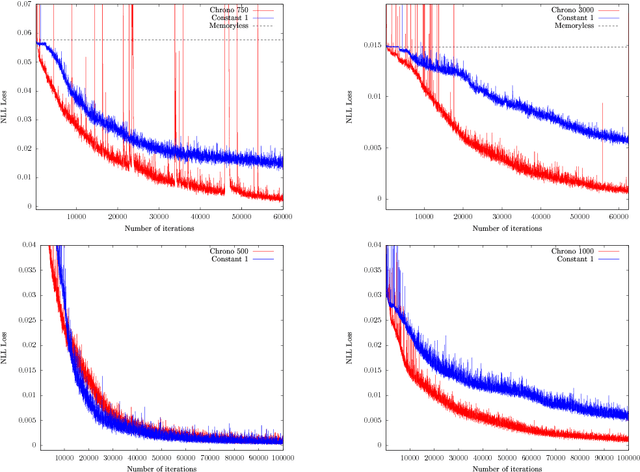
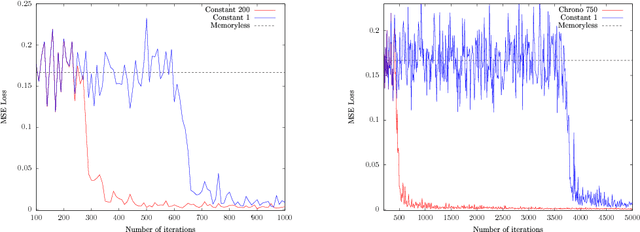
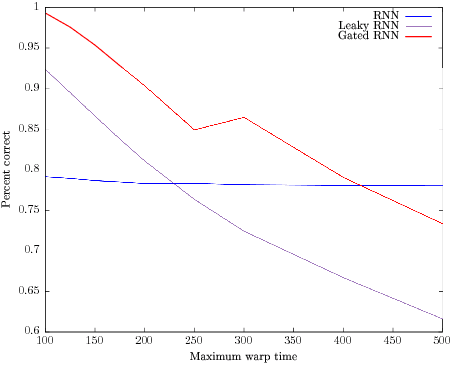
Successful recurrent models such as long short-term memories (LSTMs) and gated recurrent units (GRUs) use ad hoc gating mechanisms. Empirically these models have been found to improve the learning of medium to long term temporal dependencies and to help with vanishing gradient issues. We prove that learnable gates in a recurrent model formally provide quasi- invariance to general time transformations in the input data. We recover part of the LSTM architecture from a simple axiomatic approach. This result leads to a new way of initializing gate biases in LSTMs and GRUs. Ex- perimentally, this new chrono initialization is shown to greatly improve learning of long term dependencies, with minimal implementation effort.
Unbiasing Truncated Backpropagation Through Time
May 23, 2017
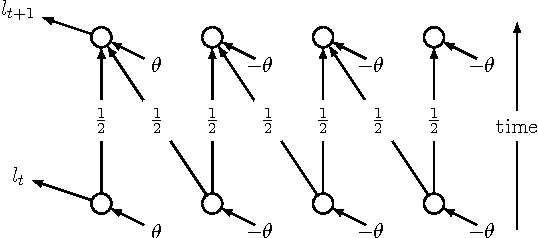
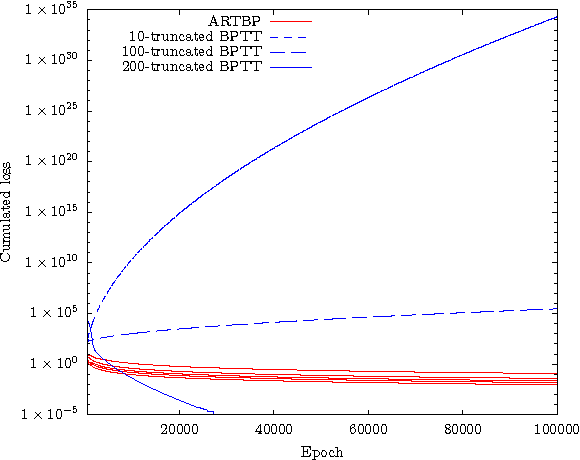
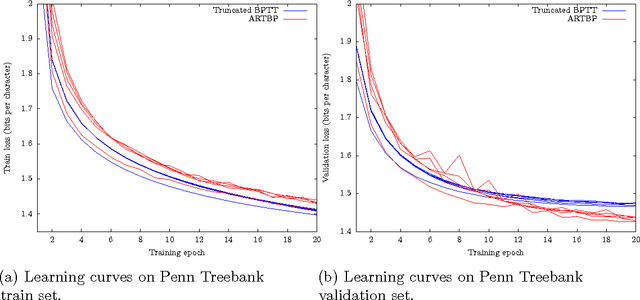
Truncated Backpropagation Through Time (truncated BPTT) is a widespread method for learning recurrent computational graphs. Truncated BPTT keeps the computational benefits of Backpropagation Through Time (BPTT) while relieving the need for a complete backtrack through the whole data sequence at every step. However, truncation favors short-term dependencies: the gradient estimate of truncated BPTT is biased, so that it does not benefit from the convergence guarantees from stochastic gradient theory. We introduce Anticipated Reweighted Truncated Backpropagation (ARTBP), an algorithm that keeps the computational benefits of truncated BPTT, while providing unbiasedness. ARTBP works by using variable truncation lengths together with carefully chosen compensation factors in the backpropagation equation. We check the viability of ARTBP on two tasks. First, a simple synthetic task where careful balancing of temporal dependencies at different scales is needed: truncated BPTT displays unreliable performance, and in worst case scenarios, divergence, while ARTBP converges reliably. Second, on Penn Treebank character-level language modelling, ARTBP slightly outperforms truncated BPTT.
