 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Random Fields as an Abstract Representation of Patient Metadata for Multimodal Medical Image Segmentation
Mar 07, 2025The growing rate of chronic wound occurrence, especially in patients with diabetes, has become a concerning trend in recent years. Chronic wounds are difficult and costly to treat, and have become a serious burden on health care systems worldwide. Chronic wounds can have devastating consequences for the patient, with infection often leading to reduced quality of life and increased mortality risk. Innovative deep learning methods for the detection and monitoring of such wounds have the potential to reduce the impact to both patient and clinician. We present a novel multimodal segmentation method which allows for the introduction of patient metadata into the training workflow whereby the patient data are expressed as Gaussian random fields. Our results indicate that the proposed method improved performance when utilising multiple models, each trained on different metadata categories. Using the Diabetic Foot Ulcer Challenge 2022 test set, when compared to the baseline results (intersection over union = 0.4670, Dice similarity coefficient = 0.5908) we demonstrate improvements of +0.0220 and +0.0229 for intersection over union and Dice similarity coefficient respectively. This paper presents the first study to focus on integrating patient data into a chronic wound segmentation workflow. Our results show significant performance gains when training individual models using specific metadata categories, followed by average merging of prediction masks using distance transforms. All source code for this study is available at: https://github.com/mmu-dermatology-research/multimodal-grf
An Enhanced Harmonic Densely Connected Hybrid Transformer Network Architecture for Chronic Wound Segmentation Utilising Multi-Colour Space Tensor Merging
Oct 04, 2024



Chronic wounds and associated complications present ever growing burdens for clinics and hospitals world wide. Venous, arterial, diabetic, and pressure wounds are becoming increasingly common globally. These conditions can result in highly debilitating repercussions for those affected, with limb amputations and increased mortality risk resulting from infection becoming more common. New methods to assist clinicians in chronic wound care are therefore vital to maintain high quality care standards. This paper presents an improved HarDNet segmentation architecture which integrates a contrast-eliminating component in the initial layers of the network to enhance feature learning. We also utilise a multi-colour space tensor merging process and adjust the harmonic shape of the convolution blocks to facilitate these additional features. We train our proposed model using wound images from light-skinned patients and test the model on two test sets (one set with ground truth, and one without) comprising only darker-skinned cases. Subjective ratings are obtained from clinical wound experts with intraclass correlation coefficient used to determine inter-rater reliability. For the dark-skin tone test set with ground truth, we demonstrate improvements in terms of Dice similarity coefficient (+0.1221) and intersection over union (+0.1274). Qualitative analysis showed high expert ratings, with improvements of >3% demonstrated when comparing the baseline model with the proposed model. This paper presents the first study to focus on darker-skin tones for chronic wound segmentation using models trained only on wound images exhibiting lighter skin. Diabetes is highly prevalent in countries where patients have darker skin tones, highlighting the need for a greater focus on such cases. Additionally, we conduct the largest qualitative study to date for chronic wound segmentation.
Dermoscopic Dark Corner Artifacts Removal: Friend or Foe?
Jun 23, 2023



One of the more significant obstacles in classification of skin cancer is the presence of artifacts. This paper investigates the effect of dark corner artifacts, which result from the use of dermoscopes, on the performance of a deep learning binary classification task. Previous research attempted to remove and inpaint dark corner artifacts, with the intention of creating an ideal condition for models. However, such research has been shown to be inconclusive due to lack of available datasets labelled with dark corner artifacts and detailed analysis and discussion. To address these issues, we label 10,250 skin lesion images from publicly available datasets and introduce a balanced dataset with an equal number of melanoma and non-melanoma cases. The training set comprises 6126 images without artifacts, and the testing set comprises 4124 images with dark corner artifacts. We conduct three experiments to provide new understanding on the effects of dark corner artifacts, including inpainted and synthetically generated examples, on a deep learning method. Our results suggest that introducing synthetic dark corner artifacts which have been superimposed onto the training set improved model performance, particularly in terms of the true negative rate. This indicates that deep learning learnt to ignore dark corner artifacts, rather than treating it as melanoma, when dark corner artifacts were introduced into the training set. Further, we propose a new approach to quantifying heatmaps indicating network focus using a root mean square measure of the brightness intensity in the different regions of the heatmaps. This paper provides a new guideline for skin lesions analysis with an emphasis on reproducibility.
