 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching, Learning, and Subtopic Ordering: A Simulation-based Analysis
Jan 26, 2022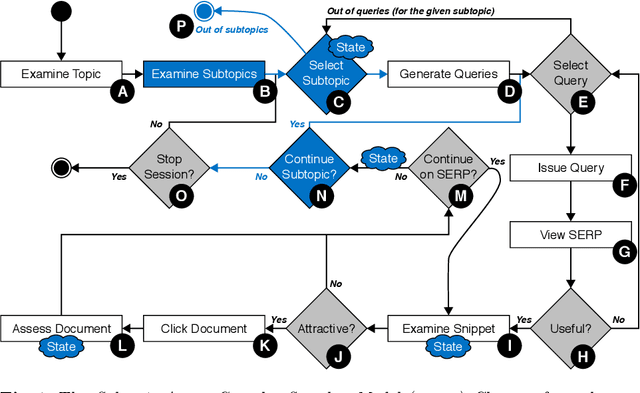

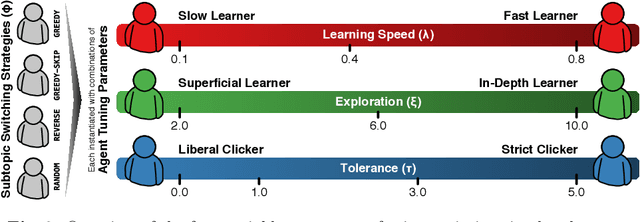
Complex search tasks - such as those from the Search as Learning (SAL) domain - often result in users developing an information need composed of several aspects. However, current models of searcher behaviour assume that individuals have an atomic need, regardless of the task. While these models generally work well for simpler informational needs, we argue that searcher models need to be developed further to allow for the decomposition of a complex search task into multiple aspects. As no searcher model yet exists that considers both aspects and the SAL domain, we propose, by augmenting the Complex Searcher Model (CSM), the Subtopic Aware Complex Searcher Model (SACSM) - modelling aspects as subtopics to the user's need. We then instantiate several agents (i.e., simulated users), with different subtopic selection strategies, which can be considered as different prototypical learning strategies (e.g., should I deeply examine one subtopic at a time, or shallowly cover several subtopics?). Finally, we report on the first large-scale simulated analysis of user behaviours in the SAL domain. Results demonstrate that the SACSM, under certain conditions, simulates user behaviours accurately.
Diagnosing BERT with Retrieval Heuristics
Jan 12, 2022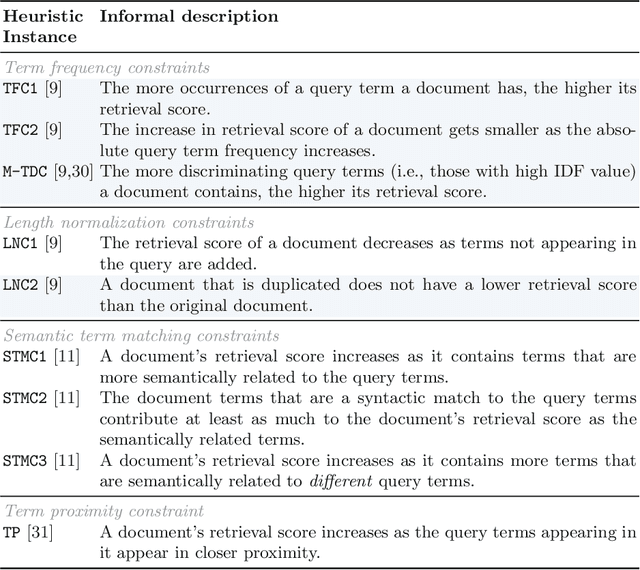
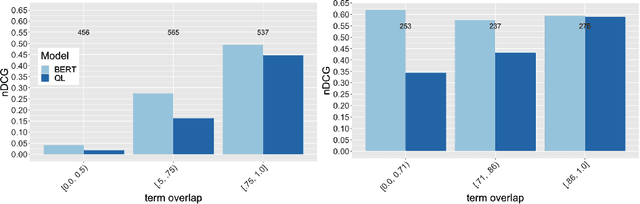


Word embeddings, made widely popular in 2013 with the release of word2vec, have become a mainstay of NLP engineering pipelines. Recently, with the release of BERT, word embeddings have moved from the term-based embedding space to the contextual embedding space -- each term is no longer represented by a single low-dimensional vector but instead each term and \emph{its context} determine the vector weights. BERT's setup and architecture have been shown to be general enough to be applicable to many natural language tasks. Importantly for Information Retrieval (IR), in contrast to prior deep learning solutions to IR problems which required significant tuning of neural net architectures and training regimes, "vanilla BERT" has been shown to outperform existing retrieval algorithms by a wide