 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Vector Spaces for Unsupervised Information Retrieval
Aug 18, 2018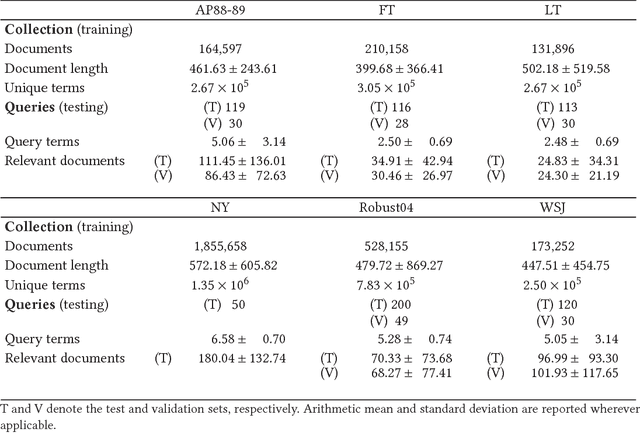
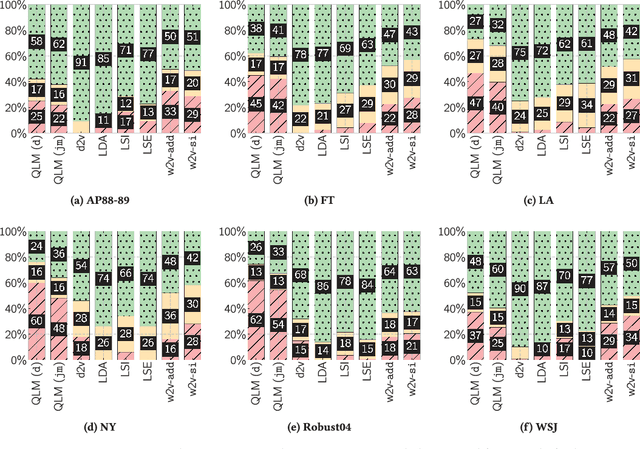
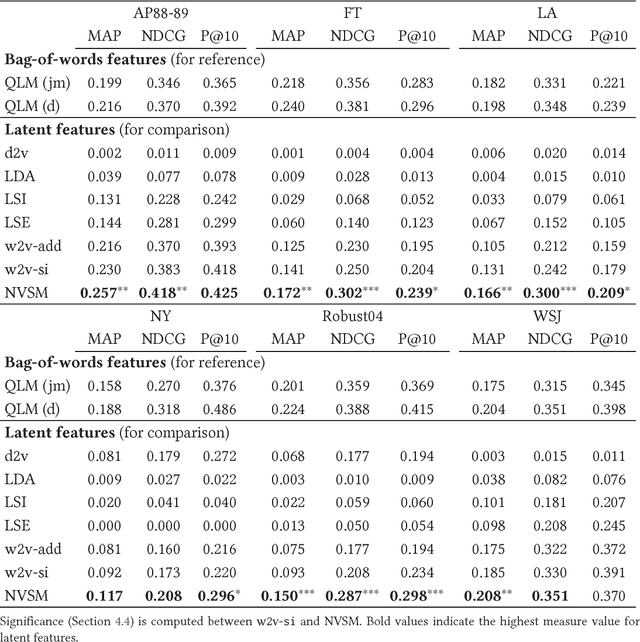
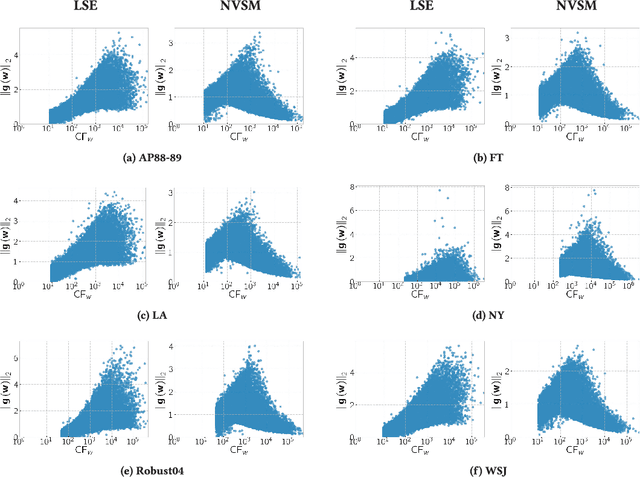
We propose the Neural Vector Space Model (NVSM), a method that learns representations of documents in an unsupervised manner for news article retrieval. In the NVSM paradigm, we learn low-dimensional representations of words and documents from scratch using gradient descent and rank documents according to their similarity with query representations that are composed from word representations. We show that NVSM performs better at document ranking than existing latent semantic vector space methods. The addition of NVSM to a mixture of lexical language models and a state-of-the-art baseline vector space model yields a statistically significant increase in retrieval effectiveness. Consequently, NVSM adds a complementary relevance signal. Next to semantic matching, we find that NVSM performs well in cases where lexical matching is needed. NVSM