 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Optimistic Algorithms for Logistic Bandits
Feb 18, 2020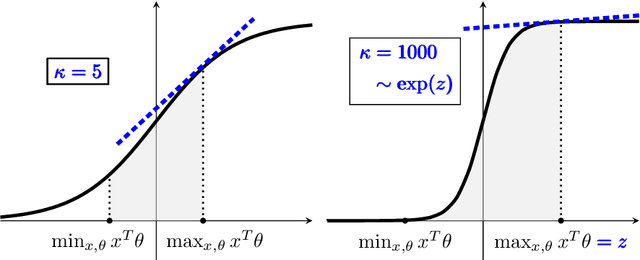

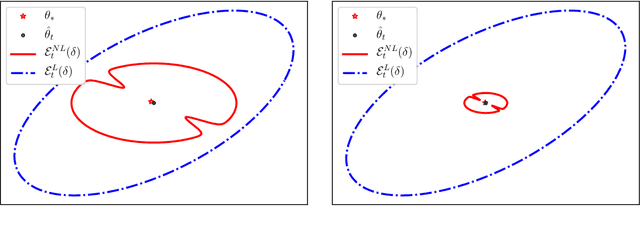
The generalized linear bandit framework has attracted a lot of attention in recent years by extending the well-understood linear setting and allowing to model richer reward structures. It notably covers the logistic model, widely used when rewards are binary. For logistic bandits, the frequentist regret guarantees of existing algorithms are $\tilde{\mathcal{O}}(\kappa \sqrt{T})$, where $\kappa$ is a problem-dependent constant. Unfortunately, $\kappa$ can be arbitrarily large as it scales exponentially with the size of the decision set. This may lead to significantly loose regret bounds and poor empirical performance. In this work, we study the logistic bandit with a focus on the prohibitive dependencies introduced by $\kappa$. We propose a new optimistic algorithm based on a finer examination of the non-linearities of the reward function. We show that it enjoys a $\tilde{\mathcal{O}}(\sqrt{T})$ regret with no dependency in $\kappa$, but for a second order term. Our analysis is based on a new tail-inequality for self-normalized martingales, of independent interest.
End-to-End Learning of Geometric Deformations of Feature Maps for Virtual Try-On
Jun 10, 2019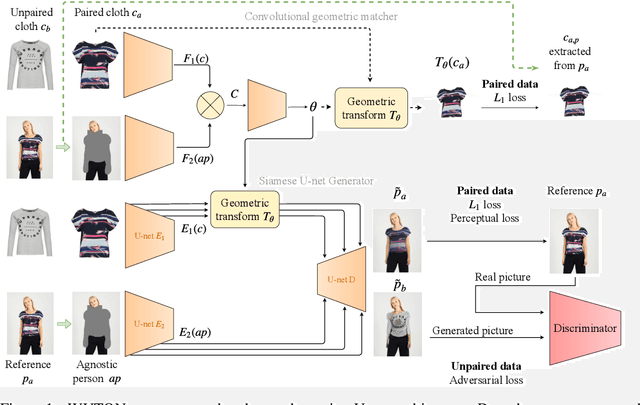



The 2D virtual try-on task has recently attracted a lot of interest from the research community, for its direct potential applications in online shopping as well as for its inherent and non-addressed scientific challenges. This task requires to fit an in-shop cloth image on the image of a person. It is highly challenging because it requires to warp the cloth on the target person while preserving its patterns and characteristics, and to compose the item with the person in a realistic manner. Current state-of-the-art models generate images with visible artifacts, due either to a pixel-level composition step or to the geometric transformation. In this paper, we propose WUTON: a Warping U-net for a Virtual Try-On system. It is a siamese U-net generator whose skip connections are geometrically transformed by a convolutional geometric matcher. The whole architecture is trained end-to-end with a multi-task loss including an adversarial one. This enables our network to generate and use realistic spatial transformations of the cloth to synthesize images of high visual quality. The proposed architecture can be trained end-to-end and allows us to advance towards a detail-preserving and photo-realistic 2D virtual try-on system. Our method outperforms the current state-of-the-art with visual results as well as with the Learned Perceptual Image Similarity (LPIPS) metric.
