 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergent discourse between protests and counter-protests: #BlackLivesMatter and #AllLivesMatter
May 20, 2017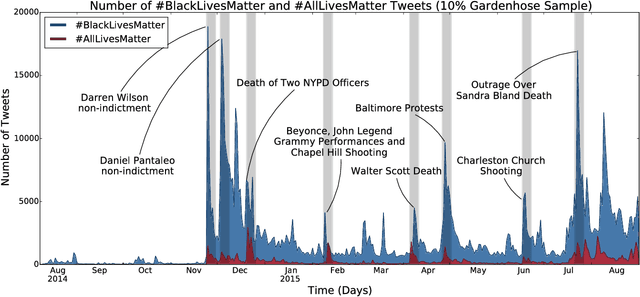
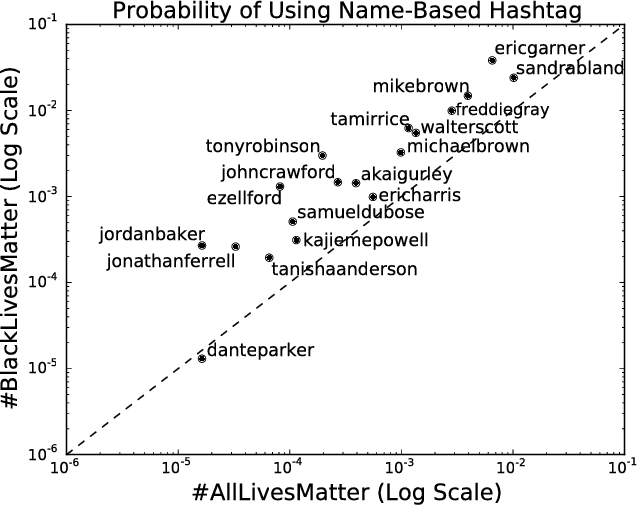
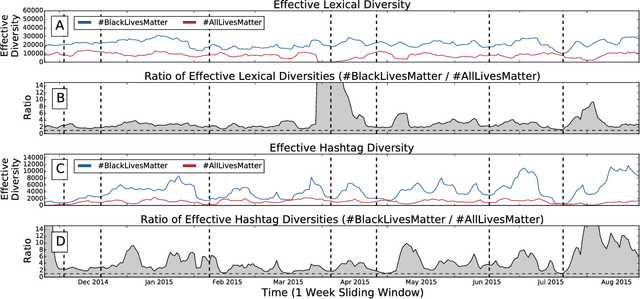
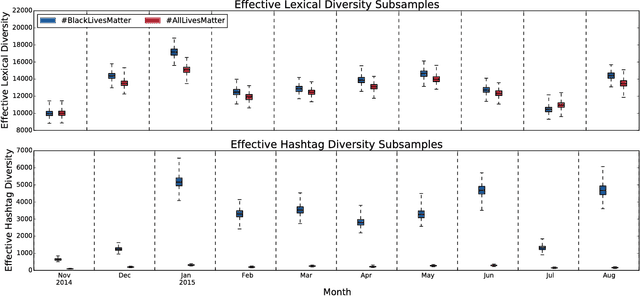
Since the shooting of Black teenager Michael Brown by White police officer Darren Wilson in Ferguson, Missouri, the protest hashtag #BlackLivesMatter has amplified critiques of extrajudicial killings of Black Americans. In response to #BlackLivesMatter, other Twitter users have adopted #AllLivesMatter, a counter-protest hashtag whose content argues that equal attention should be given to all lives regardless of race. Through a multi-level analysis of over 860,000 tweets, we study how these protests and counter-protests diverge by quantifying aspects of their discourse. We find that #AllLivesMatter facilitates opposition between #BlackLivesMatter and hashtags such as #PoliceLivesMatter and #BlueLivesMatter in such a way that historically echoes the tension between Black protesters and law enforcement. In addition, we show that a significant portion of #AllLivesMatter use stems from hijacking by #BlackLivesMatter advocates. Beyond simply injecting #AllLivesMatter with #BlackLivesMatter content, these hijackers use the hashtag to directly confront the counter-protest notion of "All lives matter." Our findings suggest that Black Lives Matter movement was able to grow, exhibit diverse conversations, and avoid derailment on social media by making discussion of counter-protest opinions a central topic of #AllLivesMatter, rather than the movement itself.