Quantifying the Effect of Image Similarity on Diabetic Foot Ulcer Classification
Apr 25, 2023This research conducts an investigation on the effect of visually similar images within a publicly available diabetic foot ulcer dataset when training deep learning classification networks. The presence of binary-identical duplicate images in datasets used to train deep learning algorithms is a well known issue that can introduce unwanted bias which can degrade network performance. However, the effect of visually similar non-identical images is an under-researched topic, and has so far not been investigated in any diabetic foot ulcer studies. We use an open-source fuzzy algorithm to identify groups of increasingly similar images in the Diabetic Foot Ulcers Challenge 2021 (DFUC2021) training dataset. Based on each similarity threshold, we create new training sets that we use to train a range of deep learning multi-class classifiers. We then evaluate the performance of the best performing model on the DFUC2021 test set. Our findings show that the model trained on the training set with the 80\% similarity threshold images removed achieved the best performance using the InceptionResNetV2 network. This model showed improvements in F1-score, precision, and recall of 0.023, 0.029, and 0.013, respectively. These results indicate that highly similar images can contribute towards the presence of performance degrading bias within the Diabetic Foot Ulcers Challenge 2021 dataset, and that the removal of images that are 80\% similar from the training set can help to boost classification performance.
Diabetic Foot Ulcer Grand Challenge 2022 Summary
Apr 24, 2023The Diabetic Foot Ulcer Challenge 2022 focused on the task of diabetic foot ulcer segmentation, based on the work completed in previous DFU challenges. The challenge provided 4000 images of full-view foot ulcer images together with corresponding delineation of ulcer regions. This paper provides an overview of the challenge, a summary of the methods proposed by the challenge participants, the results obtained from each technique, and a comparison of the challenge results. The best-performing network was a modified HarDNet-MSEG, with a Dice score of 0.7287.
Translating Clinical Delineation of Diabetic Foot Ulcers into Machine Interpretable Segmentation
Apr 22, 2022
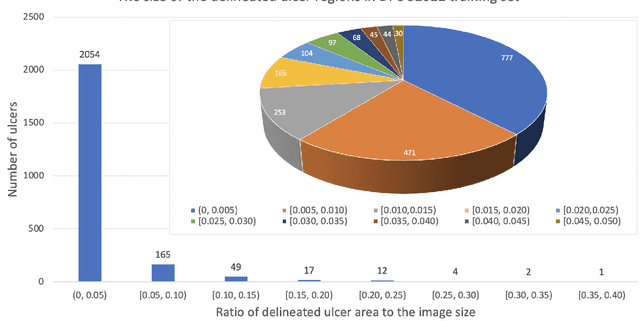
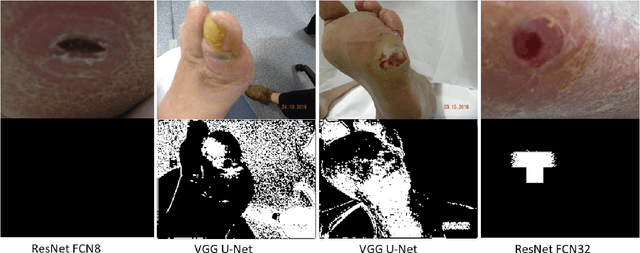
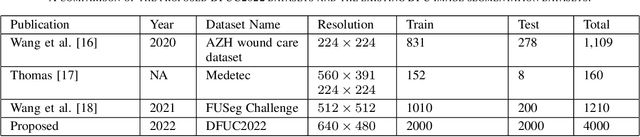
Diabetic foot ulcer is a severe condition that requires close monitoring and management. For training machine learning methods to auto-delineate the ulcer, clinical staff must provide ground truth annotations. In this paper, we propose a new diabetic foot ulcers dataset, namely DFUC2022, the largest segmentation dataset where ulcer regions were manually delineated by clinicians. We assess whether the clinical delineations are machine interpretable by deep learning networks or if image processing refined contour should be used. By providing benchmark results using a selection of popular deep learning algorithms, we draw new insights into the limitations of DFU wound delineation and report on the associated issues. This paper provides some observations on baseline models to facilitate DFUC2022 Challenge in conjunction with MICCAI 2022. The leaderboard will be ranked by Dice score, where the best FCN-based method is 0.5708 and DeepLabv3+ achieved the best score of 0.6277. This paper demonstrates that image processing using refined contour as ground truth can provide better agreement with machine predicted results. DFUC2022 will be released on the 27th April 2022.