Bridging the gap between regret minimization and best arm identification, with application to A/B tests
Oct 09, 2018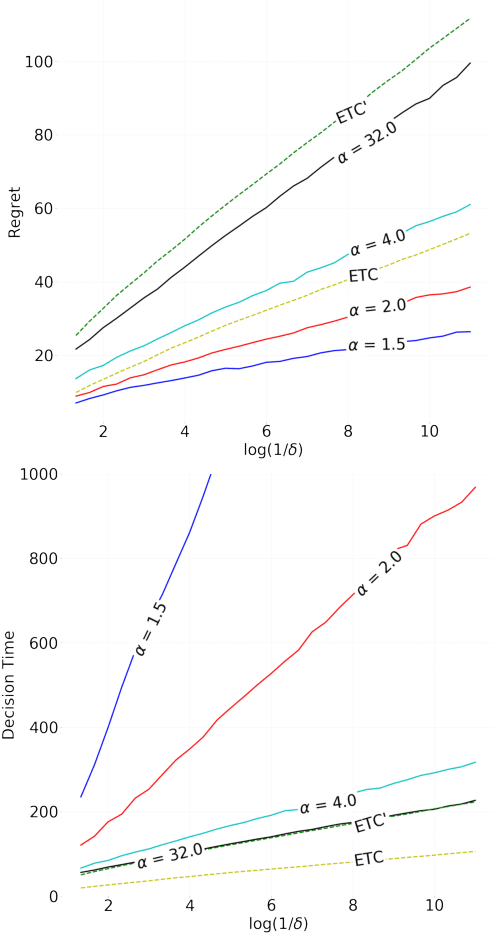
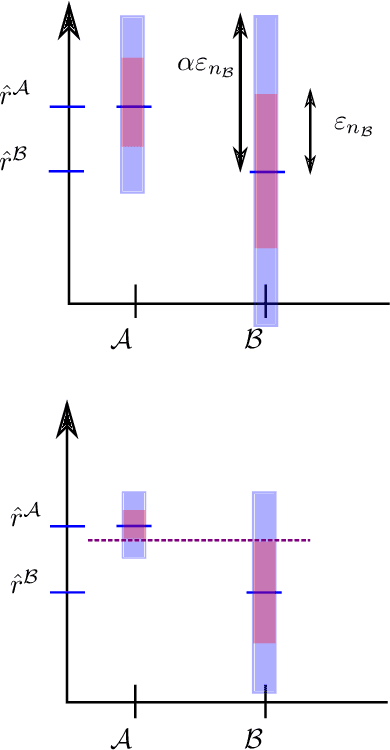
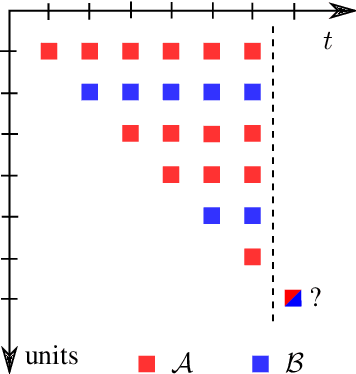
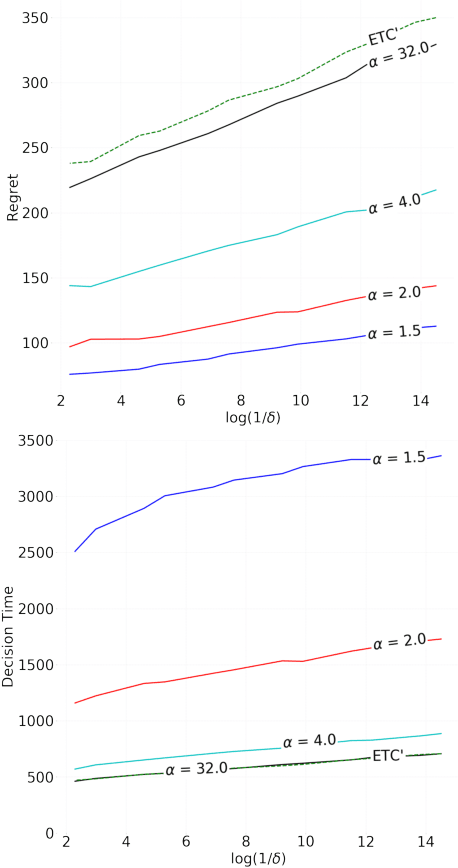
State of the art online learning procedures focus either on selecting the best alternative ("best arm identification") or on minimizing the cost (the "regret"). We merge these two objectives by providing the theoretical analysis of cost minimizing algorithms that are also delta-PAC (with a proven guaranteed bound on the decision time), hence fulfilling at the same time regret minimization and best arm identification. This analysis sheds light on the common observation that ill-callibrated UCB-algorithms minimize regret while still identifying quickly the best arm. We also extend these results to the non-iid case faced by many practitioners. This provides a technique to make cost versus decision time compromise when doing adaptive tests with applications ranging from website A/B testing to clinical trials.