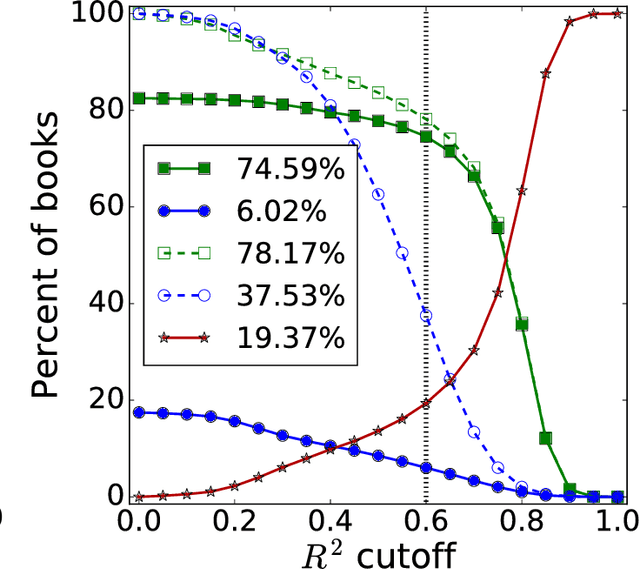
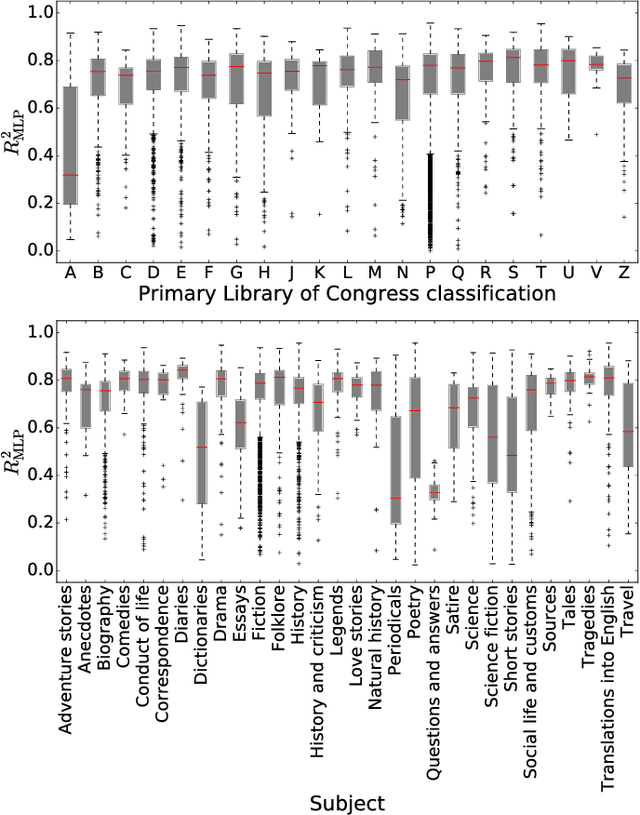
Characterizing the Google Books corpus: Strong limits to inferences of socio-cultural and linguistic evolution
Mar 24, 2017


It is tempting to treat frequency trends from the Google Books data sets as indicators of the "true" popularity of various words and phrases. Doing so allows us to draw quantitatively strong conclusions about the evolution of cultural perception of a given topic, such as time or gender. However, the Google Books corpus suffers from a number of limitations which make it an obscure mask of cultural popularity. A primary issue is that the corpus is in effect a library, containing one of each book. A single, prolific author is thereby able to noticeably insert new phrases into the Google Books lexicon, whether the author is widely read or not. With this understood, the Google Books corpus remains an important data set to be considered more lexicon-like than text-like. Here, we show that a distinct problematic feature arises from the inclusion of scientific texts, which have become an increasingly substantive portion of the corpus throughout the 1900s. The result is a surge of phrases typical to academic articles but less common in general, such as references to time in the form of citations. We highlight these dynamics by examining and comparing major contributions to the statistical divergence of English data sets between decades in the period 1800--2000. We find that only the English Fiction data set from the second version of the corpus is not heavily affected by professional texts, in clear contrast to the first version of the fiction data set and both unfiltered English data sets. Our findings emphasize the need to fully characterize the dynamics of the Google Books corpus before using these data sets to draw broad conclusions about cultural and linguistic evolution.
Is language evolution grinding to a halt? The scaling of lexical turbulence in English fiction suggests it is not
Mar 24, 2017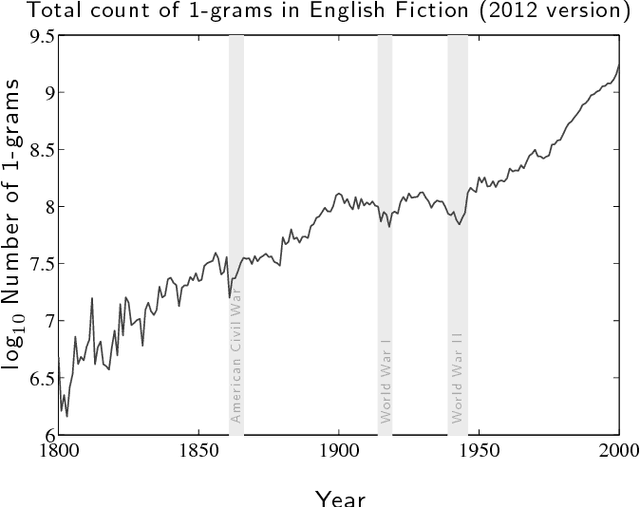
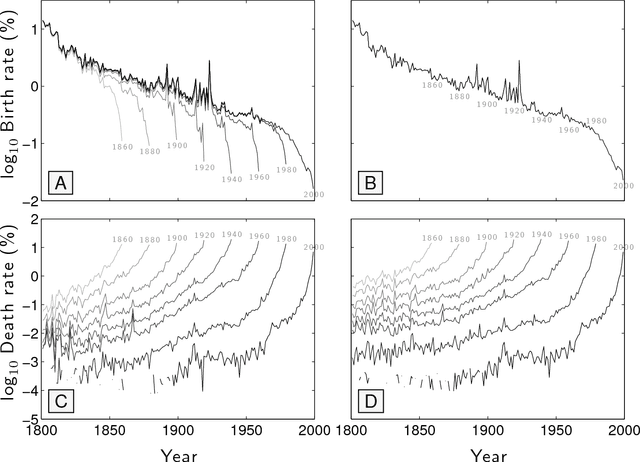
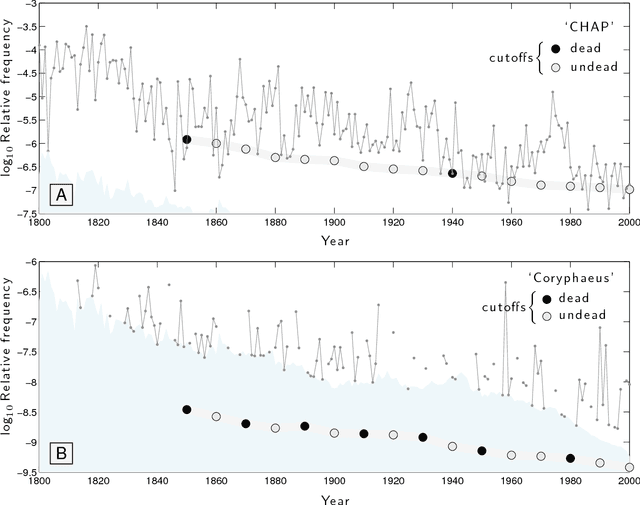
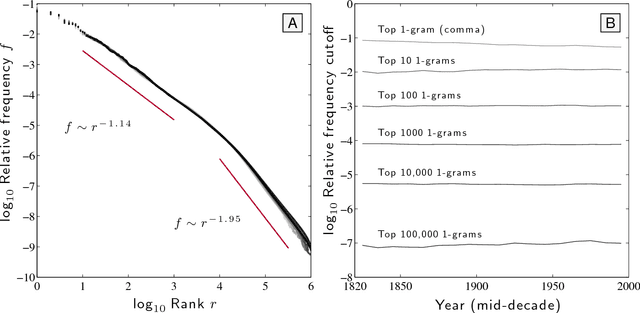
