 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilevel Programming and Deep Learning: A Unifying View on Inference Learning Methods
May 15, 2021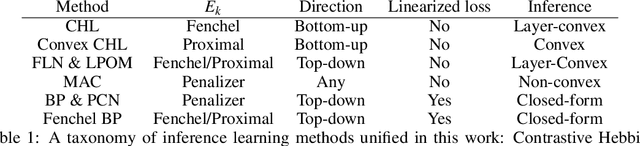
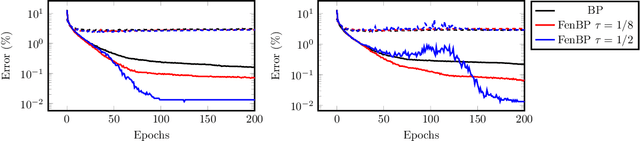
In this work we unify a number of inference learning methods, that are proposed in the literature as alternative training algorithms to the ones based on regular error back-propagation. These inference learning methods were developed with very diverse motivations, mainly aiming to enhance the biological plausibility of deep neural networks and to improve the intrinsic parallelism of training methods. We show that these superficially very different methods can all be obtained by successively applying a particular reformulation of bilevel optimization programs. As a by-product it becomes also evident that all considered inference learning methods include back-propagation as a special case, and therefore at least approximate error back-propagation in typical settings. Finally, we propose Fenchel back-propagation, that replaces the propagation of infinitesimal corrections performed in standard back-propagation with finite targets as the learning signal. Fenchel back-propagation can therefore be seen as an instance of learning via explicit target propagation.
Escaping Poor Local Minima in Large Scale Robust Estimation
Feb 22, 2021
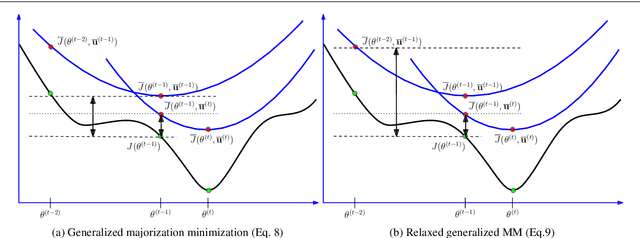
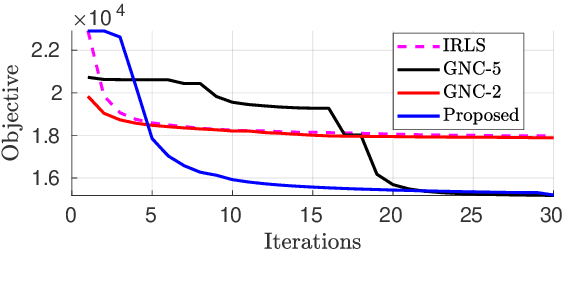
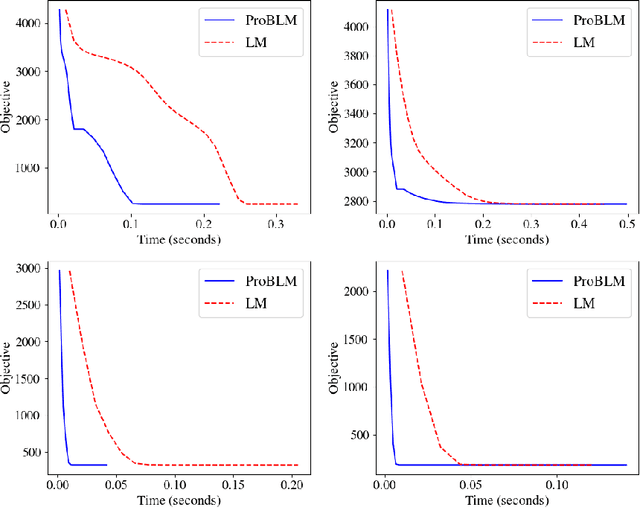
Robust parameter estimation is a crucial task in several 3D computer vision pipelines such as Structure from Motion (SfM). State-of-the-art algorithms for robust estimation, however, still suffer from difficulties in converging to satisfactory solutions due to the presence of many poor local minima or flat regions in the optimization landscapes. In this paper, we introduce two novel approaches for robust parameter estimation. The first algorithm utilizes the Filter Method (FM), which is a framework for constrained optimization allowing great flexibility in algorithmic choices, to derive an adaptive kernel scaling strategy that enjoys a strong ability to escape poor minima and achieves fast convergence rates. Our second algorithm combines a generalized Majorization Minimization (GeMM) framework with the half-quadratic lifting formulation to obtain a simple yet efficient solver for robust estimation. We empirically show that both proposed approaches show encouraging capability on avoiding poor local minima and achieve competitive results compared to existing state-of-the art robust fitting algorithms.
