 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueerGen: How LLMs Reflect Societal Norms on Gender and Sexuality in Sentence Completion Tasks
Jan 28, 2026This paper examines how Large Language Models (LLMs) reproduce societal norms, particularly heterocisnormativity, and how these norms translate into measurable biases in their text generations. We investigate whether explicit information about a subject's gender or sexuality influences LLM responses across three subject categories: queer-marked, non-queer-marked, and the normalized "unmarked" category. Representational imbalances are operationalized as measurable differences in English sentence completions across four dimensions: sentiment, regard, toxicity, and prediction diversity. Our findings show that Masked Language Models (MLMs) produce the least favorable sentiment, higher toxicity, and more negative regard for queer-marked subjects. Autoregressive Language Models (ARLMs) partially mitigate these patterns, while closed-access ARLMs tend to produce more harmful outputs for unmarked subjects. Results suggest that LLMs reproduce normative social assumptions, though the form and degree of bias depend strongly on specific model characteristics, which may redistribute, but not eliminate, representational harms.
On the challenges of studying bias in Recommender Systems: A UserKNN case study
Sep 12, 2024


Statements on the propagation of bias by recommender systems are often hard to verify or falsify. Research on bias tends to draw from a small pool of publicly available datasets and is therefore bound by their specific properties. Additionally, implementation choices are often not explicitly described or motivated in research, while they may have an effect on bias propagation. In this paper, we explore the challenges of measuring and reporting popularity bias. We showcase the impact of data properties and algorithm configurations on popularity bias by combining synthetic data with well known recommender systems frameworks that implement UserKNN. First, we identify data characteristics that might impact popularity bias, based on the functionality of UserKNN. Accordingly, we generate various datasets that combine these characteristics. Second, we locate UserKNN configurations that vary across implementations in literature. We evaluate popularity bias for five synthetic datasets and five UserKNN configurations, and offer insights on their joint effect. We find that, depending on the data characteristics, various UserKNN configurations can lead to different conclusions regarding the propagation of popularity bias. These results motivate the need for explicitly addressing algorithmic configuration and data properties when reporting and interpreting bias in recommender systems.
How to Diversify any Personalized Recommender? A User-centric Pre-processing approach
May 03, 2024



In this paper, we introduce a novel approach to improve the diversity of Top-N recommendations while maintaining recommendation performance. Our approach employs a user-centric pre-processing strategy aimed at exposing users to a wide array of content categories and topics. We personalize this strategy by selectively adding and removing a percentage of interactions from user profiles. This personalization ensures we remain closely aligned with user preferences while gradually introducing distribution shifts. Our pre-processing technique offers flexibility and can seamlessly integrate into any recommender architecture. To evaluate our approach, we run extensive experiments on two publicly available data sets for news and book recommendations. We test various standard and neural network-based recommender system algorithms. Our results show that our approach generates diverse recommendations, ensuring users are exposed to a wider range of items. Furthermore, leveraging pre-processed data for training leads to recommender systems achieving performance levels comparable to, and in some cases, better than those trained on original, unmodified data. Additionally, our approach promotes provider fairness by facilitating exposure to minority or niche categories.
Diversity of What? On the Different Conceptualizations of Diversity in Recommender Systems
May 03, 2024

Diversity is a commonly known principle in the design of recommender systems, but also ambiguous in its conceptualization. Through semi-structured interviews we explore how practitioners at three different public service media organizations in the Netherlands conceptualize diversity within the scope of their recommender systems. We provide an overview of the goals that they have with diversity in their systems, which aspects are relevant, and how recommendations should be diversified. We show that even within this limited domain, conceptualization of diversity greatly varies, and argue that it is unlikely that a standardized conceptualization will be achieved. Instead, we should focus on effective communication of what diversity in this particular system means, thus allowing for operationalizations of diversity that are capable of expressing the nuances and requirements of that particular domain.
