 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Data Augmentation for Vehicle Detection in Aerial Images
Dec 09, 2020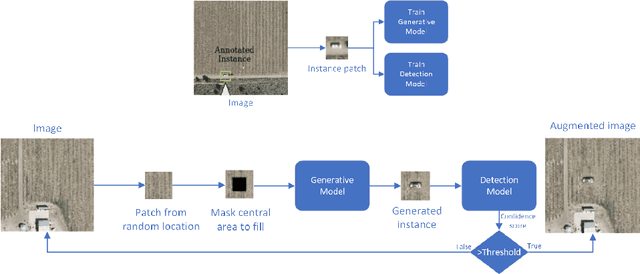
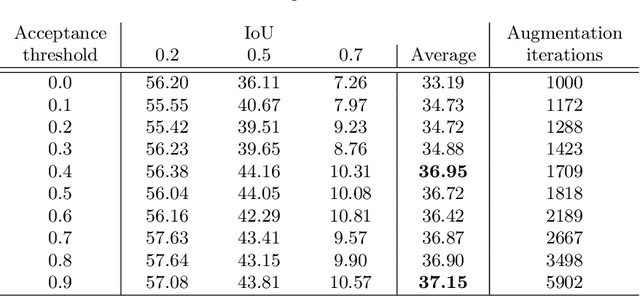
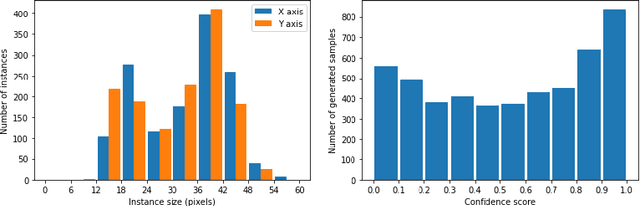
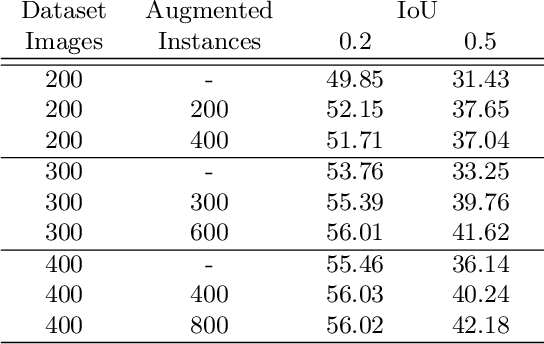
Scarcity of training data is one of the prominent problems for deep networks which require large amounts data. Data augmentation is a widely used method to increase the number of training samples and their variations. In this paper, we focus on improving vehicle detection performance in aerial images and propose a generative augmentation method which does not need any extra supervision than the bounding box annotations of the vehicle objects in the training dataset. The proposed method increases the performance of vehicle detection by allowing detectors to be trained with higher number of instances, especially when there are limited number of training instances. The proposed method is generic in the sense that it can be integrated with different generators. The experiments show that the method increases the Average Precision by up to 25.2% and 25.7% when integrated with Pluralistic and DeepFill respectively.
LPMNet: Latent Part Modification and Generation for 3D Point Clouds
Aug 08, 2020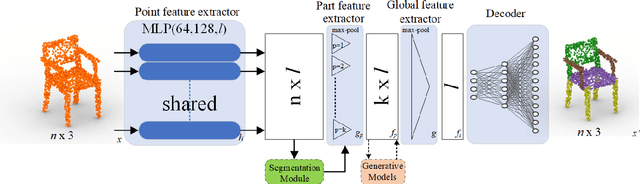
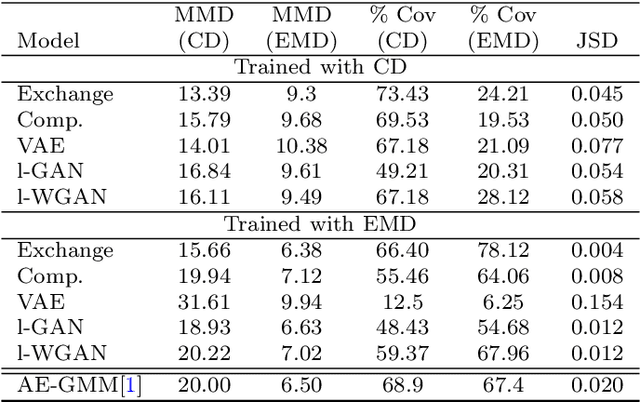
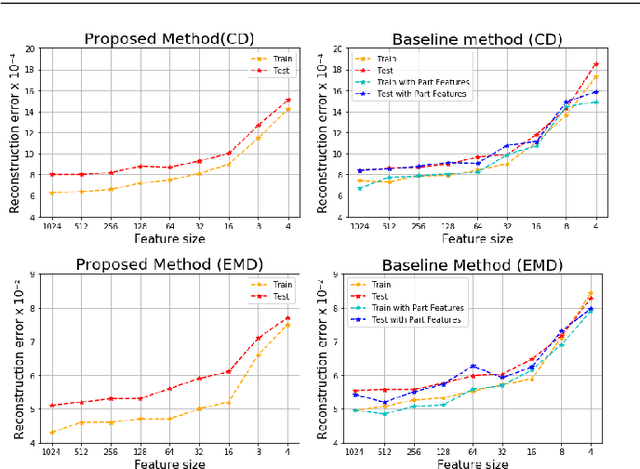

In this paper, we focus on latent modification and generation of 3D point cloud object models with respect to their semantic parts. Different to the existing methods which use separate networks for part generation and assembly, we propose a single end-to-end Autoencoder model that can handle generation and modification of both semantic parts, and global shapes. The proposed method supports part exchange between 3D point cloud models and composition by different parts to form new models by directly editing latent representations. This holistic approach does not need part-based training to learn part representations and does not introduce any extra loss besides the standard reconstruction loss. The experiments demonstrate the robustness of the proposed method with different object categories and varying number of points. The method can generate new models by integration of generative models such as GANs and VAEs and can work with unannotated point clouds by integration of a segmentation module.