Progressive Batching for Efficient Non-linear Least Squares
Oct 21, 2020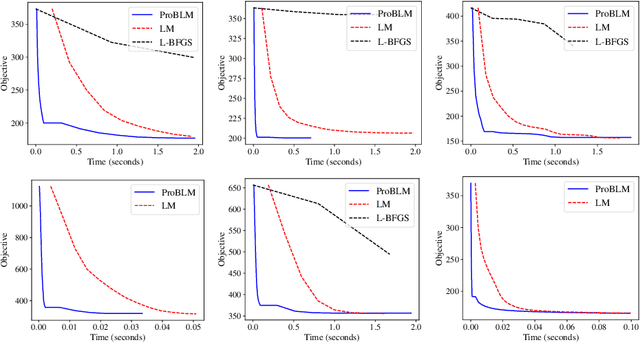
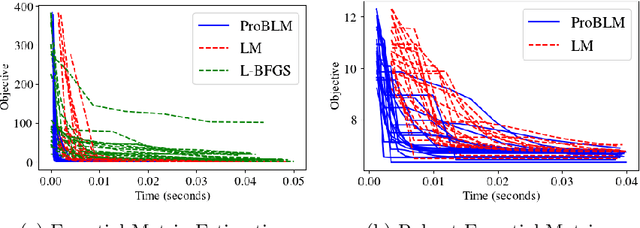
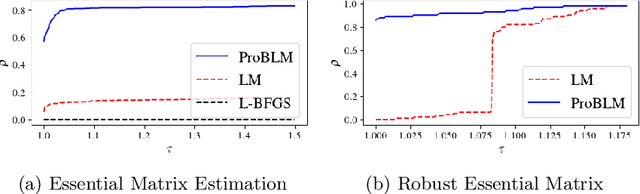
Non-linear least squares solvers are used across a broad range of offline and real-time model fitting problems. Most improvements of the basic Gauss-Newton algorithm tackle convergence guarantees or leverage the sparsity of the underlying problem structure for computational speedup. With the success of deep learning methods leveraging large datasets, stochastic optimization methods received recently a lot of attention. Our work borrows ideas from both stochastic machine learning and statistics, and we present an approach for non-linear least-squares that guarantees convergence while at the same time significantly reduces the required amount of computation. Empirical results show that our proposed method achieves competitive convergence rates compared to traditional second-order approaches on common computer vision problems, such as image alignment and essential matrix estimation, with very large numbers of residuals.
Lifted Regression/Reconstruction Networks
May 07, 2020

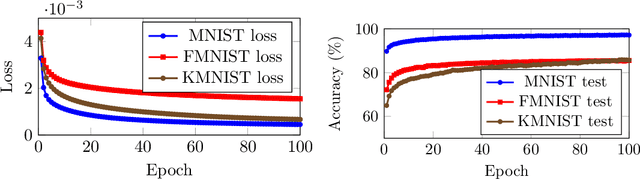

In this work we propose lifted regression/reconstruction networks (LRRNs), which combine lifted neural networks with a guaranteed Lipschitz continuity property for the output layer. Lifted neural networks explicitly optimize an energy model to infer the unit activations and therefore---in contrast to standard feed-forward neural networks---allow bidirectional feedback between layers. So far lifted neural networks have been modelled around standard feed-forward architectures. We propose to take further advantage of the feedback property by letting the layers simultaneously perform regression and reconstruction. The resulting lifted network architecture allows to control the desired amount of Lipschitz continuity, which is an important feature to obtain adversarially robust regression and classification methods. We analyse and numerically demonstrate applications for unsupervised and supervised learning.