margin, including on tasks and corpora that have long resisted retrieval effectiveness gains over traditional IR baselines (such as Robust04). In this paper, we employ the recently proposed axiomatic dataset analysis technique -- that is, we create diagnostic datasets that each fulfil a retrieval heuristic (both term matching and semantic-based) -- to explore what BERT is able to learn. In contrast to our expectations, we find BERT, when applied to a recently released large-scale web corpus with ad-hoc topics, to \emph{not} adhere to any of the explored axioms. At the same time, BERT outperforms the traditional query likelihood retrieval model by 40\%. This means that the axiomatic approach to IR (and its extension of diagnostic datasets created for retrieval heuristics) may in its current form not be applicable to large-scale corpora. Additional -- different -- axioms are needed.
* Published at ECIR 2020
Evaluating the Robustness of Retrieval Pipelines with Query Variation Generators
Nov 29, 2021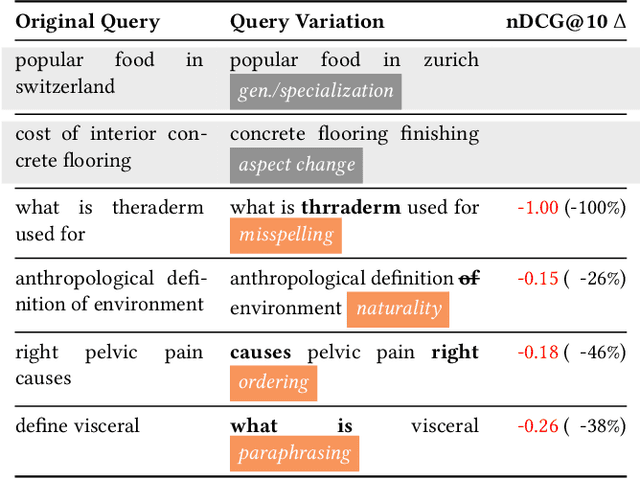
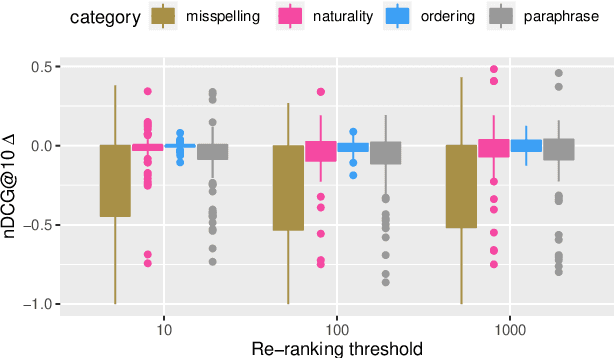
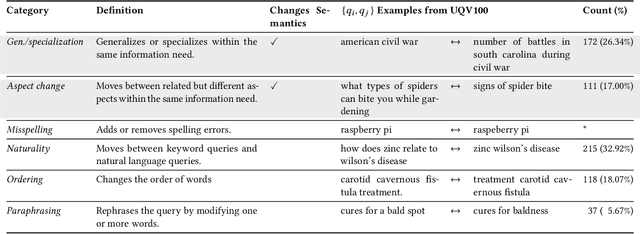
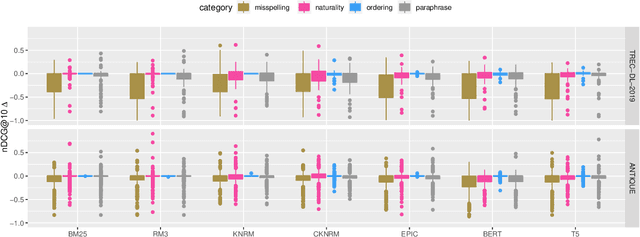
Heavily pre-trained transformers for language modelling, such as BERT, have shown to be remarkably effective for Information Retrieval (IR) tasks, typically applied to re-rank the results of a first-stage retrieval model. IR benchmarks evaluate the effectiveness of retrieval pipelines based on the premise that a single query is used to instantiate the underlying information need. However, previous research has shown that (I) queries generated by users for a fixed information need are extremely variable and, in particular, (II) neural models are brittle and often make mistakes when tested with modified inputs. Motivated by those observations we aim to answer the following question: how robust are retrieval pipelines with respect to different variations in queries that do not change the queries' semantics? In order to obtain queries that are representative of users' querying variability, we first created a taxonomy based on the manual annotation of transformations occurring in a dataset (UQV100) of user-created query variations. For each syntax-changing category of our taxonomy, we employed different automatic methods that when applied to a query generate a query variation. Our experimental results across two datasets for two IR tasks reveal that retrieval pipelines are not robust to these query variations, with effectiveness drops of $\approx20\%$ on average. The code and datasets are available at https://github.com/Guzpenha/query_variation_generators.