Neural Generative Models for Global Optimization with Gradients
Jun 14, 2018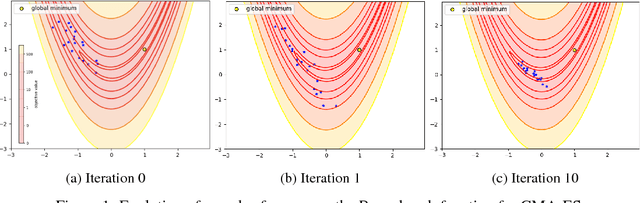
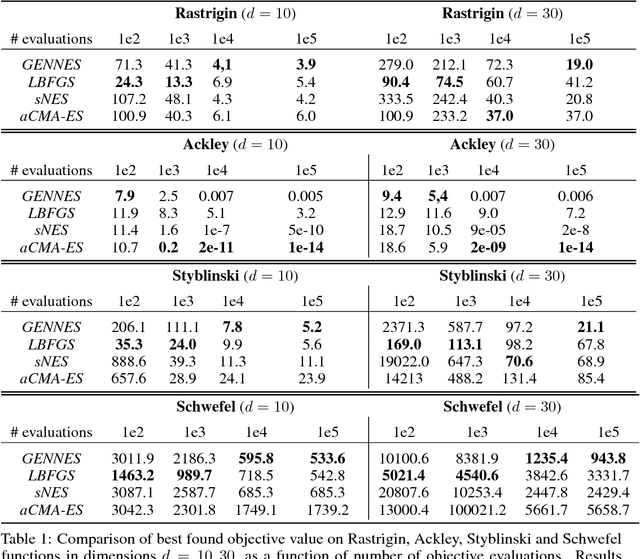
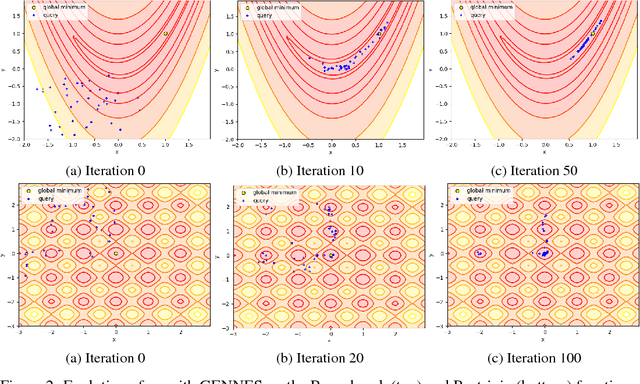

The aim of global optimization is to find the global optimum of arbitrary classes of functions, possibly highly multimodal ones. In this paper we focus on the subproblem of global optimization for differentiable functions and we propose an Evolutionary Search-inspired solution where we model point search distributions via Generative Neural Networks. This approach enables us to model diverse and complex search distributions based on which we can efficiently explore complicated objective landscapes. In our experiments we show the practical superiority of our algorithm versus classical Evolutionary Search and gradient-based solutions on a benchmark set of multimodal functions, and demonstrate how it can be used to accelerate Bayesian Optimization with Gaussian Processes.
Offline A/B testing for Recommender Systems
Jan 22, 2018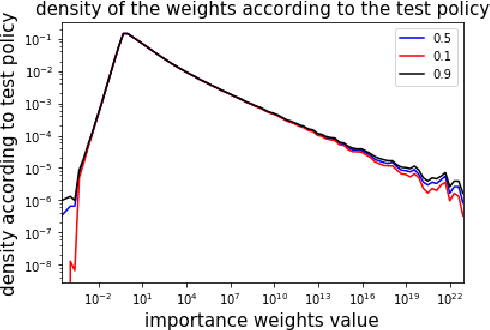

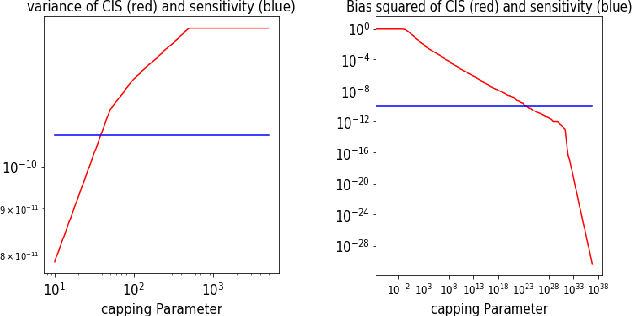

Before A/B testing online a new version of a recommender system, it is usual to perform some offline evaluations on historical data. We focus on evaluation methods that compute an estimator of the potential uplift in revenue that could generate this new technology. It helps to iterate faster and to avoid losing money by detecting poor policies. These estimators are known as counterfactual or off-policy estimators. We show that traditional counterfactual estimators such as capped importance sampling and normalised importance sampling are experimentally not having satisfying bias-variance compromises in the context of personalised product recommendation for online advertising. We propose two variants of counterfactual estimates with different modelling of the bias that prove to be accurate in real-world conditions. We provide a benchmark of these estimators by showing their correlation with business metrics observed by running online A/B tests on a commercial recommender system.
