 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplication in Multimodal LLMs: Computation with Text, Image, and Audio Inputs
Apr 20, 2026Multimodal LLMs can accurately perceive numerical content across modalities yet fail to perform exact multi-digit multiplication when the identical underlying arithmetic problem is presented as numerals, number words, images, or in audio form. Because existing benchmarks often lack systematically paired instances across modalities, it remains difficult to compare genuine arithmetic limits within and across model families. We therefore introduce a controlled multimodal multiplication benchmark that factorially varies digit length, digit sparsity, representation (e.g., numerals vs. number words), and modality (text, rendered images, audio), with paired instances from a reproducible generator. We also define arithmetic load, C, as the product of the total and non-zero digit count as a compact, mechanistically motivated proxy for operation count. Across evaluations, accuracy falls sharply as C grows, often nearing zero by C > 100. Indeed, C remains predictive of performance across modalities and models, with R-squared often > 0.5, nearing the value from more complex measures of arithmetic load that count the number of intermediate arithmetic steps. A separate perception-versus-computation decomposition shows that multimodal degradation is primarily computational rather than perceptual: on matched-perception checks, models are near-perfect (> 99%) across modalities, even when multiplication accuracy drops. Beyond measuring when models fail, we ask which procedures they are predisposed to follow. We introduce a forced-completion loss probe that scores heuristic-specific reasoning prefixes--including columnar multiplication, distributive decomposition, and rounding/compensation. Here, decomposition is favored in both text and vision modalities; heuristic-specific LoRA adapters produce near-orthogonal updates yet degrade accuracy, indicating the base model maintains a well-tuned internal router.
Detecting and Mitigating Treatment Leakage in Text-Based Causal Inference: Distillation and Sensitivity Analysis
Dec 30, 2025Text-based causal inference increasingly employs textual data as proxies for unobserved confounders, yet this approach introduces a previously undertheorized source of bias: treatment leakage. Treatment leakage occurs when text intended to capture confounding information also contains signals predictive of treatment status, thereby inducing post-treatment bias in causal estimates. Critically, this problem can arise even when documents precede treatment assignment, as authors may employ future-referencing language that anticipates subsequent interventions. Despite growing recognition of this issue, no systematic methods exist for identifying and mitigating treatment leakage in text-as-confounder applications. This paper addresses this gap through three contributions. First, we provide formal statistical and set-theoretic definitions of treatment leakage that clarify when and why bias occurs. Second, we propose four text distillation methods -- similarity-based passage removal, distant supervision classification, salient feature removal, and iterative nullspace projection -- designed to eliminate treatment-predictive content while preserving confounder information. Third, we validate these methods through simulations using synthetic text and an empirical application examining International Monetary Fund structural adjustment programs and child mortality. Our findings indicate that moderate distillation optimally balances bias reduction against confounder retention, whereas overly stringent approaches degrade estimate precision.
Benchmarking Debiasing Methods for LLM-based Parameter Estimates
Jun 11, 2025Large language models (LLMs) offer an inexpensive yet powerful way to annotate text, but are often inconsistent when compared with experts. These errors can bias downstream estimates of population parameters such as regression coefficients and causal effects. To mitigate this bias, researchers have developed debiasing methods such as Design-based Supervised Learning (DSL) and Prediction-Powered Inference (PPI), which promise valid estimation by combining LLM annotations with a limited number of expensive expert annotations. Although these methods produce consistent estimates under theoretical assumptions, it is unknown how they compare in finite samples of sizes encountered in applied research. We make two contributions: First, we study how each method's performance scales with the number of expert annotations, highlighting regimes where LLM bias or limited expert labels significantly affect results. Second, we compare DSL and PPI across a range of tasks, finding that although both achieve low bias with large datasets, DSL often outperforms PPI on bias reduction and empirical efficiency, but its performance is less consistent across datasets. Our findings indicate that there is a bias-variance tradeoff at the level of debiasing methods, calling for more research on developing metrics for quantifying their efficiency in finite samples.