Searching to Learn with Instructional Scaffolding
Nov 29, 2021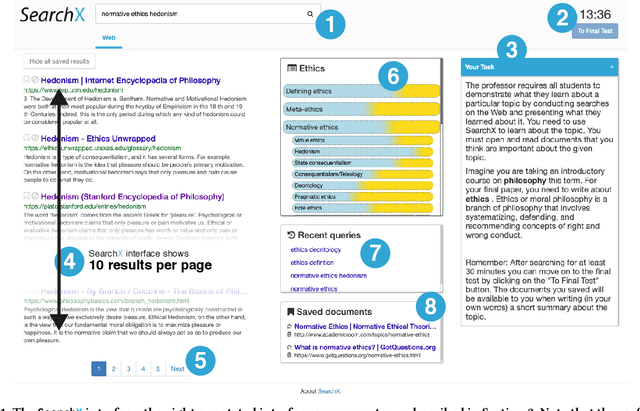


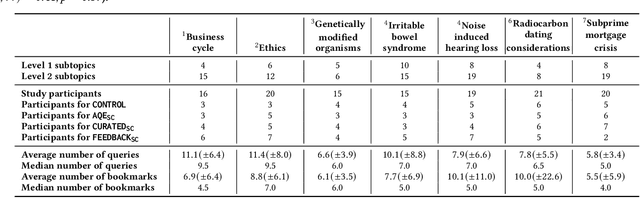
Search engines are considered the primary tool to assist and empower learners in finding information relevant to their learning goals-be it learning something new, improving their existing skills, or just fulfilling a curiosity. While several approaches for improving search engines for the learning scenario have been proposed, instructional scaffolding has not been studied in the context of search as learning, despite being shown to be effective for improving learning in both digital and traditional learning contexts. When scaffolding is employed, instructors provide learners with support throughout their autonomous learning process. We hypothesize that the usage of scaffolding techniques within a search system can be an effective way to help learners achieve their learning objectives whilst searching. As such, this paper investigates the incorporation of scaffolding into a search system employing three different strategies (as well as a control condition): (I) AQE_{SC}, the automatic expansion of user queries with relevant subtopics; (ii) CURATED_{SC}, the presenting of a manually curated static list of relevant subtopics on the search engine result page; and (iii) FEEDBACK_{SC}, which projects real-time feedback about a user's exploration of the topic space on top of the CURATED_{SC} visualization. To investigate the effectiveness of these approaches with respect to human learning, we conduct a user study (N=126) where participants were tasked with searching and learning about topics such as `genetically modified organisms'. We find that (I) the introduction of the proposed scaffolding methods does not significantly improve learning gains. However, (ii) it does significantly impact search behavior. Furthermore, (iii) immediate feedback of the participants' learning leads to undesirable user behavior, with participants focusing on the feedback gauges instead of learning.