Distributed SAGA: Maintaining linear convergence rate with limited communication
May 29, 2017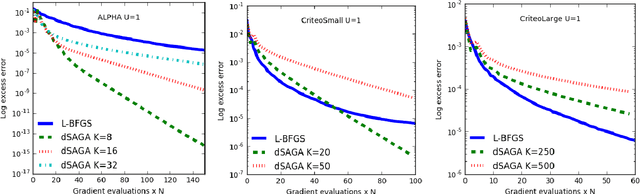
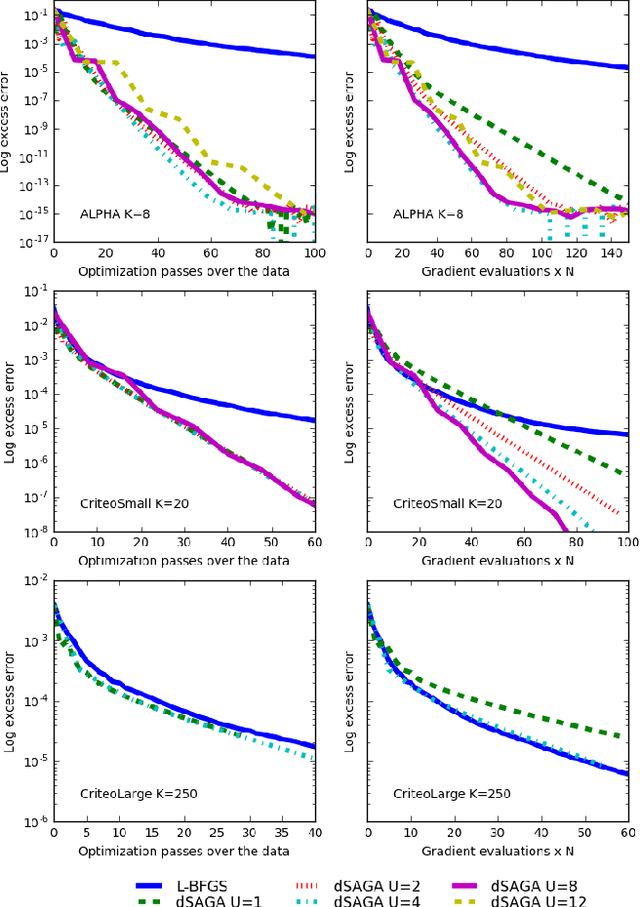
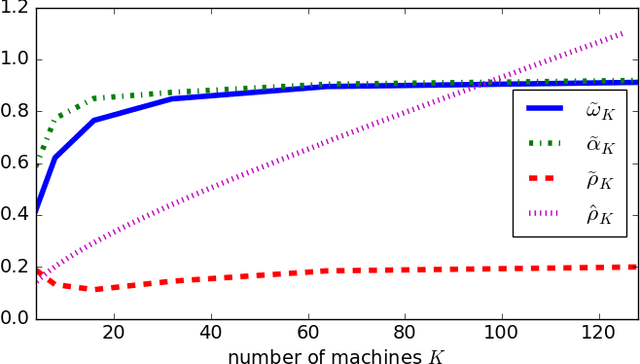
In recent years, variance-reducing stochastic methods have shown great practical performance, exhibiting linear convergence rate when other stochastic methods offered a sub-linear rate. However, as datasets grow ever bigger and clusters become widespread, the need for fast distribution methods is pressing. We propose here a distribution scheme for SAGA which maintains a linear convergence rate, even when communication between nodes is limited.