 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning aided Computer Architecture Design for CNN Inferencing Systems
Aug 10, 2023Efficient and timely calculations of Machine Learning (ML) algorithms are essential for emerging technologies like autonomous driving, the Internet of Things (IoT), and edge computing. One of the primary ML algorithms used in such systems is Convolutional Neural Networks (CNNs), which demand high computational resources. This requirement has led to the use of ML accelerators like GPGPUs to meet design constraints. However, selecting the most suitable accelerator involves Design Space Exploration (DSE), a process that is usually time-consuming and requires significant manual effort. Our work presents approaches to expedite the DSE process by identifying the most appropriate GPGPU for CNN inferencing systems. We have developed a quick and precise technique for forecasting the power and performance of CNNs during inference, with a MAPE of 5.03% and 5.94%, respectively. Our approach empowers computer architects to estimate power and performance in the early stages of development, reducing the necessity for numerous prototypes. This saves time and money while also improving the time-to-market period.
Pick the Right Edge Device: Towards Power and Performance Estimation of CUDA-based CNNs on GPGPUs
Feb 02, 2021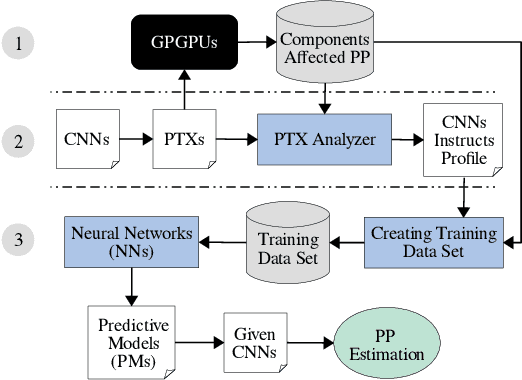

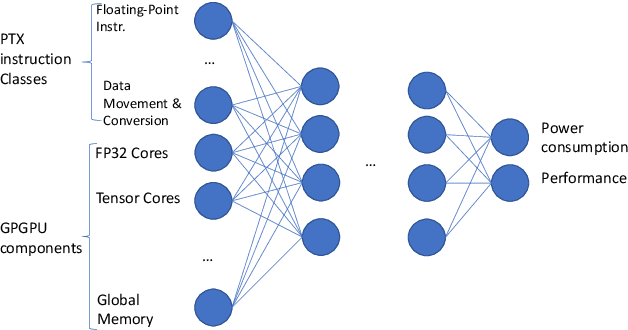

The emergence of Machine Learning (ML) as a powerful technique has been helping nearly all fields of business to increase operational efficiency or to develop new value propositions. Besides the challenges of deploying and maintaining ML models, picking the right edge device (e.g., GPGPUs) to run these models (e.g., CNN with the massive computational process) is one of the most pressing challenges faced by organizations today. As the cost of renting (on Cloud) or purchasing an edge device is directly connected to the cost of final products or services, choosing the most efficient device is essential. However, this decision making requires deep knowledge about performance and power consumption of the ML models running on edge devices that must be identified at the early stage of ML workflow. In this paper, we present a novel ML-based approach that provides ML engineers with the early estimation of both power consumption and performance of CUDA-based CNNs on GPGPUs. The proposed approach empowers ML engineers to pick the most efficient GPGPU for a given CNN model at the early stage of development.