A Graduated Filter Method for Large Scale Robust Estimation
Mar 20, 2020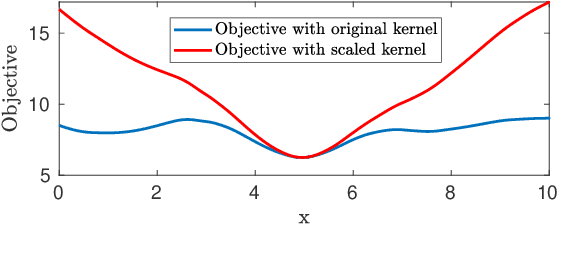
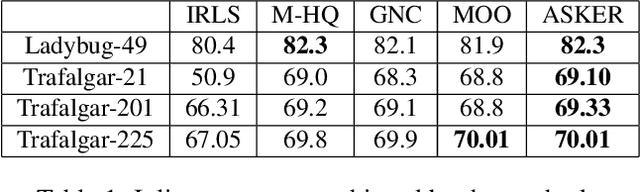
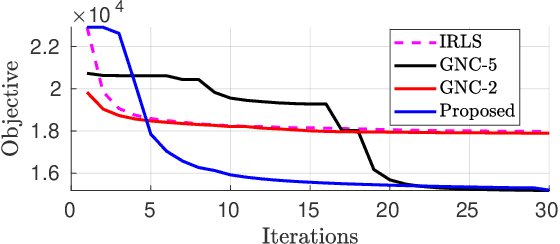
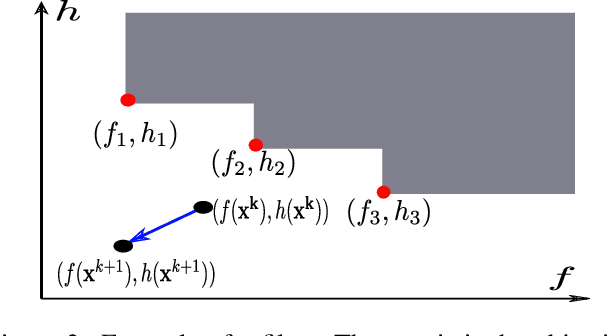
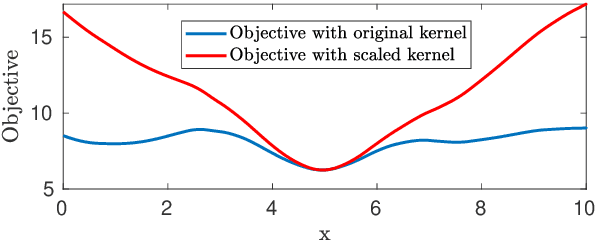
Due to the highly non-convex nature of large-scale robust parameter estimation, avoiding poor local minima is challenging in real-world applications where input data is contaminated by a large or unknown fraction of outliers. In this paper, we introduce a novel solver for robust estimation that possesses a strong ability to escape poor local minima. Our algorithm is built upon the class of traditional graduated optimization techniques, which are considered state-of-the-art local methods to solve problems having many poor minima. The novelty of our work lies in the introduction of an adaptive kernel (or residual) scaling scheme, which allows us to achieve faster convergence rates. Like other existing methods that aim to return good local minima for robust estimation tasks, our method relaxes the original robust problem but adapts a filter framework from non-linear constrained optimization to automatically choose the level of relaxation. Experimental results on real large-scale datasets such as bundle adjustment instances demonstrate that our proposed method achieves competitive results.
Truncated Inference for Latent Variable Optimization Problems: Application to Robust Estimation and Learning
Mar 12, 2020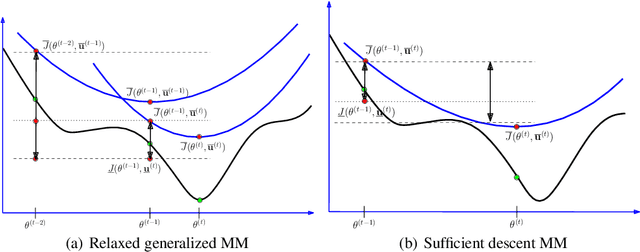

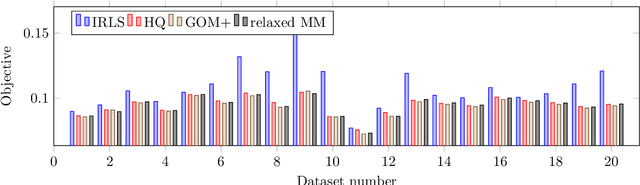

Optimization problems with an auxiliary latent variable structure in addition to the main model parameters occur frequently in computer vision and machine learning. The additional latent variables make the underlying optimization task expensive, either in terms of memory (by maintaining the latent variables), or in terms of runtime (repeated exact inference of latent variables). We aim to remove the need to maintain the latent variables and propose two formally justified methods, that dynamically adapt the required accuracy of latent variable inference. These methods have applications in large scale robust estimation and in learning energy-based models from labeled data.