V-LinkNet: Learning Contextual Inpainting Across Latent Space of Generative Adversarial Network
Jan 02, 2022
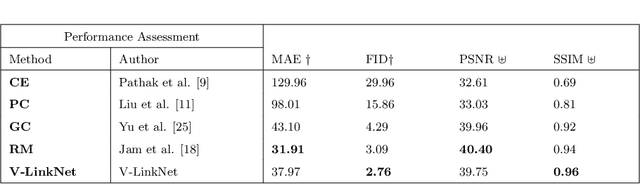

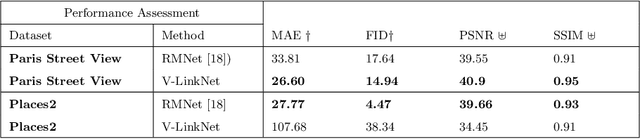
Deep learning methods outperform traditional methods in image inpainting. In order to generate contextual textures, researchers are still working to improve on existing methods and propose models that can extract, propagate, and reconstruct features similar to ground-truth regions. Furthermore, the lack of a high-quality feature transfer mechanism in deeper layers contributes to persistent aberrations on generated inpainted regions. To address these limitations, we propose the V-LinkNet cross-space learning strategy network. To improve learning on contextualised features, we design a loss model that employs both encoders. In addition, we propose a recursive residual transition layer (RSTL). The RSTL extracts high-level semantic information and propagates it down layers. Finally, we compare inpainting performance on the same face with different masks and on different faces with the same masks. To improve image inpainting reproducibility, we propose a standard protocol to overcome biases with various masks and images. We investigate the V-LinkNet components using experimental methods. Our result surpasses the state of the art when evaluated on the CelebA-HQ with the standard protocol. In addition, our model can generalise well when evaluated on Paris Street View, and Places2 datasets with the standard protocol.