Of basic interest is the quantification of the long term growth of a language's lexicon as it develops to more completely cover both a culture's communication requirements and knowledge space. Here, we explore the usage dynamics of words in the English language as reflected by the Google Books 2012 English Fiction corpus. We critique an earlier method that found decreasing birth and increasing death rates of words over the second half of the 20th Century, showing death rates to be strongly affected by the imposed time cutoff of the arbitrary present and not increasing dramatically. We provide a robust, principled approach to examining lexical evolution by tracking the volume of word flux across various relative frequency thresholds. We show that while the overall statistical structure of the English language remains stable over time in terms of its raw Zipf distribution, we find evidence of an enduring `lexical turbulence': The flux of words across frequency thresholds from decade to decade scales superlinearly with word rank and exhibits a scaling break we connect to that of Zipf's law. To better understand the changing lexicon, we examine the contributions to the Jensen-Shannon divergence of individual words crossing frequency thresholds. We also find indications that scholarly works about fiction are strongly represented in the 2012 English Fiction corpus, and suggest that a future revision of the corpus should attempt to separate critical works from fiction itself.
The emotional arcs of stories are dominated by six basic shapes
Sep 26, 2016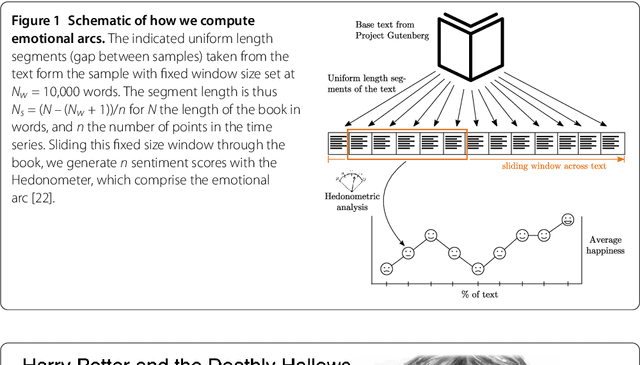
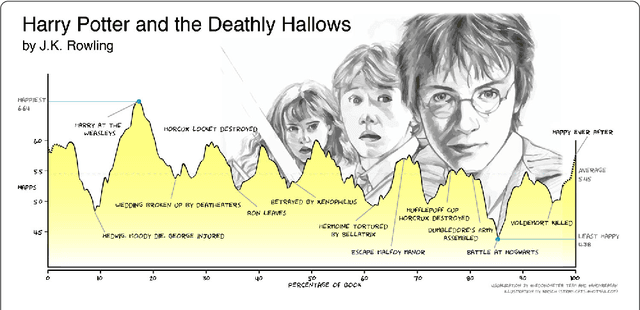
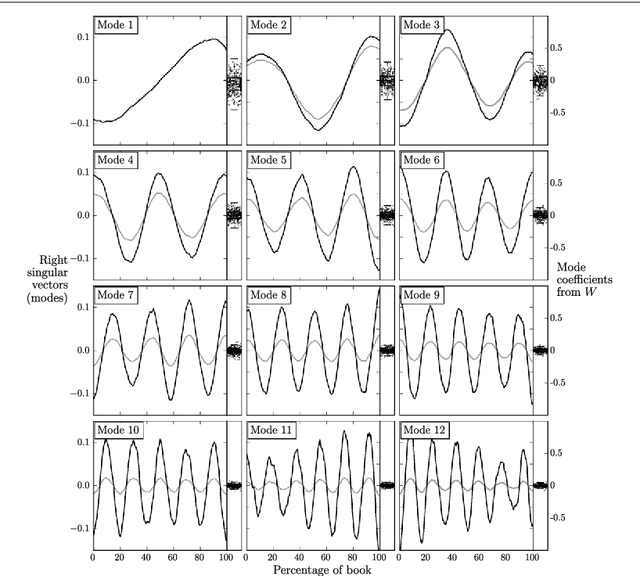
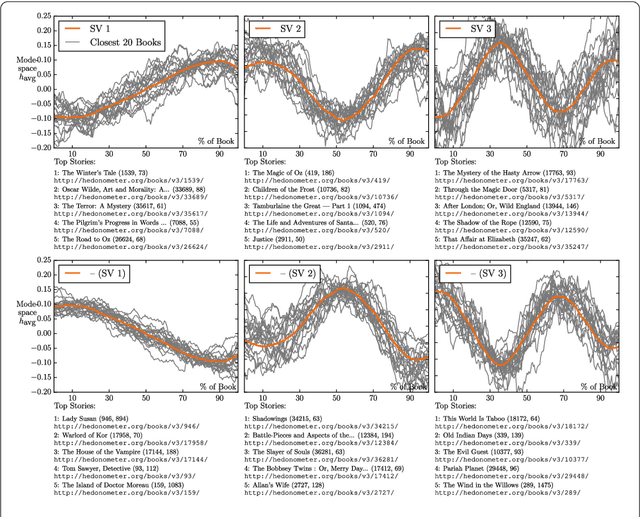
Advances in computing power, natural language processing, and digitization of text now make it possible to study a culture's evolution through its texts using a "big data" lens. Our ability to communicate relies in part upon a shared emotional experience, with stories often following distinct emotional trajectories and forming patterns that are meaningful to us. Here, by classifying the emotional arcs for a filtered subset of 1,327 stories from Project Gutenberg's fiction collection, we find a set of six core emotional arcs which form the essential building blocks of complex emotional trajectories. We strengthen our findings by separately applying Matrix decomposition, supervised learning, and unsupervised learning. For each of these six core emotional arcs, we examine the closest characteristic stories in publication today and find that particular emotional arcs enjoy greater success, as measured by downloads.