learns a notion of term specificity directly from the document collection without feature engineering. We also show that NVSM learns regularities related to Luhn significance. Finally, we give advice on how to deploy NVSM in situations where model selection (e.g., cross-validation) is infeasible. We find that an unsupervised ensemble of multiple models trained with different hyperparameter values performs better than a single cross-validated model. Therefore, NVSM can safely be used for ranking documents without supervised relevance judgments.
Reply With: Proactive Recommendation of Email Attachments
Nov 16, 2017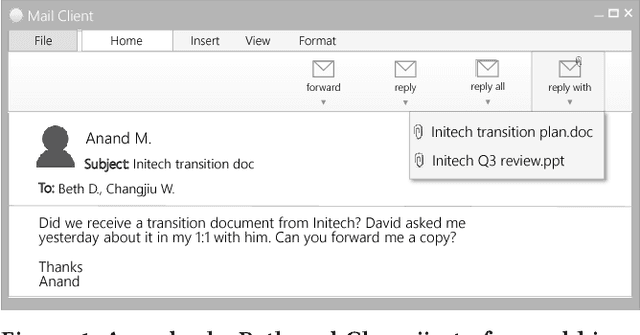
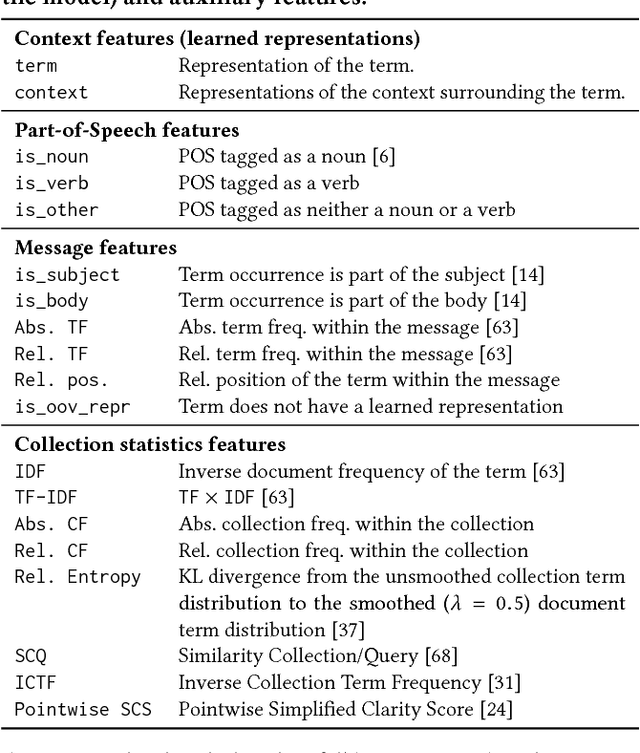
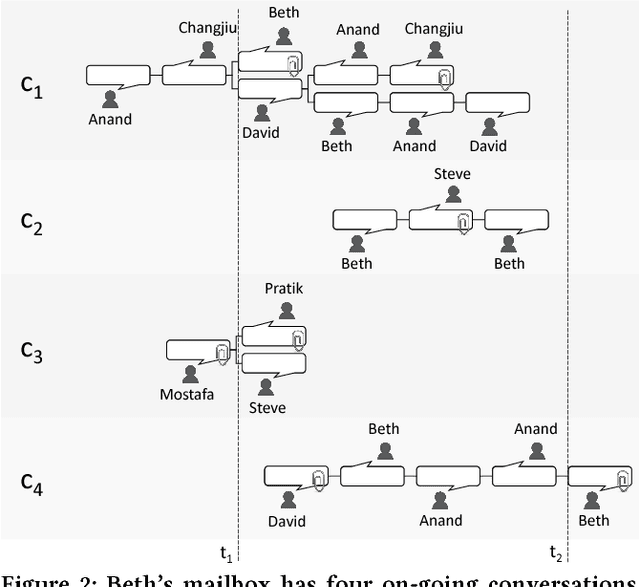
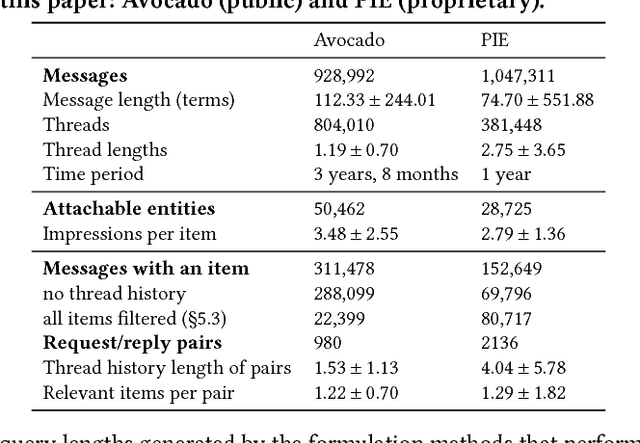
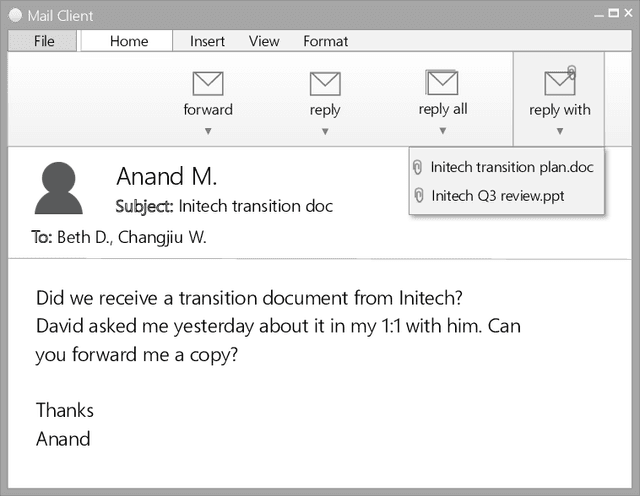
Email responses often contain items-such as a file or a hyperlink to an external document-that are attached to or included inline in the body of the message. Analysis of an enterprise email corpus reveals that 35% of the time when users include these items as part of their response, the attachable item is already present in their inbox or sent folder. A modern email client can proactively retrieve relevant attachable items from the user's past emails based on the context of the current conversation, and recommend them for inclusion, to reduce the time and effort involved in composing the response. In this paper, we propose a weakly supervised learning framework for recommending attachable items to the user. As email search systems are commonly available, we constrain the recommendation task to formulating effective search queries from the context of the conversations. The query is submitted to an existing IR system to retrieve relevant items for attachment. We also present a novel strategy for generating labels from an email corpus---without the need for manual annotations---that can be used to train and evaluate the query formulation model. In addition, we describe a deep convolutional neural network that demonstrates satisfactory performance on this query formulation task when evaluated on the publicly available Avocado dataset and a proprietary dataset of internal emails obtained through an employee participation program.