Learning to generate new indoor scenes
Dec 10, 2019

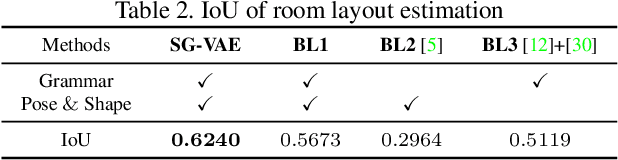
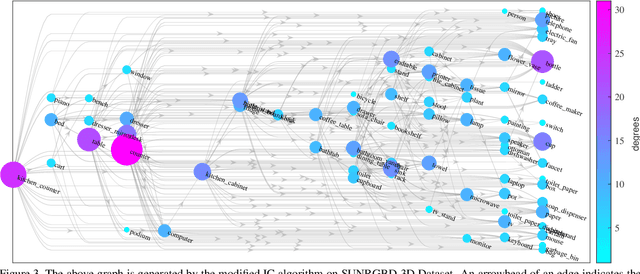
Deep generative models have been used in recent years to learn coherent latent representations in order to synthesize high quality images. In this work we propose a neural network to learn a generative model for sampling consistent indoor scene layouts. Our method learns the co-occurrences, and appearance parameters such as shape and pose, for different objects categories through a grammar-based auto-encoder, resulting in a compact and accurate representation for scene layouts. In contrast to existing grammar-based methods with a user-specified grammar, we construct the grammar automatically by extracting a set of production rules on reasoning about object co-occurrences in training data. The extracted grammar is able to represent a scene by an augmented parse tree. The proposed auto-encoder encodes these parse trees to a latent code, and decodes the latent code to a parse-tree, thereby ensuring the generated scene is always valid. We experimentally demonstrate that the proposed auto-encoder learns not only to generate valid scenes (i.e. the arrangements and appearances of objects), but it also learns coherent latent representations where nearby latent samples decode to similar scene outputs. The obtained generative model is applicable to several computer vision tasks such as 3D pose and layout estimation from RGB-D data.
Monocular 3D Object Detection and Box Fitting Trained End-to-End Using Intersection-over-Union Loss
Jun 20, 2019
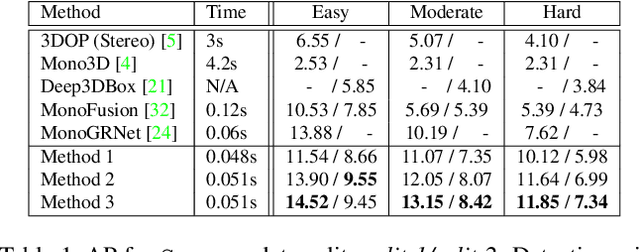
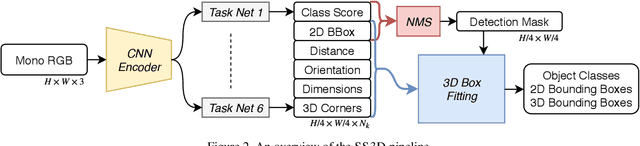
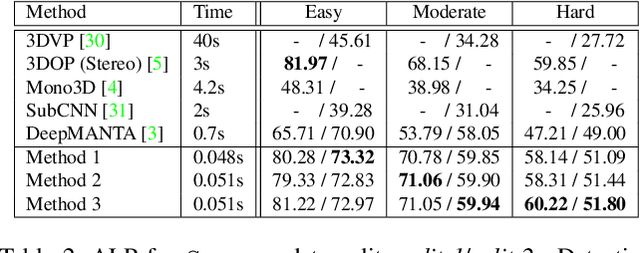
Three-dimensional object detection from a single view is a challenging task which, if performed with good accuracy, is an important enabler of low-cost mobile robot perception. Previous approaches to this problem suffer either from an overly complex inference engine or from an insufficient detection accuracy. To deal with these issues, we present SS3D, a single-stage monocular 3D object detector. The framework consists of (i) a CNN, which outputs a redundant representation of each relevant object in the image with corresponding uncertainty estimates, and (ii) a 3D bounding box optimizer. We show how modeling heteroscedastic uncertainty improves performance upon our baseline, and furthermore, how back-propagation can be done through the optimizer in order to train the pipeline end-to-end for additional accuracy. Our method achieves SOTA accuracy on monocular 3D object detection, while running at 20 fps in a straightforward implementation. We argue that the SS3D architecture provides a solid framework upon which high performing detection systems can be built, with autonomous driving being the main application in mind.