Benchmarking sentiment analysis methods for large-scale texts: A case for using continuum-scored words and word shift graphs
Sep 07, 2016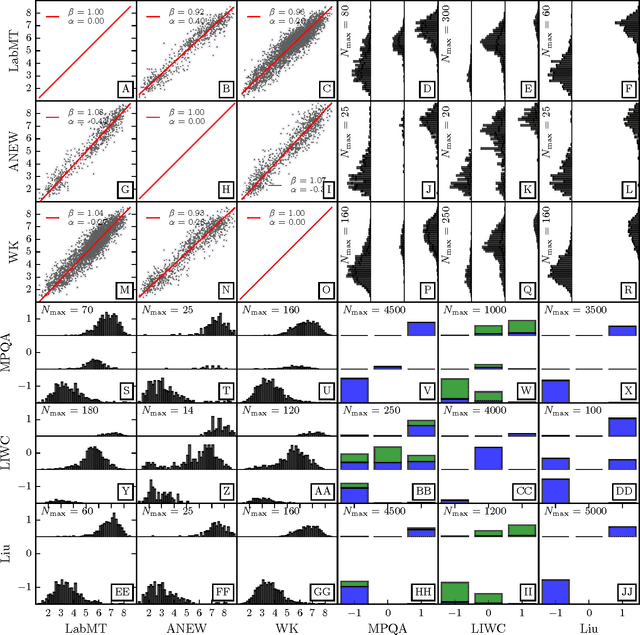
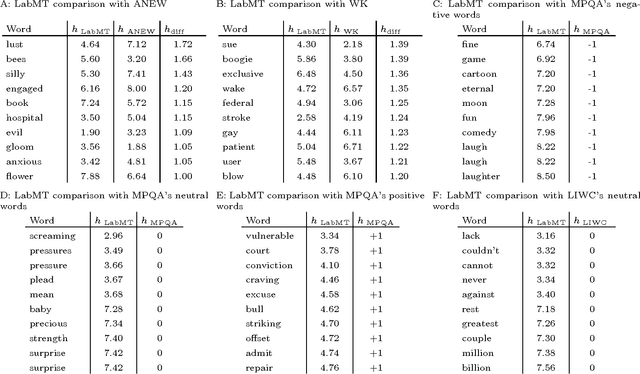
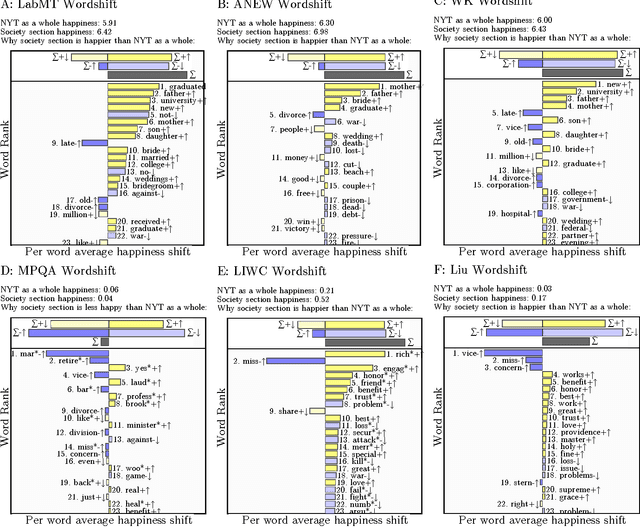
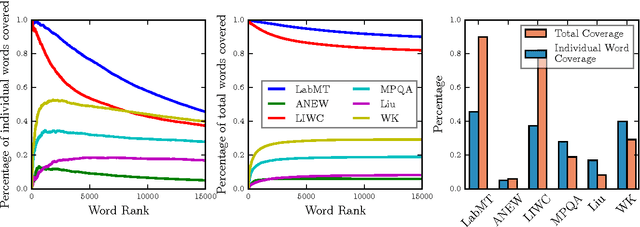
The emergence and global adoption of social media has rendered possible the real-time estimation of population-scale sentiment, bearing profound implications for our understanding of human behavior. Given the growing assortment of sentiment measuring instruments, comparisons between them are evidently required. Here, we perform detailed tests of 6 dictionary-based methods applied to 4 different corpora, and briefly examine a further 20 methods. We show that a dictionary-based method will only perform both reliably and meaningfully if (1) the dictionary covers a sufficiently large enough portion of a given text's lexicon when weighted by word usage frequency; and (2) words are scored on a continuous scale.