Remedies against the Vocabulary Gap in Information Retrieval
Nov 16, 2017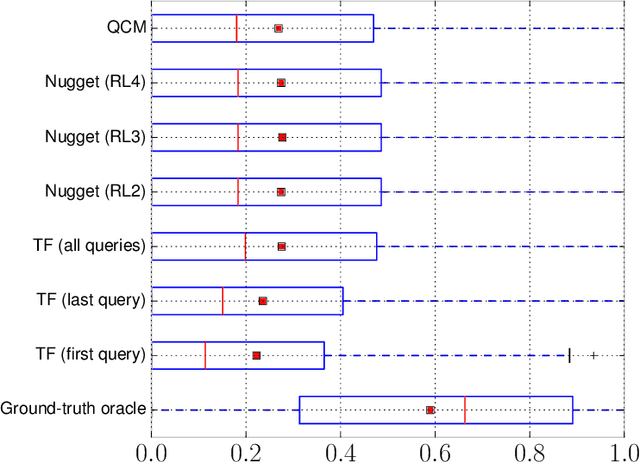
Search engines rely heavily on term-based approaches that represent queries and documents as bags of words. Text---a document or a query---is represented by a bag of its words that ignores grammar and word order, but retains word frequency counts. When presented with a search query, the engine then ranks documents according to their relevance scores by computing, among other things, the matching degrees between query and document terms. While term-based approaches are intuitive and effective in practice, they are based on the hypothesis that documents that exactly contain the query terms are highly relevant regardless of query semantics. Inversely, term-based approaches assume documents that do not contain query terms as irrelevant. However, it is known that a high matching degree at the term level does not necessarily mean high relevance and, vice versa, documents that match null query terms may still be relevant. Consequently, there exists a vocabulary gap between queries and documents that occurs when both use different words to describe the same concepts. It is the alleviation of the effect brought forward by this vocabulary gap that is the topic of this dissertation. More specifically, we propose (1) methods to formulate an effective query from complex textual structures and (2) latent vector space models that circumvent the vocabulary gap in information retrieval.
Unsupervised, Efficient and Semantic Expertise Retrieval
Sep 17, 2017
We introduce an unsupervised discriminative model for the task of retrieving experts in online document collections. We exclusively employ textual evidence and avoid explicit feature engineering by learning distributed word representations in an unsupervised way. We compare our model to state-of-the-art unsupervised statistical vector space and probabilistic generative approaches. Our proposed log-linear model achieves the retrieval performance levels of state-of-the-art document-centric methods with the low inference cost of so-called profile-centric approaches. It yields a statistically significant improved ranking over vector space and generative models in most cases, matching the performance of supervised methods on various benchmarks. That is, by using solely text we can do as well as methods that work with external evidence and/or relevance feedback. A contrastive analysis of rankings produced by discriminative and generative approaches shows that they have complementary strengths due to the ability of the unsupervised discriminative model to perform semantic matching.
Structural Regularities in Text-based Entity Vector Spaces
Jul 25, 2017
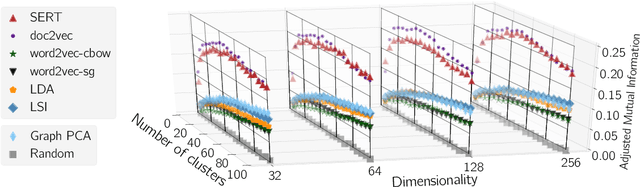
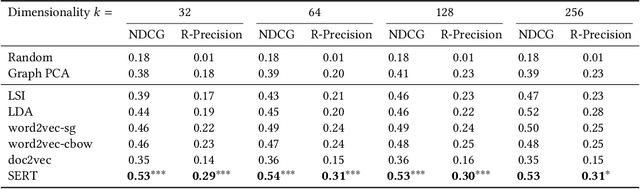

Entity retrieval is the task of finding entities such as people or products in response to a query, based solely on the textual documents they are associated with. Recent semantic entity retrieval algorithms represent queries and experts in finite-dimensional vector spaces, where both are constructed from text sequences. We investigate entity vector spaces and the degree to which they capture structural regularities. Such vector spaces are constructed in an unsupervised manner without explicit information about structural aspects. For concreteness, we address these questions for a specific type of entity: experts in the context of expert finding. We discover how clusterings of experts correspond to committees in organizations, the ability of expert representations to encode the co-author graph, and the degree to which they encode academic rank. We compare latent, continuous representations created using methods based on distributional semantics (LSI), topic models (LDA) and neural networks (word2vec, doc2vec, SERT). Vector spaces created using neural methods, such as doc2vec and SERT, systematically perform better at clustering than LSI, LDA and word2vec. When it comes to encoding entity relations, SERT performs best.