Encoding Multi-level Dynamics in Effect Heterogeneity Estimation
Nov 04, 2024



Earth Observation (EO) data are increasingly used in policy analysis by enabling granular estimation of treatment effects. However, a challenge in EO-based causal inference lies in balancing the trade-off between capturing fine-grained individual heterogeneity and broader contextual information. This paper introduces Multi-scale Concatenation, a family of composable procedures that transform arbitrary single-scale CATE estimation algorithms into multi-scale algorithms. We benchmark the performance of Multi-scale Concatenation on a CATE estimation pipeline combining Vision Transformer (ViT) models fine-tuned on satellite images to encode images of different scales with Causal Forests to obtain the final CATE estimate. We first perform simulation studies, showing how a multi-scale approach captures multi-level dynamics that single-scale ViT models fail to capture. We then apply the multi-scale method to two randomized controlled trials (RCTs) conducted in Peru and Uganda using Landsat satellite imagery. In the RCT analysis, the Rank Average Treatment Effect Ratio (RATE Ratio) measure is employed to assess performance without ground truth individual treatment effects. Results indicate that Multi-scale Concatenation improves the performance of deep learning models in EO-based CATE estimation without the complexity of designing new multi-scale architectures for a specific use case.
Planetary Causal Inference: Implications for the Geography of Poverty
May 30, 2024Earth observation data such as satellite imagery can, when combined with machine learning, have profound impacts on our understanding of the geography of poverty through the prediction of living conditions, especially where government-derived economic indicators are either unavailable or potentially untrustworthy. Recent work has progressed in using EO data not only to predict spatial economic outcomes, but also to explore cause and effect, an understanding which is critical for downstream policy analysis. In this review, we first document the growth of interest in EO-ML analyses in the causal space. We then trace the relationship between spatial statistics and EO-ML methods before discussing the four ways in which EO data has been used in causal ML pipelines -- (1.) poverty outcome imputation for downstream causal analysis, (2.) EO image deconfounding, (3.) EO-based treatment effect heterogeneity, and (4.) EO-based transportability analysis. We conclude by providing a workflow for how researchers can incorporate EO data in causal ML analysis going forward.
CausalImages: An R Package for Causal Inference with Earth Observation, Bio-medical, and Social Science Images
Oct 03, 2023



The causalimages R package enables causal inference with image and image sequence data, providing new tools for integrating novel data sources like satellite and bio-medical imagery into the study of cause and effect. One set of functions enables image-based causal inference analyses. For example, one key function decomposes treatment effect heterogeneity by images using an interpretable Bayesian framework. This allows for determining which types of images or image sequences are most responsive to interventions. A second modeling function allows researchers to control for confounding using images. The package also allows investigators to produce embeddings that serve as vector summaries of the image or video content. Finally, infrastructural functions are also provided, such as tools for writing large-scale image and image sequence data as sequentialized byte strings for more rapid image analysis. causalimages therefore opens new capabilities for causal inference in R, letting researchers use informative imagery in substantive analyses in a fast and accessible manner.
Integrating Earth Observation Data into Causal Inference: Challenges and Opportunities
Jan 30, 2023



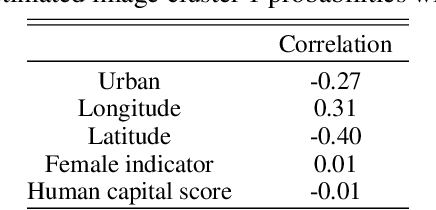
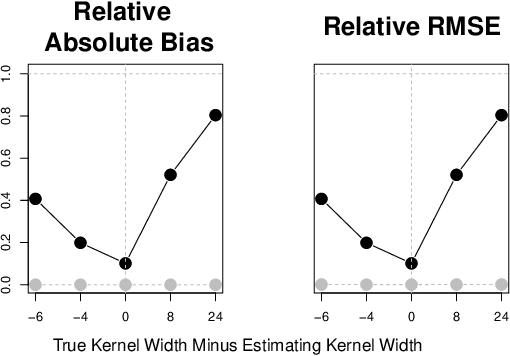
Observational studies require adjustment for confounding factors that are correlated with both the treatment and outcome. In the setting where the observed variables are tabular quantities such as average income in a neighborhood, tools have been developed for addressing such confounding. However, in many parts of the developing world, features about local communities may be scarce. In this context, satellite imagery can play an important role, serving as a proxy for the confounding variables otherwise unobserved. In this paper, we study confounder adjustment in this non-tabular setting, where patterns or objects found in satellite images contribute to the confounder bias. Using the evaluation of anti-poverty aid programs in Africa as our running example, we formalize the challenge of performing causal adjustment with such unstructured data -- what conditions are sufficient to identify causal effects, how to perform estimation, and how to quantify the ways in which certain aspects of the unstructured image object are most predictive of the treatment decision. Via simulation, we also explore the sensitivity of satellite image-based observational inference to image resolution and to misspecification of the image-associated confounder. Finally, we apply these tools in estimating the effect of anti-poverty interventions in African communities from satellite imagery.