Zipf's law is a consequence of coherent language production
Aug 05, 2016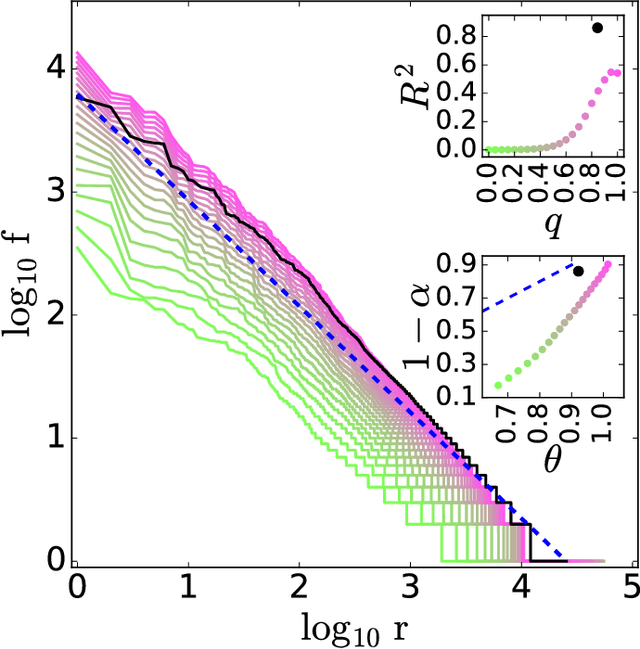
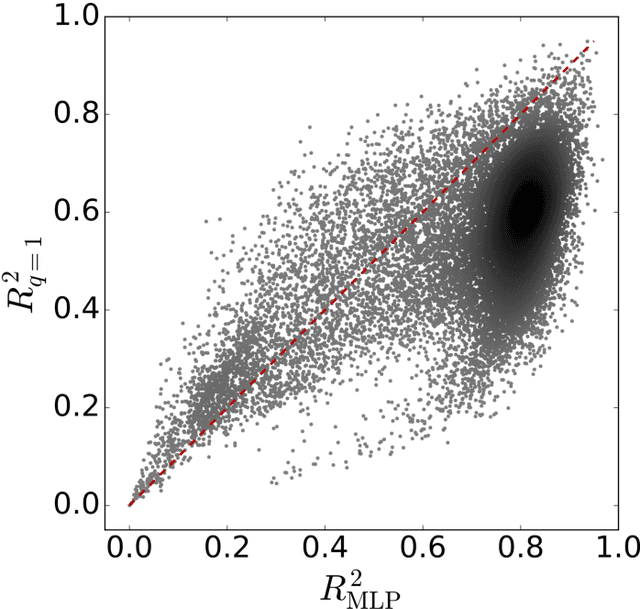
The task of text segmentation may be undertaken at many levels in text analysis---paragraphs, sentences, words, or even letters. Here, we focus on a relatively fine scale of segmentation, hypothesizing it to be in accord with a stochastic model of language generation, as the smallest scale where independent units of meaning are produced. Our goals in this letter include the development of methods for the segmentation of these minimal independent units, which produce feature-representations of texts that align with the independence assumption of the bag-of-terms model, commonly used for prediction and classification in computational text analysis. We also propose the measurement of texts' association (with respect to realized segmentations) to the model of language generation. We find (1) that our segmentations of phrases exhibit much better associations to the generation model than words and (2), that texts which are well fit are generally topically homogeneous. Because our generative model produces Zipf's law, our study further suggests that Zipf's law may be a consequence of homogeneity in language production.
Sifting Robotic from Organic Text: A Natural Language Approach for Detecting Automation on Twitter
Jun 14, 2016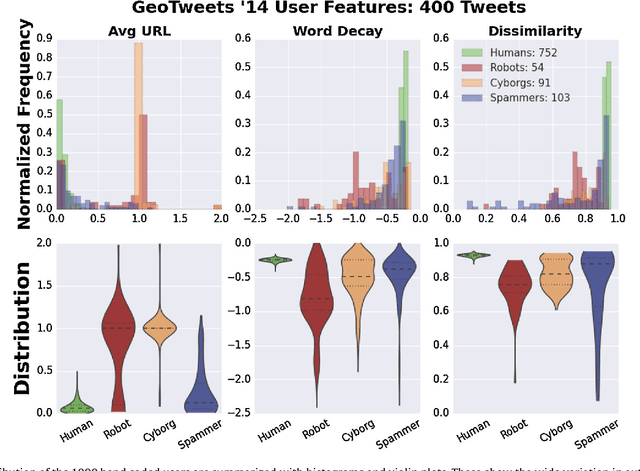
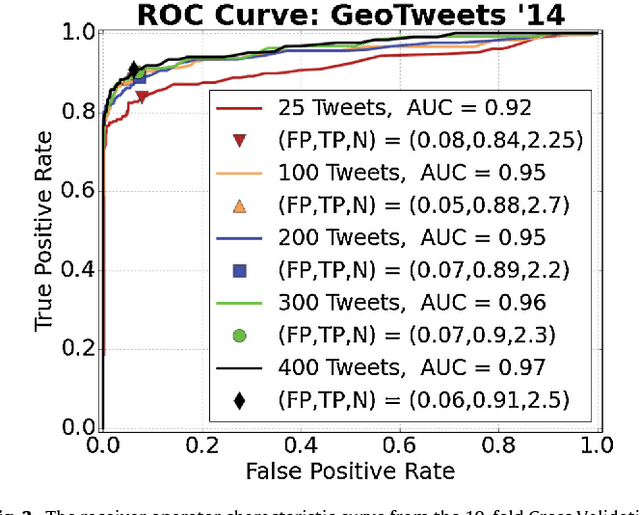
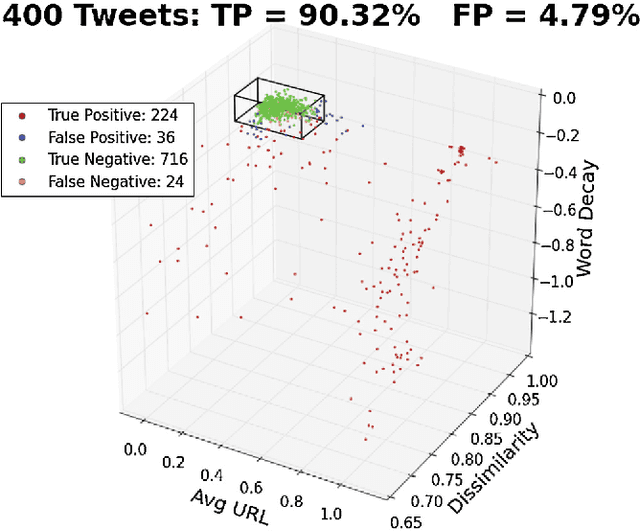
Twitter, a popular social media outlet, has evolved into a vast source of linguistic data, rich with opinion, sentiment, and discussion. Due to the increasing popularity of Twitter, its perceived potential for exerting social influence has led to the rise of a diverse community of automatons, commonly referred to as bots. These inorganic and semi-organic Twitter entities can range from the benevolent (e.g., weather-update bots, help-wanted-alert bots) to the malevolent (e.g., spamming messages, advertisements, or radical opinions). Existing detection algorithms typically leverage meta-data (time between tweets, number of followers, etc.) to identify robotic accounts. Here, we present a powerful classification scheme that exclusively uses the natural language text from organic users to provide a criterion for identifying accounts posting automated messages. Since the classifier operates on text alone, it is flexible and may be applied to any textual data beyond the Twitter-sphere.