How Contentious Terms About People and Cultures are Used in Linked Open Data
Nov 13, 2023Web resources in linked open data (LOD) are comprehensible to humans through literal textual values attached to them, such as labels, notes, or comments. Word choices in literals may not always be neutral. When outdated and culturally stereotyping terminology is used in literals, they may appear as offensive to users in interfaces and propagate stereotypes to algorithms trained on them. We study how frequently and in which literals contentious terms about people and cultures occur in LOD and whether there are attempts to mark the usage of such terms. For our analysis, we reuse English and Dutch terms from a knowledge graph that provides opinions of experts from the cultural heritage domain about terms' contentiousness. We inspect occurrences of these terms in four widely used datasets: Wikidata, The Getty Art & Architecture Thesaurus, Princeton WordNet, and Open Dutch WordNet. Some terms are ambiguous and contentious only in particular senses. Applying word sense disambiguation, we generate a set of literals relevant to our analysis. We found that outdated, derogatory, stereotyping terms frequently appear in descriptive and labelling literals, such as preferred labels that are usually displayed in interfaces and used for indexing. In some cases, LOD contributors mark contentious terms with words and phrases in literals (implicit markers) or properties linked to resources (explicit markers). However, such marking is rare and non-consistent in all datasets. Our quantitative and qualitative insights could be helpful in developing more systematic approaches to address the propagation of stereotypes via LOD.
Is it a Fruit, an Apple or a Granny Smith? Predicting the Basic Level in a Concept Hierarchy
Oct 25, 2019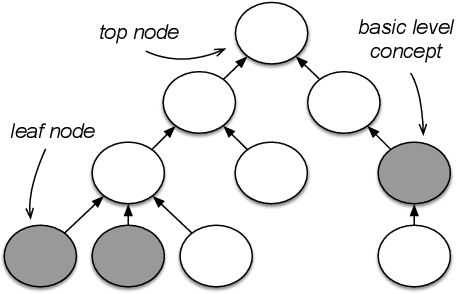
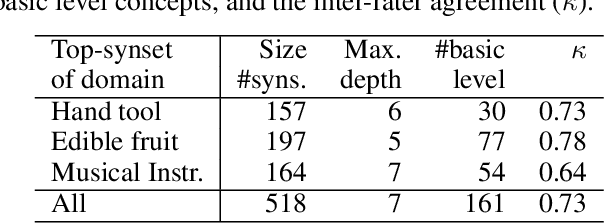
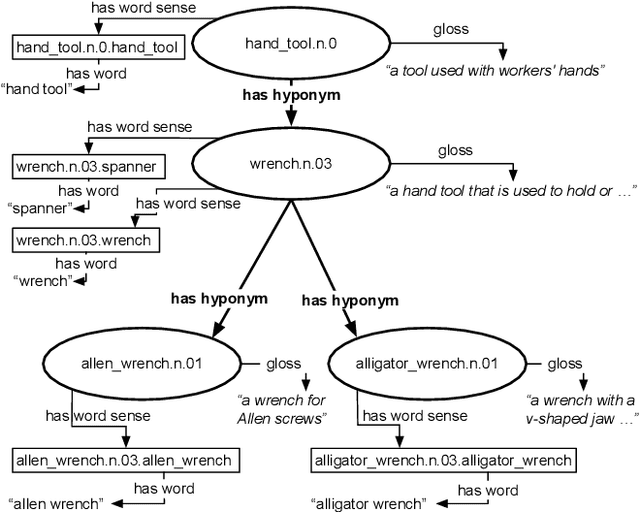
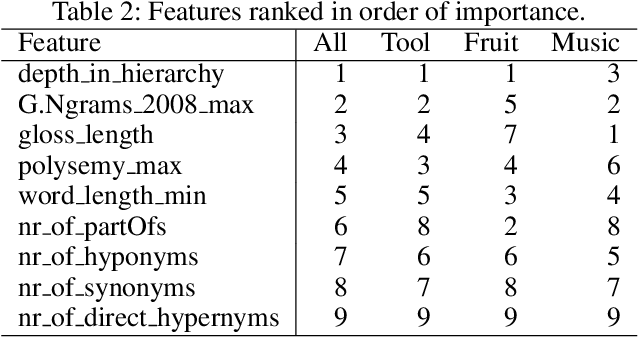
The "basic level", according to experiments in cognitive psychology, is the level of abstraction in a hierarchy of concepts at which humans perform tasks quicker and with greater accuracy than at other levels. We argue that applications that use concept hierarchies - such as knowledge graphs, ontologies or taxonomies - could significantly improve their user interfaces if they `knew' which concepts are the basic level concepts. This paper examines to what extent the basic level can be learned from data. We test the utility of three types of concept features, that were inspired by the basic level theory: lexical features, structural features and frequency features. We evaluate our approach on WordNet, and create a training set of manually labelled examples that includes concepts from different domains. Our findings include that the basic level concepts can be accurately identified within one domain. Concepts that are difficult to label for humans are also harder to classify automatically. Our experiments provide insight into how classification performance across domains could be improved, which is necessary for identification of basic level concepts on a larger scale.