Unbiased Online Recurrent Optimization
May 23, 2017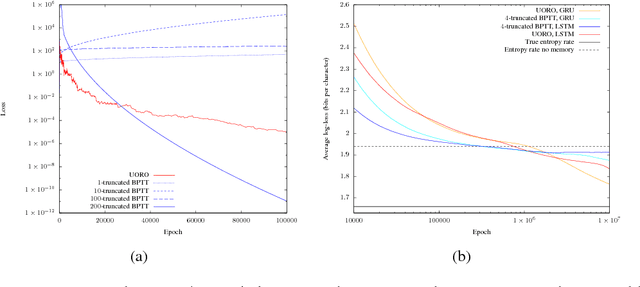

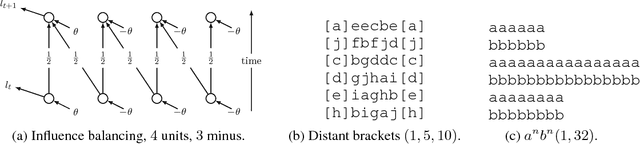
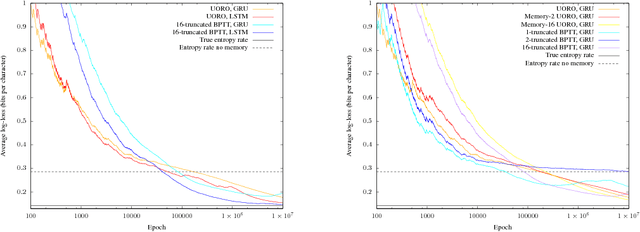
The novel Unbiased Online Recurrent Optimization (UORO) algorithm allows for online learning of general recurrent computational graphs such as recurrent network models. It works in a streaming fashion and avoids backtracking through past activations and inputs. UORO is computationally as costly as Truncated Backpropagation Through Time (truncated BPTT), a widespread algorithm for online learning of recurrent networks. UORO is a modification of NoBackTrack that bypasses the need for model sparsity and makes implementation easy in current deep learning frameworks, even for complex models. Like NoBackTrack, UORO provides unbiased gradient estimates; unbiasedness is the core hypothesis in stochastic gradient descent theory, without which convergence to a local optimum is not guaranteed. On the contrary, truncated BPTT does not provide this property, leading to possible divergence. On synthetic tasks where truncated BPTT is shown to diverge, UORO converges. For instance, when a parameter has a positive short-term but negative long-term influence, truncated BPTT diverges unless the truncation span is very significantly longer than the intrinsic temporal range of the interactions, while UORO performs well thanks to the unbiasedness of its gradients.