Seeing Behind Things: Extending Semantic Segmentation to Occluded Regions
Jun 07, 2019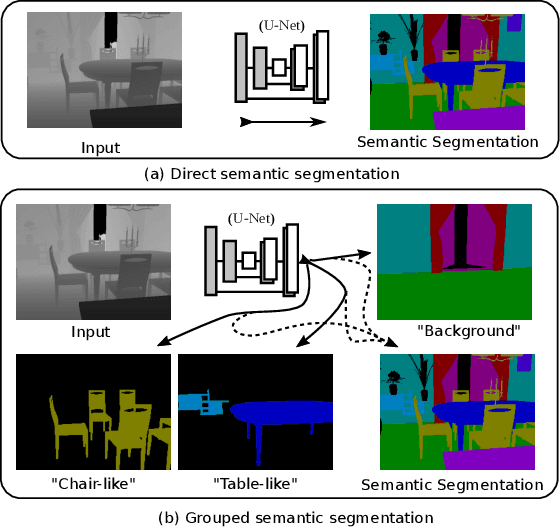

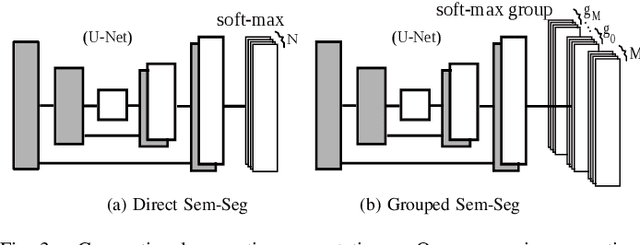

Semantic segmentation and instance level segmentation made substantial progress in recent years due to the emergence of deep neural networks (DNNs). A number of deep architectures with Convolution Neural Networks (CNNs) were proposed that surpass the traditional machine learning approaches for segmentation by a large margin. These architectures predict the directly observable semantic category of each pixel by usually optimizing a cross entropy loss. In this work we push the limit of semantic segmentation towards predicting semantic labels of directly visible as well as occluded objects or objects parts, where the network's input is a single depth image. We group the semantic categories into one background and multiple foreground object groups, and we propose a modification of the standard cross-entropy loss to cope with the settings. In our experiments we demonstrate that a CNN trained by minimizing the proposed loss is able to predict semantic categories for visible and occluded object parts without requiring to increase the network size (compared to a standard segmentation task). The results are validated on a newly generated dataset (augmented from SUNCG) dataset.
Contrastive Learning for Lifted Networks
May 07, 2019
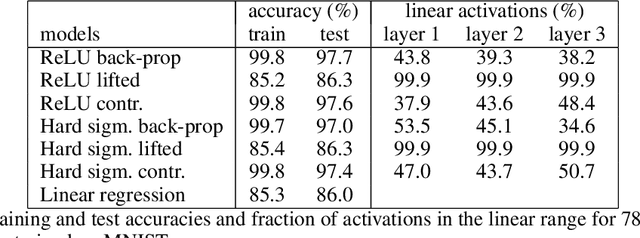
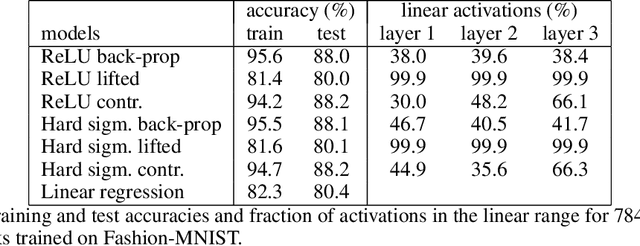
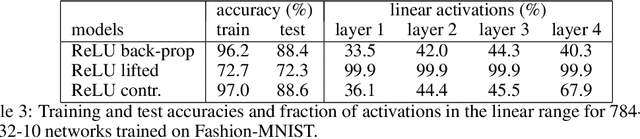
In this work we address supervised learning via lifted network formulations. Lifted networks are interesting because they allow training on massively parallel hardware and assign energy models to discriminatively trained neural networks. We demonstrate that training methods for lifted networks proposed in the literature have significant limitations, and therefore we propose to use a contrastive loss to train lifted networks. We show that this contrastive training approximates back-propagation in theory and in practice, and that it is superior to the regular training objective for lifted networks.