Image-based Treatment Effect Heterogeneity
Jun 13, 2022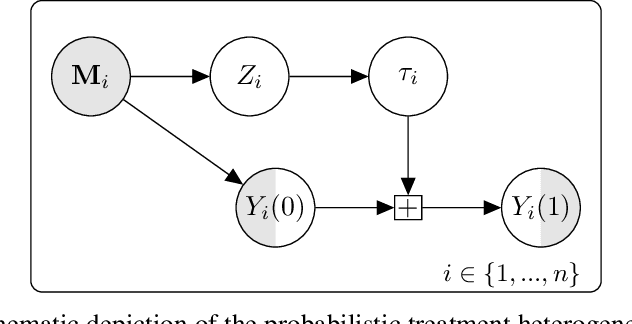
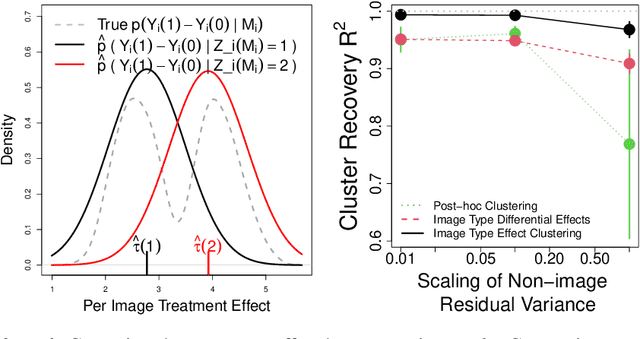
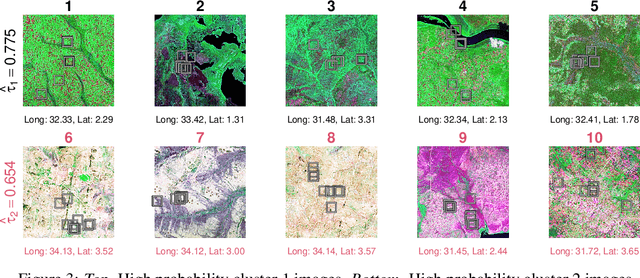
Randomized controlled trials (RCTs) are considered the gold standard for estimating the effects of interventions. Recent work has studied effect heterogeneity in RCTs by conditioning estimates on tabular variables such as age and ethnicity. However, such variables are often only observed near the time of the experiment and may fail to capture historical or geographical reasons for effect variation. When experiment units are associated with a particular location, satellite imagery can provide such historical and geographical information, yet there is no method which incorporates it for describing effect heterogeneity. In this paper, we develop such a method which estimates, using a deep probabilistic modeling framework, the clusters of images having the same distribution over treatment effects. We compare the proposed methods against alternatives in simulation and in an application to estimating the effects of an anti-poverty intervention in Uganda. A causal regularization penalty is introduced to ensure reliability of the cluster model in recovering Average Treatment Effects (ATEs). Finally, we discuss feasibility, limitations, and the applicability of these methods to other domains, such as medicine and climate science, where image information is prevalent. We make code for all modeling strategies publicly available in an open-source software package.