What we write about when we write about causality: Features of causal statements across large-scale social discourse
Apr 21, 2016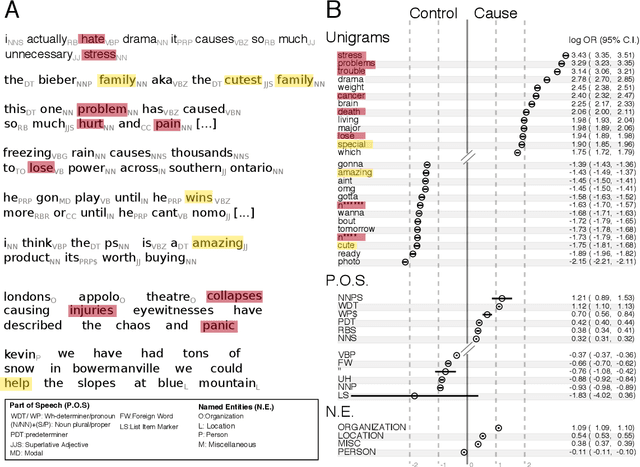
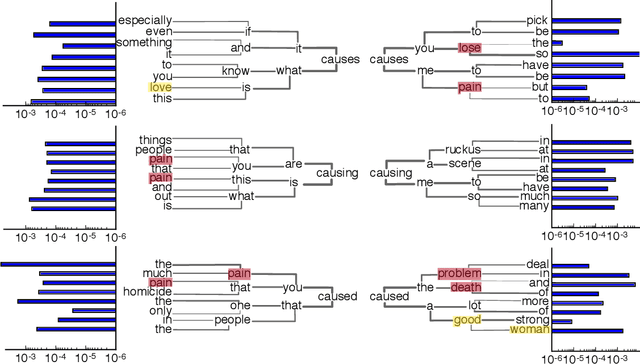
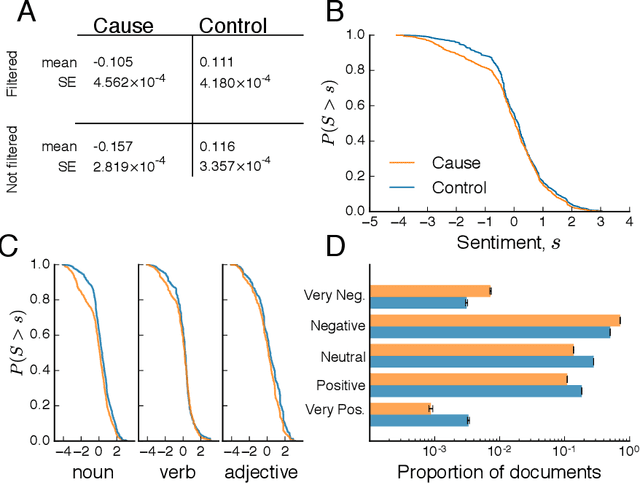
Identifying and communicating relationships between causes and effects is important for understanding our world, but is affected by language structure, cognitive and emotional biases, and the properties of the communication medium. Despite the increasing importance of social media, much remains unknown about causal statements made online. To study real-world causal attribution, we extract a large-scale corpus of causal statements made on the Twitter social network platform as well as a comparable random control corpus. We compare causal and control statements using statistical language and sentiment analysis tools. We find that causal statements have a number of significant lexical and grammatical differences compared with controls and tend to be more negative in sentiment than controls. Causal statements made online tend to focus on news and current events, medicine and health, or interpersonal relationships, as shown by topic models. By quantifying the features and potential biases of causality communication, this study improves our understanding of the accuracy of information and opinions found online.