On the Calibration and Uncertainty of Neural Learning to Rank Models
Jan 12, 2021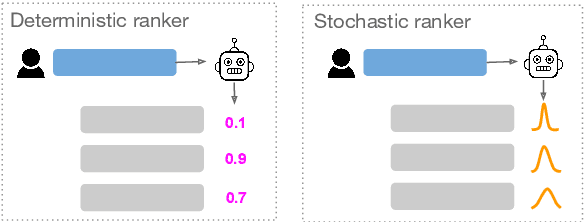
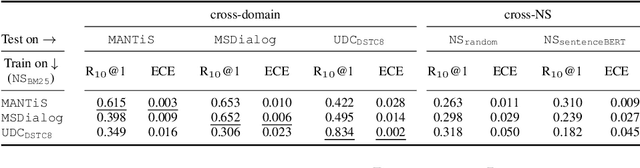

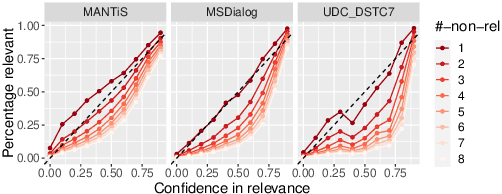
According to the Probability Ranking Principle (PRP), ranking documents in decreasing order of their probability of relevance leads to an optimal document ranking for ad-hoc retrieval. The PRP holds when two conditions are met: [C1] the models are well calibrated, and, [C2] the probabilities of relevance are reported with certainty. We know however that deep neural networks (DNNs) are often not well calibrated and have several sources of uncertainty, and thus [C1] and [C2] might not be satisfied by neural rankers. Given the success of neural Learning to Rank (L2R) approaches-and here, especially BERT-based approaches-we first analyze under which circumstances deterministic, i.e. outputs point estimates, neural rankers are calibrated. Then, motivated by our findings we use two techniques to model the uncertainty of neural rankers leading to the proposed stochastic rankers, which output a predictive distribution of relevance as opposed to point estimates. Our experimental results on the ad-hoc retrieval task of conversation response ranking reveal that (i) BERT-based rankers are not robustly calibrated and that stochastic BERT-based rankers yield better calibration; and (ii) uncertainty estimation is beneficial for both risk-aware neural ranking, i.e.taking into account the uncertainty when ranking documents, and for predicting unanswerable conversational contexts.
Weakly Supervised Label Smoothing
Dec 15, 2020


We study Label Smoothing (LS), a widely used regularization technique, in the context of neural learning to rank (L2R) models. LS combines the ground-truth labels with a uniform distribution, encouraging the model to be less confident in its predictions. We analyze the relationship between the non-relevant documents-specifically how they are sampled-and the effectiveness of LS, discussing how LS can be capturing "hidden similarity knowledge" between the relevantand non-relevant document classes. We further analyze LS by testing if a curriculum-learning approach, i.e., starting with LS and after anumber of iterations using only ground-truth labels, is beneficial. Inspired by our investigation of LS in the context of neural L2R models, we propose a novel technique called Weakly Supervised Label Smoothing (WSLS) that takes advantage of the retrieval scores of the negative sampled documents as a weak supervision signal in the process of modifying the ground-truth labels. WSLS is simple to implement, requiring no modification to the neural ranker architecture. Our experiments across three retrieval tasks-passage retrieval, similar question retrieval and conversation response ranking-show that WSLS for pointwise BERT-based rankers leads to consistent effectiveness gains. The source code is available at https://anonymous.4open.science/r/dac85d48-6f71-4261-a7d8-040da6021c52/.