Development of Diabetic Foot Ulcer Datasets: An Overview
Jan 01, 2022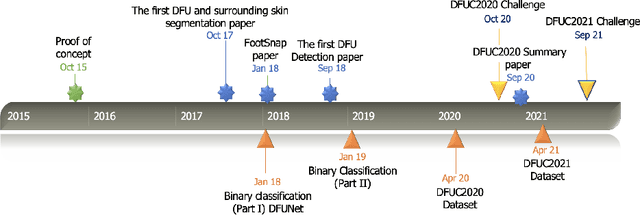
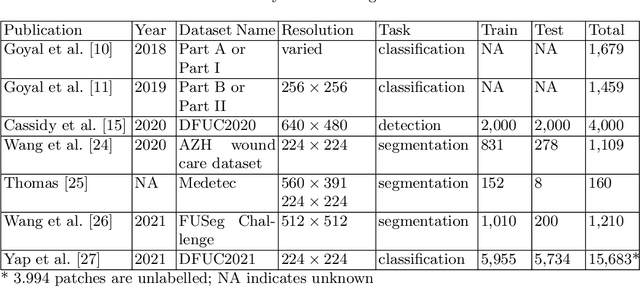
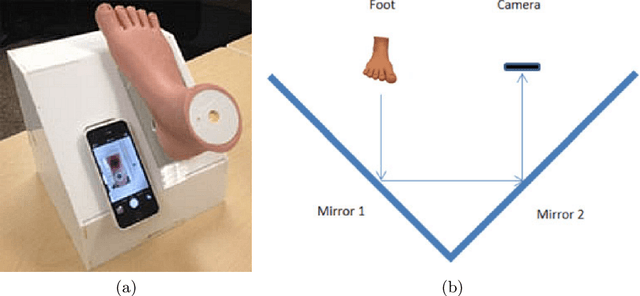
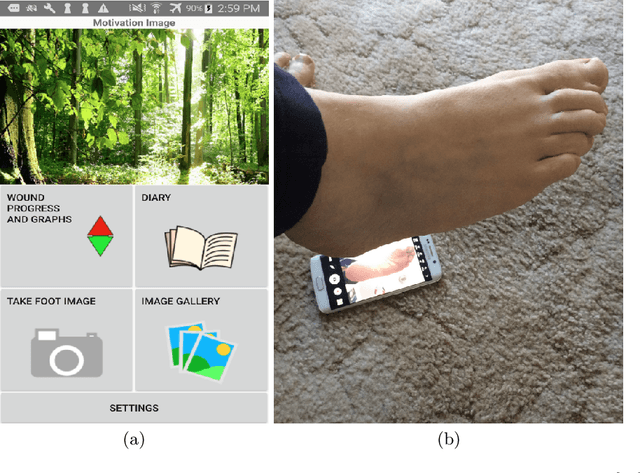
This paper provides conceptual foundation and procedures used in the development of diabetic foot ulcer datasets over the past decade, with a timeline to demonstrate progress. We conduct a survey on data capturing methods for foot photographs, an overview of research in developing private and public datasets, the related computer vision tasks (detection, segmentation and classification), the diabetic foot ulcer challenges and the future direction of the development of the datasets. We report the distribution of dataset users by country and year. Our aim is to share the technical challenges that we encountered together with good practices in dataset development, and provide motivation for other researchers to participate in data sharing in this domain.
Diabetic Foot Ulcer Grand Challenge 2021: Evaluation and Summary
Nov 19, 2021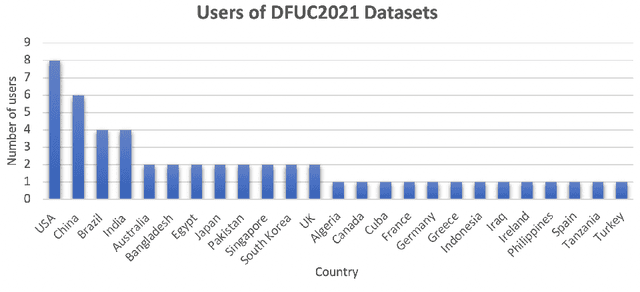

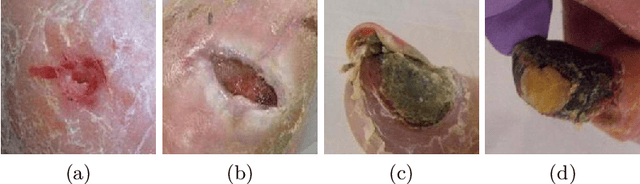
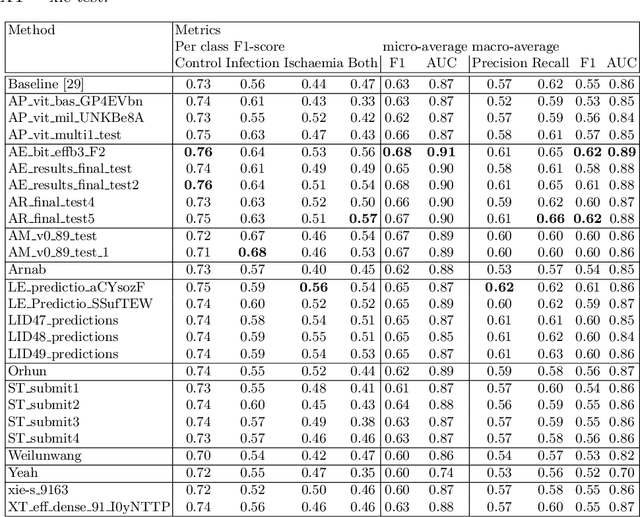
Diabetic foot ulcer classification systems use the presence of wound infection (bacteria present within the wound) and ischaemia (restricted blood supply) as vital clinical indicators for treatment and prediction of wound healing. Studies investigating the use of automated computerised methods of classifying infection and ischaemia within diabetic foot wounds are limited due to a paucity of publicly available datasets and severe data imbalance in those few that exist. The Diabetic Foot Ulcer Challenge 2021 provided participants with a more substantial dataset comprising a total of 15,683 diabetic foot ulcer patches, with 5,955 used for training, 5,734 