Nonlinear functional mapping of the human brain
Sep 08, 2015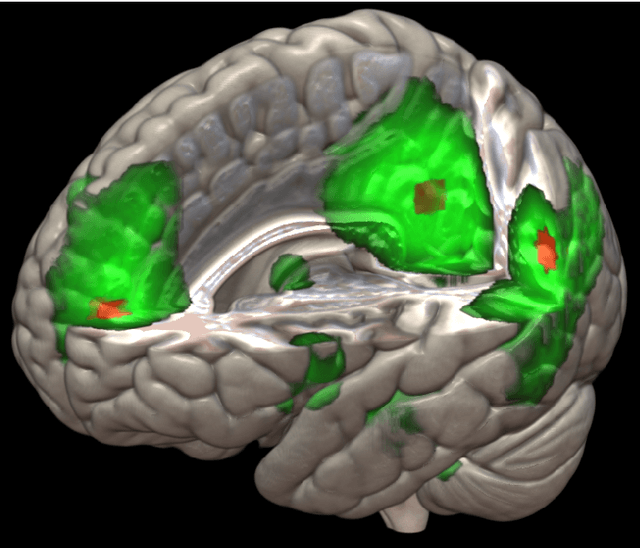
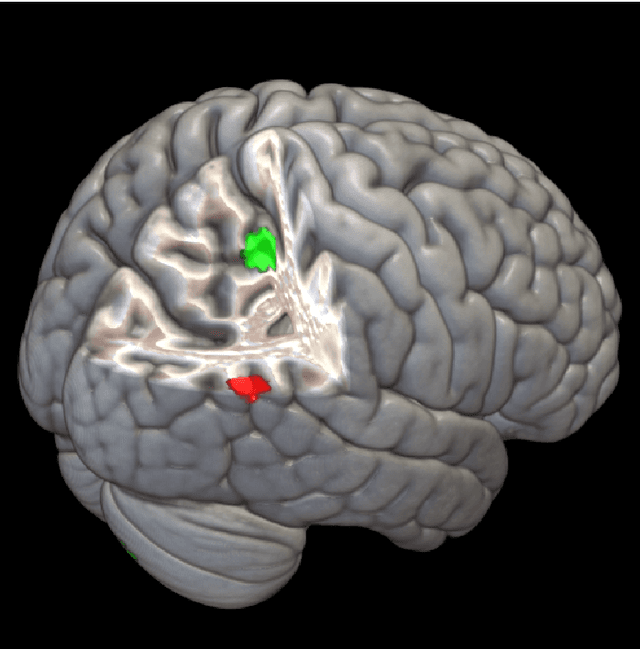
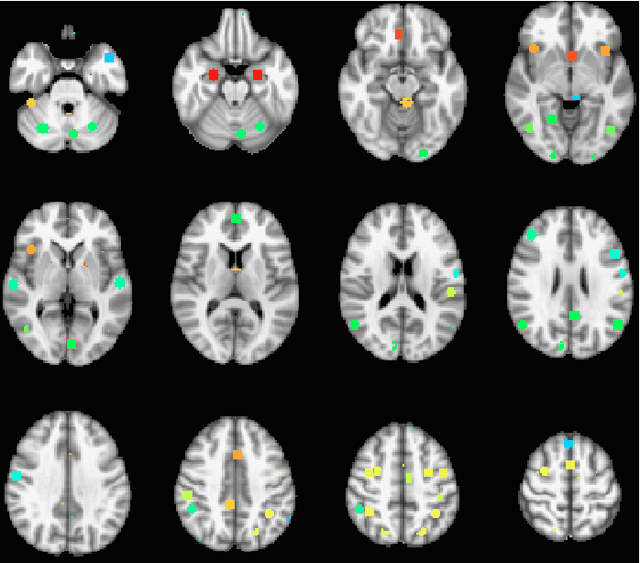
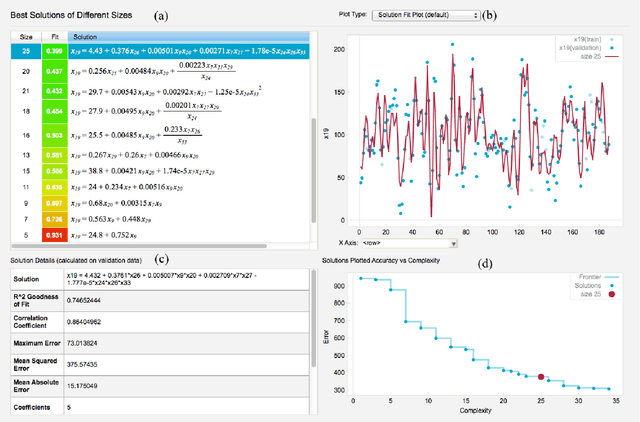
The field of neuroimaging has truly become data rich, and novel analytical methods capable of gleaning meaningful information from large stores of imaging data are in high demand. Those methods that might also be applicable on the level of individual subjects, and thus potentially useful clinically, are of special interest. In the present study, we introduce just such a method, called nonlinear functional mapping (NFM), and demonstrate its application in the analysis of resting state fMRI from a 242-subject subset of the IMAGEN project, a European study of adolescents that includes longitudinal phenotypic, behavioral, genetic, and neuroimaging data. NFM employs a computational technique inspired by biological evolution to discover and mathematically characterize interactions among ROI (regions of interest), without making linear or univariate assumptions. We show that statistics of the resulting interaction relationships comport with recent independent work, constituting a preliminary cross-validation. Furthermore, nonlinear terms are ubiquitous in the models generated by NFM, suggesting that some of the interactions characterized here are not discoverable by standard linear methods of analysis. We discuss one such nonlinear interaction in the context of a direct comparison with a procedure involving pairwise correlation, designed to be an analogous linear version of functional mapping. We find another such interaction that suggests a novel distinction in brain function between drinking and non-drinking adolescents: a tighter coupling of ROI associated with emotion, reward, and interoceptive processes such as thirst, among drinkers. Finally, we outline many improvements and extensions of the methodology to reduce computational expense, complement other analytical tools like graph-theoretic analysis, and allow for voxel level NFM to eliminate the necessity of ROI selection.