Estimating Causal Effects Under Image Confounding Bias with an Application to Poverty in Africa
Jun 13, 2022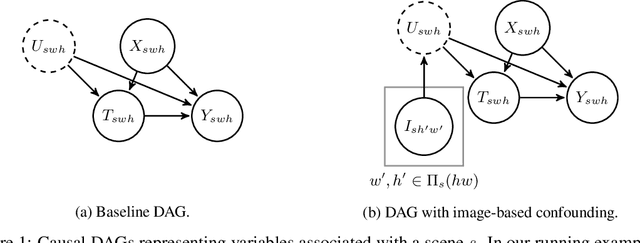

Observational studies of causal effects require adjustment for confounding factors. In the tabular setting, where these factors are well-defined, separate random variables, the effect of confounding is well understood. However, in public policy, ecology, and in medicine, decisions are often made in non-tabular settings, informed by patterns or objects detected in images (e.g., maps, satellite or tomography imagery). Using such imagery for causal inference presents an opportunity because objects in the image may be related to the treatment and outcome of interest. In these cases, we rely on the images to adjust for confounding but observed data do not directly label the existence of the important objects. Motivated by real-world applications, we formalize this challenge, how it can be handled, and what conditions are sufficient to identify and estimate causal effects. We analyze finite-sample performance using simulation experiments, estimating effects using a propensity adjustment algorithm that employs a machine learning model to estimate the image confounding. Our experiments also examine sensitivity to misspecification of the image pattern mechanism. Finally, we use our methodology to estimate the effects of policy interventions on poverty in African communities from satellite imagery.
Conceptualizing Treatment Leakage in Text-based Causal Inference
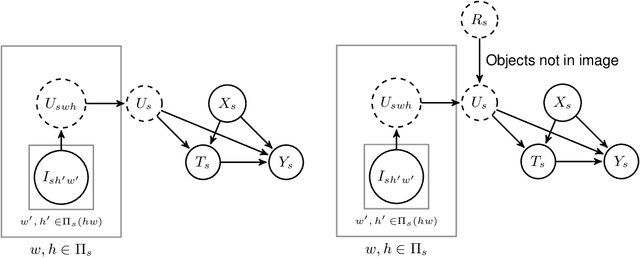
May 01, 2022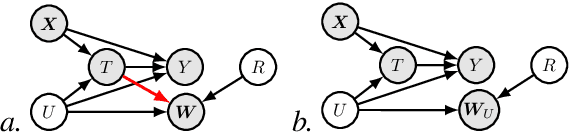
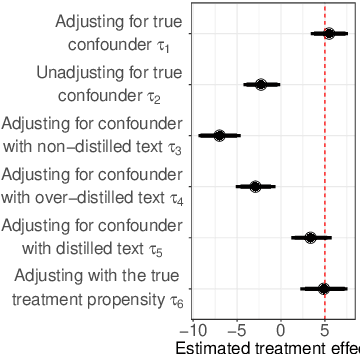
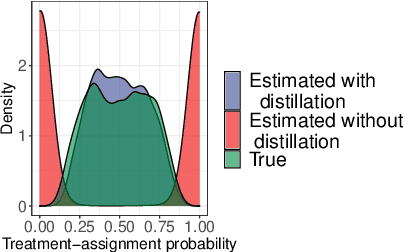
Causal inference methods that control for text-based confounders are becoming increasingly important in the social sciences and other disciplines where text is readily available. However, these methods rely on a critical assumption that there is no treatment leakage: that is, the text only contains information about the confounder and no information about treatment assignment. When this assumption does not hold, methods that control for text to adjust for confounders face the problem of post-treatment (collider) bias. However, the assumption that there is no treatment leakage may be unrealistic in real-world situations involving text, as human language is rich and flexible. Language appearing in a public policy document or health records may refer to the future and the past simultaneously, and thereby reveal information about the treatment assignment. In this article, we define the treatment-leakage problem, and discuss the identification as well as the estimation challenges it raises. Second, we delineate the conditions under which leakage can be addressed by removing the treatment-related signal from the text in a pre-processing step we define as text distillation. Lastly, using simulation, we show how treatment leakage introduces a bias in estimates of the average treatment effect (ATE) and how text distillation can mitigate this bias.