Semantic Entity Retrieval Toolkit
Jul 17, 2017
Unsupervised learning of low-dimensional, semantic representations of words and entities has recently gained attention. In this paper we describe the Semantic Entity Retrieval Toolkit (SERT) that provides implementations of our previously published entity representation models. The toolkit provides a unified interface to different representation learning algorithms, fine-grained parsing configuration and can be used transparently with GPUs. In addition, users can easily modify existing models or implement their own models in the framework. After model training, SERT can be used to rank entities according to a textual query and extract the learned entity/word representation for use in downstream algorithms, such as clustering or recommendation.
Neural Networks for Information Retrieval
Jul 13, 2017
Machine learning plays a role in many aspects of modern IR systems, and deep learning is applied in all of them. The fast pace of modern-day research has given rise to many different approaches for many different IR problems. The amount of information available can be overwhelming both for junior students and for experienced researchers looking for new research topics and directions. Additionally, it is interesting to see what key insights into IR problems the new technologies are able to give us. The aim of this full-day tutorial is to give a clear overview of current tried-and-trusted neural methods in IR and how they benefit IR research. It covers key architectures, as well as the most promising future directions.
Pyndri: a Python Interface to the Indri Search Engine
Jan 03, 2017We introduce pyndri, a Python interface to the Indri search engine. Pyndri allows to access Indri indexes from Python at two levels: (1) dictionary and tokenized document collection, (2) evaluating queries on the index. We hope that with the release of pyndri, we will stimulate reproducible, open and fast-paced IR research.
Learning Latent Vector Spaces for Product Search
Aug 25, 2016
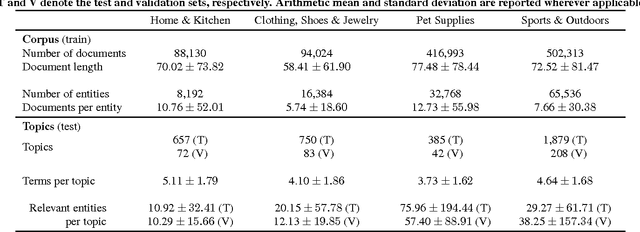
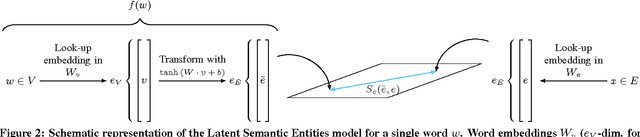

We introduce a novel latent vector space model that jointly learns the latent representations of words, e-commerce products and a mapping between the two without the need for explicit annotations. The power of the model lies in its ability to directly model the discriminative relation between products and a particular word. We compare our method to existing latent vector space models (LSI, LDA and word2vec) and evaluate it as a feature in a learning to rank setting. Our latent vector space model achieves its enhanced performance as it learns better product representations. Furthermore, the mapping from words to products and the representations of words benefit directly from the errors propagated back from the product representations during parameter estimation. We provide an in-depth analysis of the performance of our model and analyze the structure of the learned representations.