Utilizing a Transparency-driven Environment toward Trusted Automatic Genre Classification: A Case Study in Journalism History
Oct 01, 2018
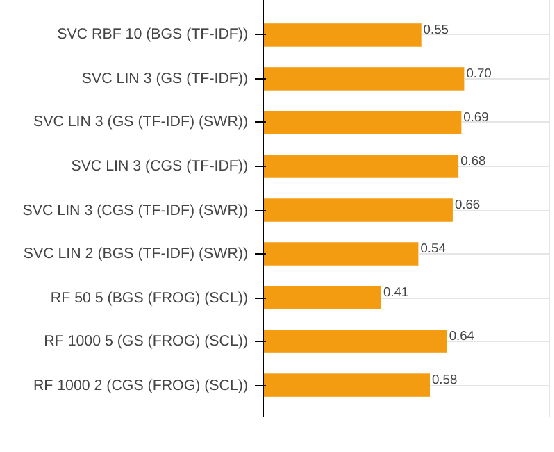
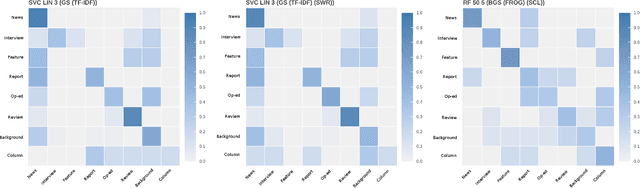
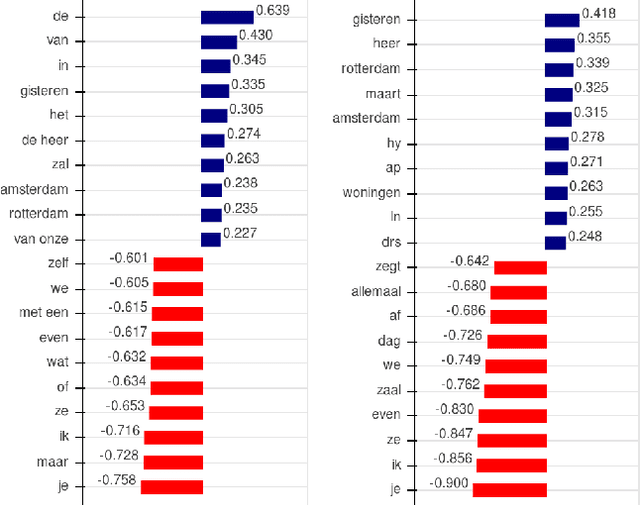
With the growing abundance of unlabeled data in real-world tasks, researchers have to rely on the predictions given by black-boxed computational models. However, it is an often neglected fact that these models may be scoring high on accuracy for the wrong reasons. In this paper, we present a practical impact analysis of enabling model transparency by various presentation forms. For this purpose, we developed an environment that empowers non-computer scientists to become practicing data scientists in their own research field. We demonstrate the gradually increasing understanding of journalism historians through a real-world use case study on automatic genre classification of newspaper articles. This study is a first step towards trusted usage of machine learning pipelines in a responsible way.
U-Sem: Semantic Enrichment, User Modeling and Mining of Usage Data on the Social Web
Apr 01, 2011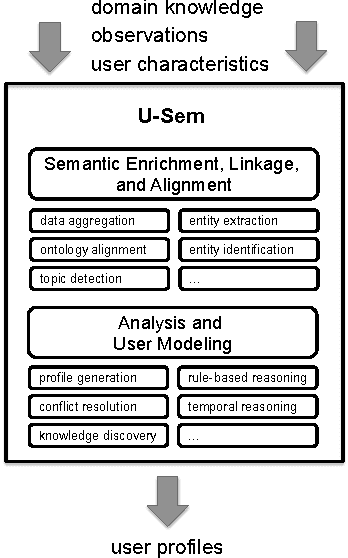
With the growing popularity of Social Web applications, more and more user data is published on the Web everyday. Our research focuses on investigating ways of mining data from such platforms that can be used for modeling users and for semantically augmenting user profiles. This process can enhance adaptation and personalization in various adaptive Web-based systems. In this paper, we present the U-Sem people modeling service, a framework for the semantic enrichment and mining of people's profiles from usage data on the Social Web. We explain the architecture of our people modeling service and describe its application in an adult e-learning context as an example. Versions: Mar 21, 10:10, Mar 25, 09:37