 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Automated Policy Learning for Nonlinear Welfare
Jun 01, 2026This paper explores policy learning from observational data, focusing on a nonlinear welfare criterion in a binary treatment setting. The nonlinear criterion is inspired by scenarios where policymakers prioritize specific population segments. We model this criterion using a utility function that encompasses potential outcomes and intermediate parameters, with the latter capturing higher moments of the outcome distributions. When formulated in the context of observational data, both the intermediate parameters and the welfare criterion depend on the propensity score, which we estimate using machine-learning techniques. To address bias in machine learning estimates, we introduce a novel reweighting-based debiasing approach that offers a promising alternative to traditional orthogonality-based methods. To tackle the complexities of infinite-dimensional policy spaces, we employ sieve approximations and $K$-fold cross-validation for model selection, thereby fully automating the policy-learning process. Despite these complexities, we demonstrate that both the welfare regret and the average welfare regret of our proposed policy learning method satisfy an oracle inequality, thereby providing theoretical guarantees on the performance of the estimated policy relative to the best possible policy. This finding extends the existing results from linear to nonlinear welfare criteria, from finite-dimensional to infinite-dimensional policy spaces, and from a known propensity score to a machine-learned one.
Compressing Features for Learning with Noisy Labels
Jun 27, 2022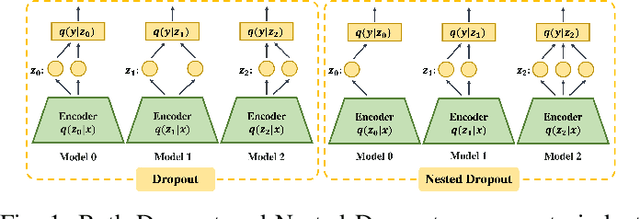
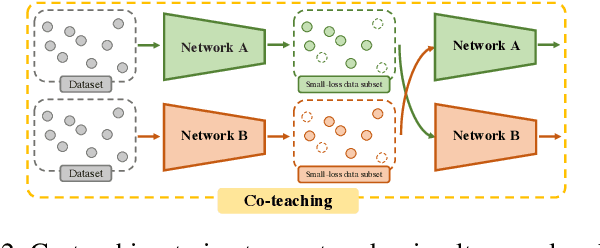
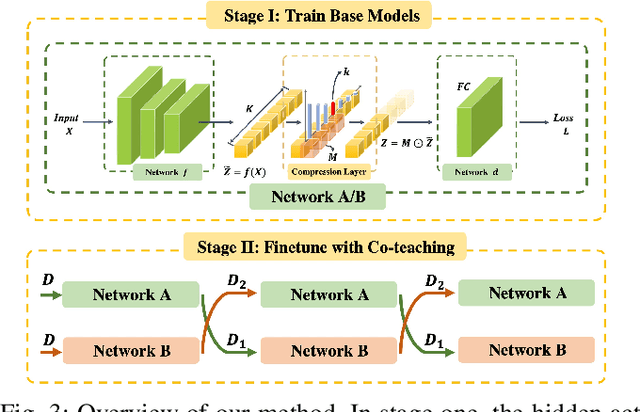
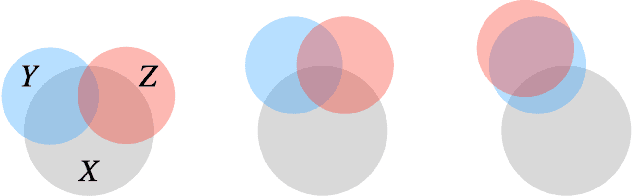
Supervised learning can be viewed as distilling relevant information from input data into feature representations. This process becomes difficult when supervision is noisy as the distilled information might not be relevant. In fact, recent research shows that networks can easily overfit all labels including those that are corrupted, and hence can hardly generalize to clean datasets. In this paper, we focus on the problem of learning with noisy labels and introduce compression inductive bias to network architectures to alleviate this over-fitting problem. More precisely, we revisit one classical regularization named Dropout and its variant Nested Dropout. Dropout can serve as a compression constraint for its feature dropping mechanism, while Nested Dropout further learns ordered feature representations w.r.t. feature importance. Moreover, the trained models with compression regularization are further combined with Co-teaching for performance boost. Theoretically, we conduct bias-variance decomposition of the objective function under compression regularization. We analyze it for both single model and Co-teaching. This decomposition provides three insights: (i) it shows that over-fitting is indeed an issue for learning with noisy labels; (ii) through an information bottleneck formulation, it explains why the proposed feature compression helps in combating label noise; (iii) it gives explanations on the performance boost brought by incorporating compression regularization into Co-teaching. Experiments show that our simple approach can have comparable or even better performance than the state-of-the-art methods on benchmarks with real-world label noise including Clothing1M and ANIMAL-10N. Our implementation is available at https://yingyichen-cyy.github.io/CompressFeatNoisyLabels/.