Slice-Aware Neural Ranking
Oct 07, 2020
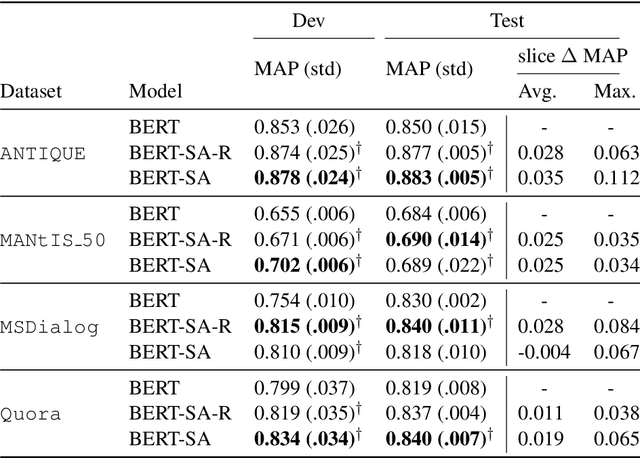
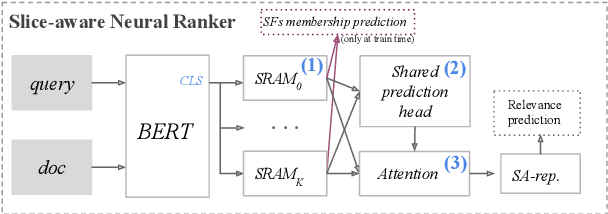
Understanding when and why neural ranking models fail for an IR task via error analysis is an important part of the research cycle. Here we focus on the challenges of (i) identifying categories of difficult instances (a pair of question and response candidates) for which a neural ranker is ineffective and (ii) improving neural ranking for such instances. To address both challenges we resort to slice-based learning for which the goal is to improve effectiveness of neural models for slices (subsets) of data. We address challenge (i) by proposing different slicing functions (SFs) that select slices of the dataset---based on prior work we heuristically capture different failures of neural rankers. Then, for challenge (ii) we adapt a neural ranking model to learn slice-aware representations, i.e. the adapted model learns to represent the question and responses differently based on the model's prediction of which slices they belong to. Our experimental results (the source code and data are available at https://github.com/Guzpenha/slice_based_learning) across three different ranking tasks and four corpora show that slice-based learning improves the effectiveness by an average of 2% over a neural ranker that is not slice-aware.
Curriculum Learning Strategies for IR: An Empirical Study on Conversation Response Ranking
Dec 18, 2019
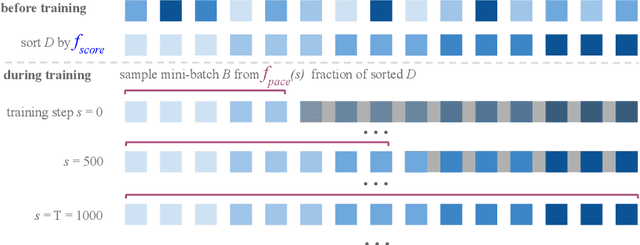


Neural ranking models are traditionally trained on a series of random batches, sampled uniformly from the entire training set. Curriculum learning has recently been shown to improve neural models' effectiveness by sampling batches non-uniformly, going from easy to difficult instances during training. In the context of neural Information Retrieval (IR) curriculum learning has not been explored yet, and so it remains unclear (1) how to measure the difficulty of training instances and (2) how to transition from easy to difficult instances during training. To address both challenges and determine whether curriculum learning is beneficial for neural ranking models, we need large-scale datasets and a retrieval task that allows us to conduct a wide range of experiments. For this purpose, we resort to the task of conversation response ranking: ranking responses given the conversation history. In order to deal with challenge (1), we explore scoring functions to measure the difficulty of conversations based on different input spaces. To address challenge (2) we evaluate different pacing functions, which determine the velocity in which we go from easy to difficult instances. We find that, overall, by just intelligently sorting the training data (i.e., by performing curriculum learning) we can improve the retrieval effectiveness by up to 2%.
