 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicies of Multiple Skill Levels for Better Strength Estimation in Games
May 01, 2025



Accurately estimating human skill levels is crucial for designing effective human-AI interactions so that AI can provide appropriate challenges or guidance. In games where AI players have beaten top human professionals, strength estimation plays a key role in adapting AI behavior to match human skill levels. In a previous state-of-the-art study, researchers have proposed a strength estimator trained using human players' match data. Given some matches, the strength estimator computes strength scores and uses them to estimate player ranks (skill levels). In this paper, we focus on the observation that human players' behavior tendency varies according to their strength and aim to improve the accuracy of strength estimation by taking this into account. Specifically, in addition to strength scores, we obtain policies for different skill levels from neural networks trained using human players' match data. We then combine features based on these policies with the strength scores to estimate strength. We conducted experiments on Go and chess. For Go, our method achieved an accuracy of 80% in strength estimation when given 10 matches, which increased to 92% when given 20 matches. In comparison, the previous state-of-the-art method had an accuracy of 71% with 10 matches and 84% with 20 matches, demonstrating improvements of 8-9%. We observed similar improvements in chess. These results contribute to developing a more accurate strength estimation method and to improving human-AI interaction.
Multi-Stage Temporal Difference Learning for 2048-like Games
Jul 19, 2016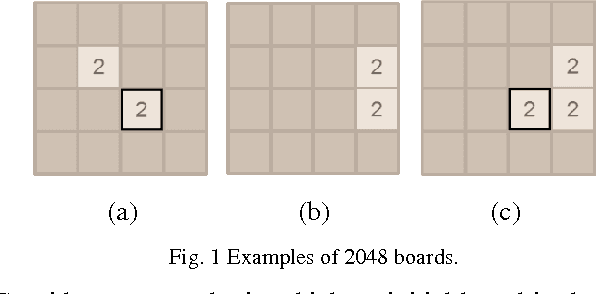
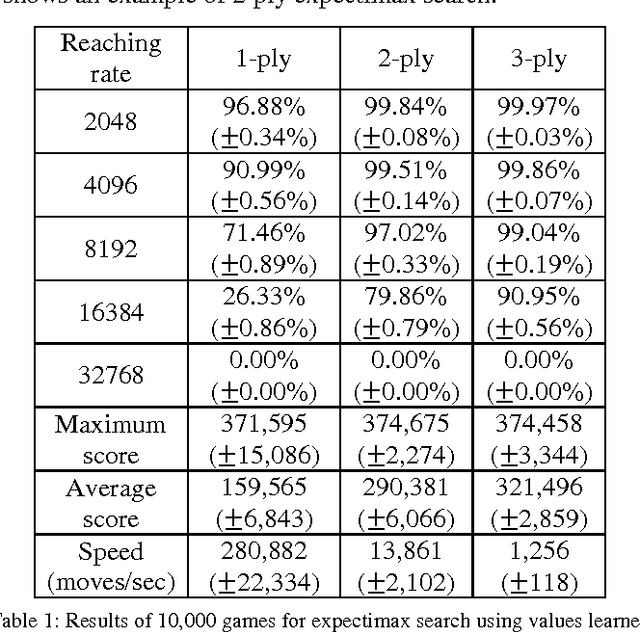
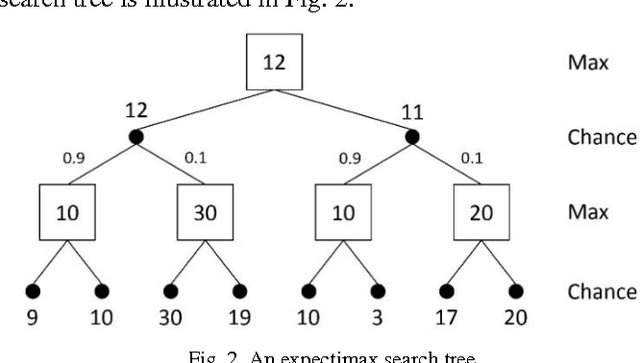
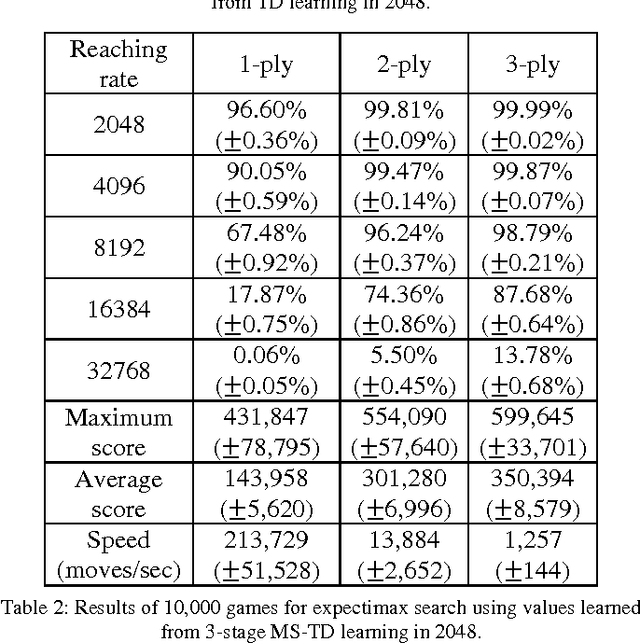
Szubert and Jaskowski successfully used temporal difference (TD) learning together with n-tuple networks for playing the game 2048. However, we observed a phenomenon that the programs based on TD learning still hardly reach large tiles. In this paper, we propose multi-stage TD (MS-TD) learning, a kind of hierarchical reinforcement learning method, to effectively improve the performance for the rates of reaching large tiles, which are good metrics to analyze the strength of 2048 programs. Our experiments showed significant improvements over the one without using MS-TD learning. Namely, using 3-ply expectimax search, the program with MS-TD learning reached 32768-tiles with a rate of 18.31%, while the one with TD learning did not reach any. After further tuned, our 2048 program reached 32768-tiles with a rate of 31.75% in 10,000 games, and one among these games even reached a 65536-tile, which is the first ever reaching a 65536-tile to our knowledge. In addition, MS-TD learning method can be easily applied to other 2048-like games, such as Threes. Based on MS-TD learning, our experiments for Threes also demonstrated similar performance improvement, where the program with MS-TD learning reached 6144-tiles with a rate of 7.83%, while the one with TD learning only reached 0.45%.