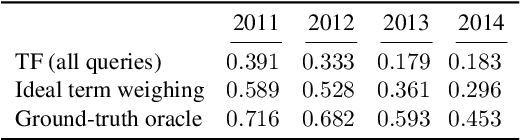
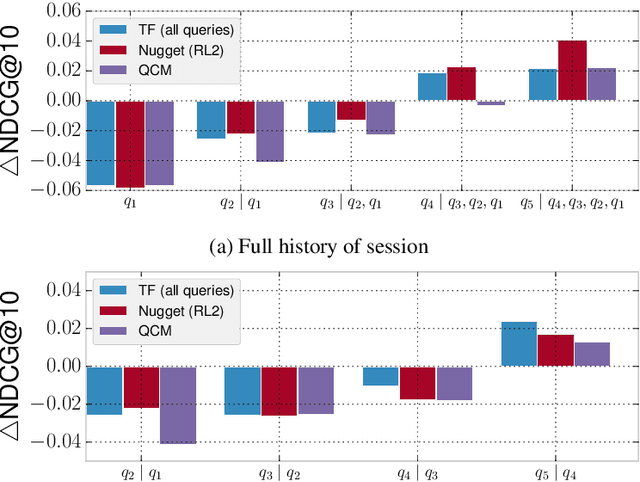
Lexical Query Modeling in Session Search
Aug 23, 2016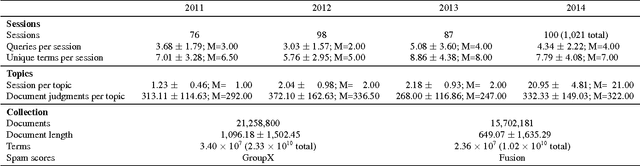
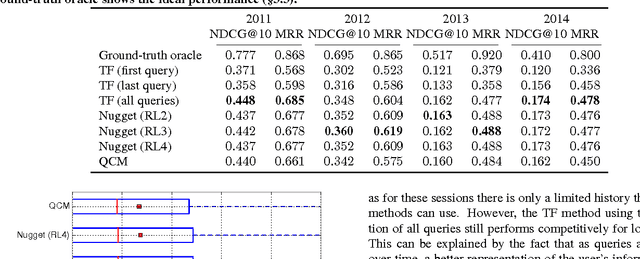
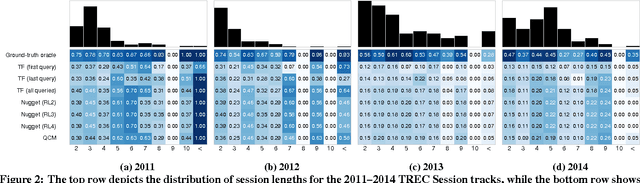
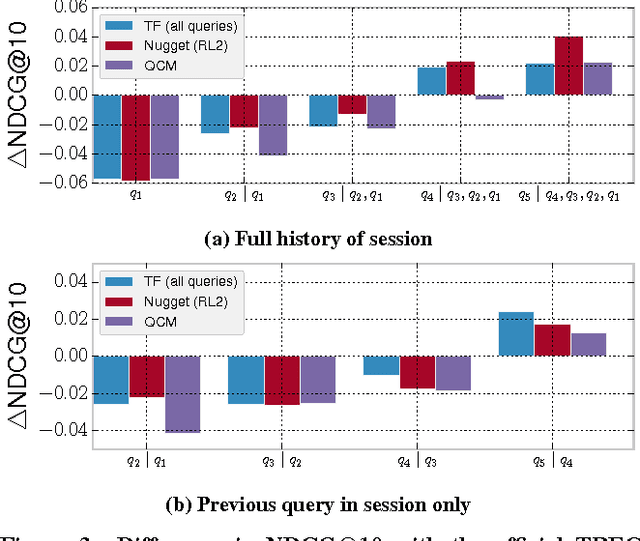
Lexical query modeling has been the leading paradigm for session search. In this paper, we analyze TREC session query logs and compare the performance of different lexical matching approaches for session search. Naive methods based on term frequency weighing perform on par with specialized session models. In addition, we investigate the viability of lexical query models in the setting of session search. We give important insights into the potential and limitations of lexical query modeling for session search and propose future directions for the field of session search.