Introducing MANtIS: a novel Multi-Domain Information Seeking Dialogues Dataset
Dec 10, 2019
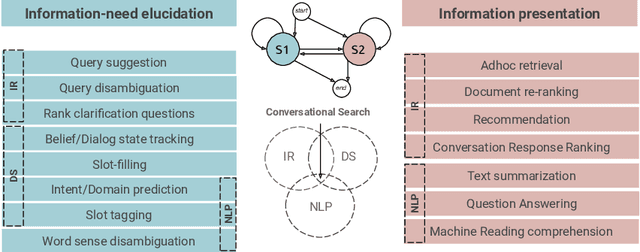
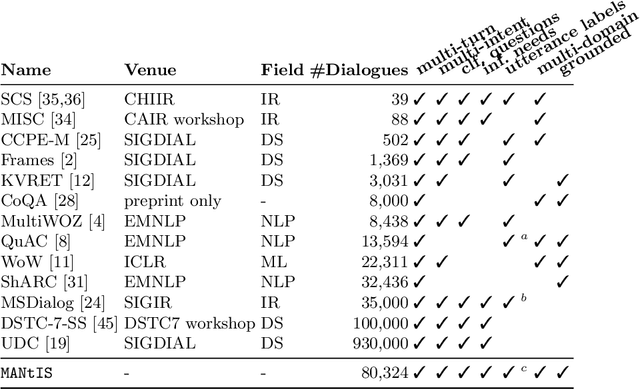
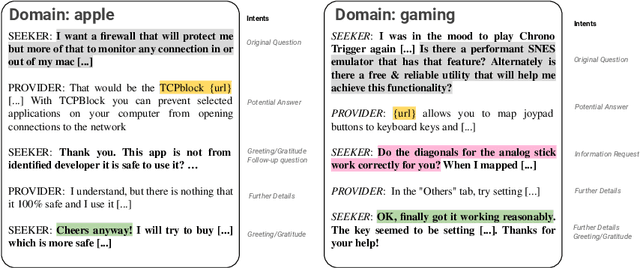
Conversational search is an approach to information retrieval (IR), where users engage in a dialogue with an agent in order to satisfy their information needs. Previous conceptual work described properties and actions a good agent should exhibit. Unlike them, we present a novel conceptual model defined in terms of conversational goals, which enables us to reason about current research practices in conversational search. Based on the literature, we elicit how existing tasks and test collections from the fields of IR, natural language processing (NLP) and dialogue systems (DS) fit into this model. We describe a set of characteristics that an ideal conversational search dataset should have. Lastly, we introduce MANtIS (the code and dataset are available at https://guzpenha.github.io/MANtIS/), a large-scale dataset containing multi-domain and grounded information seeking dialogues that fulfill all of our dataset desiderata. We provide baseline results for the conversation response ranking and user intent prediction tasks.
U-Sem: Semantic Enrichment, User Modeling and Mining of Usage Data on the Social Web
Apr 01, 2011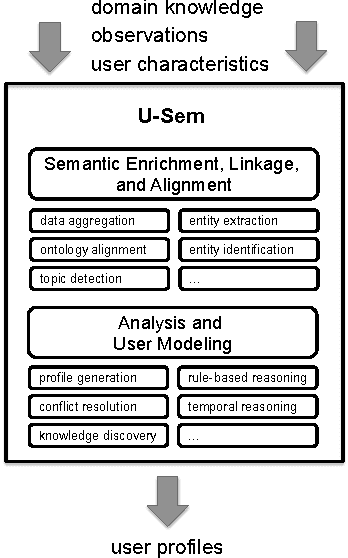
With the growing popularity of Social Web applications, more and more user data is published on the Web everyday. Our research focuses on investigating ways of mining data from such platforms that can be used for modeling users and for semantically augmenting user profiles. This process can enhance adaptation and personalization in various adaptive Web-based systems. In this paper, we present the U-Sem people modeling service, a framework for the semantic enrichment and mining of people's profiles from usage data on the Social Web. We explain the architecture of our people modeling service and describe its application in an adult e-learning context as an example. Versions: Mar 21, 10:10, Mar 25, 09:37