used for testing and an additional 3,994 unlabelled patches to promote the development of semi-supervised and weakly-supervised deep learning techniques. This paper provides an evaluation of the methods used in the Diabetic Foot Ulcer Challenge 2021, and summarises the results obtained from each network. The best performing network was an ensemble of the results of the top 3 models, with a macro-average F1-score of 0.6307.
Foreground-guided Facial Inpainting with Fidelity Preservation
May 07, 2021
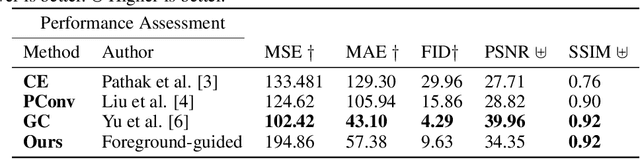
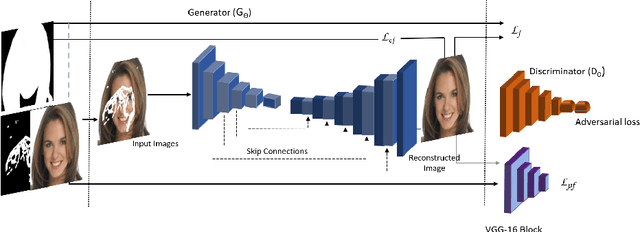
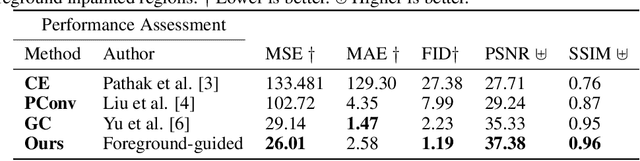
Facial image inpainting, with high-fidelity preservation for image realism, is a very challenging task. This is due to the subtle texture in key facial features (component) that are not easily transferable. Many image inpainting techniques have been proposed with outstanding capabilities and high quantitative performances recorded. However, with facial inpainting, the features are more conspicuous and the visual quality of the blended inpainted regions are more important qualitatively. Based on these facts, we design a foreground-guided facial inpainting framework that can extract and generate facial features using convolutional neural network layers. It introduces the use of foreground segmentation masks to preserve the fidelity. Specifically, we propose a new loss function with semantic capability reasoning of facial expressions, natural and unnatural features (make-up). We conduct our experiments using the CelebA-HQ dataset, segmentation masks from CelebAMask-HQ (for foreground guidance) and Quick Draw Mask (for missing regions). Our proposed method achieved comparable quantitative results when compare to the state of the art but qualitatively, it demonstrated high-fidelity preservation of facial components.