Training recurrent networks online without backtracking
Nov 20, 2015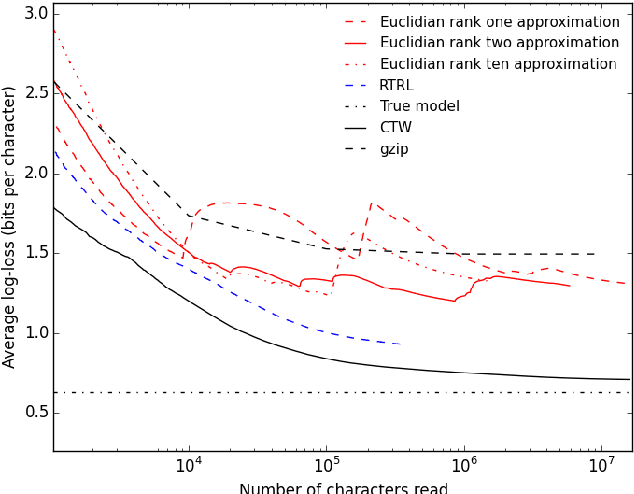
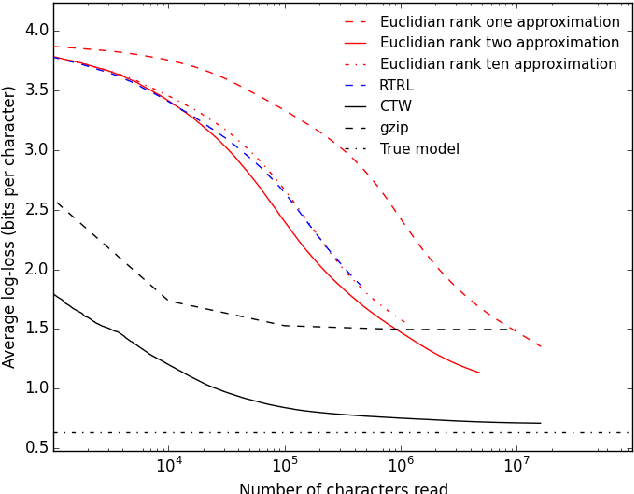
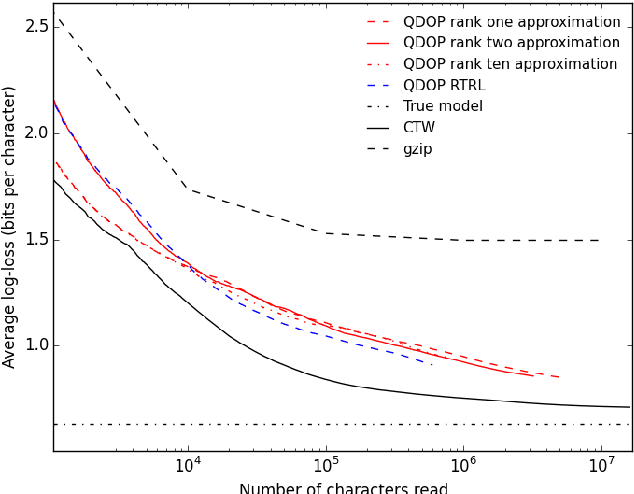
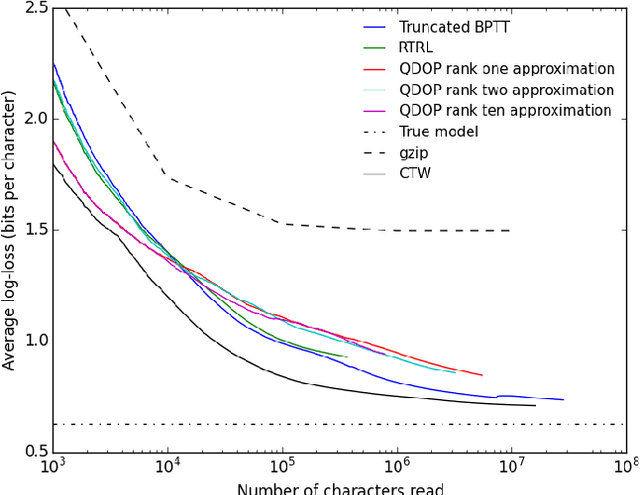
We introduce the "NoBackTrack" algorithm to train the parameters of dynamical systems such as recurrent neural networks. This algorithm works in an online, memoryless setting, thus requiring no backpropagation through time, and is scalable, avoiding the large computational and memory cost of maintaining the full gradient of the current state with respect to the parameters. The algorithm essentially maintains, at each time, a single search direction in parameter space. The evolution of this search direction is partly stochastic and is constructed in such a way to provide, at every time, an unbiased random estimate of the gradient of the loss function with respect to the parameters. Because the gradient estimate is unbiased, on average over time the parameter is updated as it should. The resulting gradient estimate can then be fed to a lightweight Kalman-like filter to yield an improved algorithm. For recurrent neural networks, the resulting algorithms scale linearly with the number of parameters. Small-scale experiments confirm the suitability of the approach, showing that the stochastic approximation of the gradient introduced in the algorithm is not detrimental to learning. In particular, the Kalman-like version of NoBackTrack is superior to backpropagation through time (BPTT) when the time span of dependencies in the data is longer than the truncation span for BPTT.