Identifying missing dictionary entries with frequency-conserving context models
Jul 29, 2015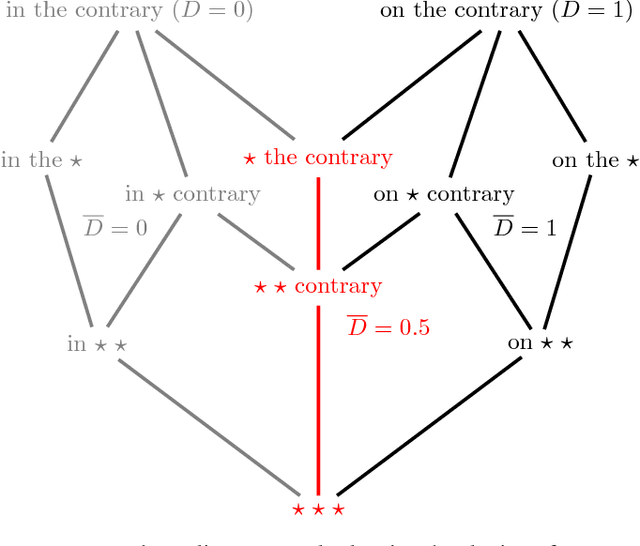
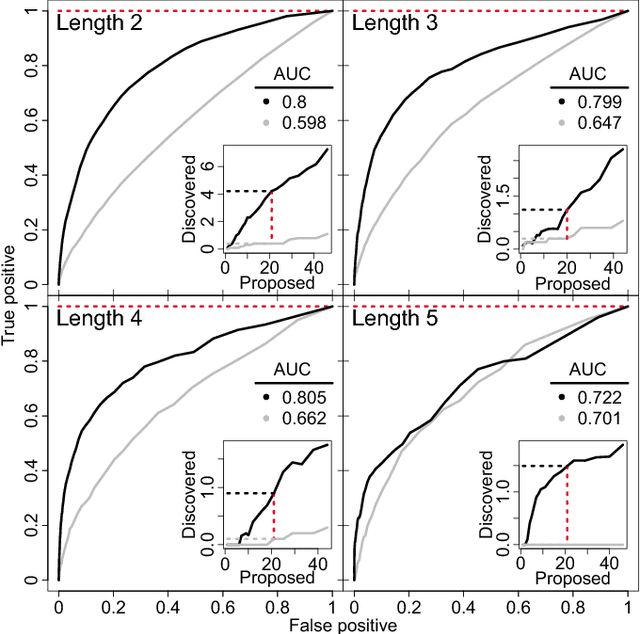
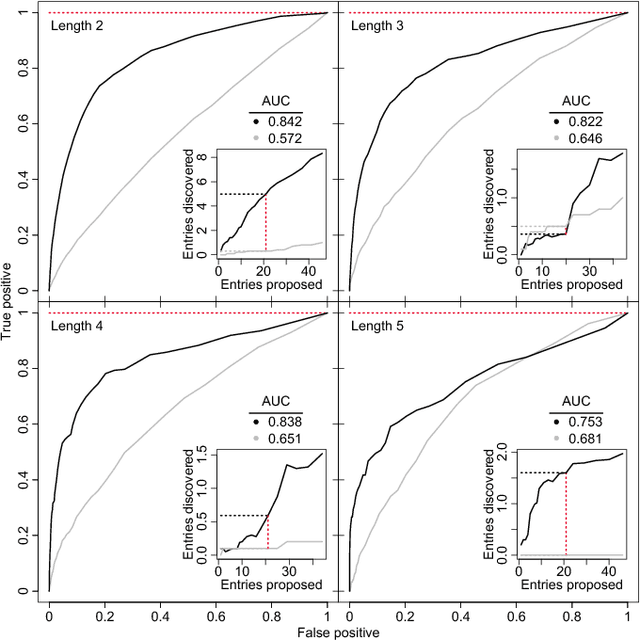
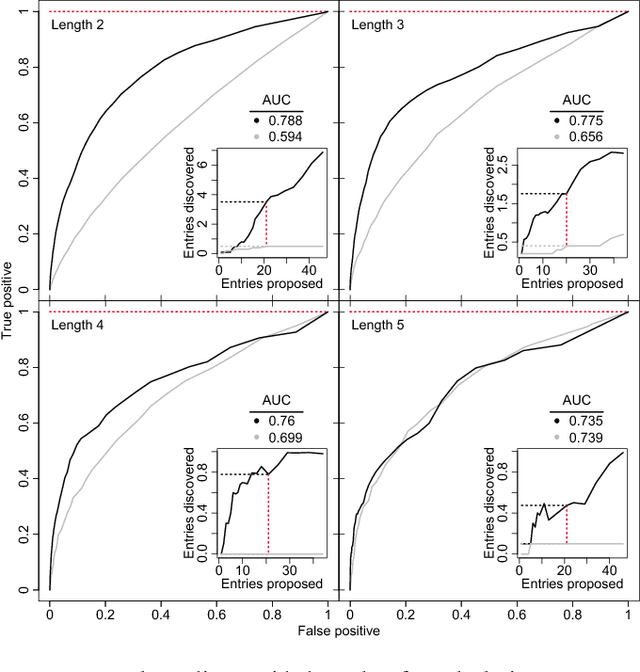
In an effort to better understand meaning from natural language texts, we explore methods aimed at organizing lexical objects into contexts. A number of these methods for organization fall into a family defined by word ordering. Unlike demographic or spatial partitions of data, these collocation models are of special importance for their universal applicability. While we are interested here in text and have framed our treatment appropriately, our work is potentially applicable to other areas of research (e.g., speech, genomics, and mobility patterns) where one has ordered categorical data, (e.g., sounds, genes, and locations). Our approach focuses on the phrase (whether word or larger) as the primary meaning-bearing lexical unit and object of study. To do so, we employ our previously developed framework for generating word-conserving phrase-frequency data. Upon training our model with the Wiktionary---an extensive, online, collaborative, and open-source dictionary that contains over 100,000 phrasal-definitions---we develop highly effective filters for the identification of meaningful, missing phrase-entries. With our predictions we then engage the editorial community of the Wiktionary and propose short lists of potential missing entries for definition, developing a breakthrough, lexical extraction technique, and expanding our knowledge of the defined English lexicon of phrases.