 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowC2S: Flowing from Current to Succeeding Frames for Fast and Memory-Efficient Video Continuation
Apr 19, 2026This paper introduces a novel methodology for generating fast and memory-efficient video continuations. Our method, dubbed FlowC2S, fine-tunes a pre-trained text-to-video flow model to learn a vector field between the current and succeeding video chunks. Two design choices are key. First, we introduce inherent optimal couplings, utilizing temporally adjacent video chunks during training as a practical proxy for true optimal couplings, resulting in straighter flows. Second, we incorporate target inversion, injecting the inverted latent of the target chunk into the input representation to strengthen correspondences and improve visual fidelity. By flowing directly from current to succeeding frames, instead of the common combination of current frames with noise to generate a video continuation, we reduce the dimensionality of the model input by a factor of two. The proposed method, fine-tuned from LTXV and Wan, surpasses the state-of-the-art scores across quantitative evaluations with FID and FVD, with as few as five neural function evaluations.
Classifying Cycling Hazards in Egocentric Data
Mar 15, 2021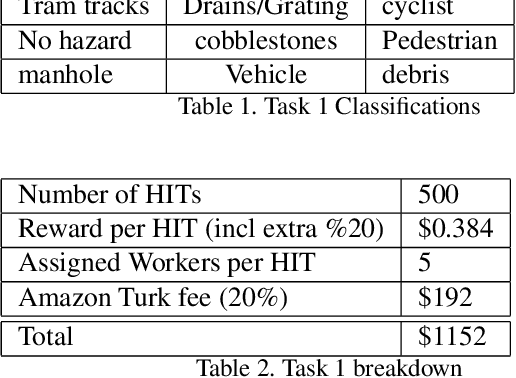

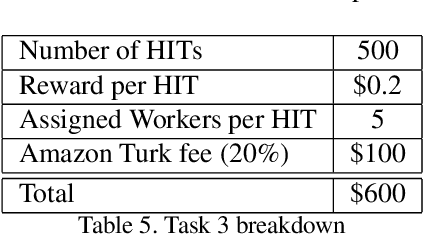
This proposal is for the creation and annotation of an egocentric video data set of hazardous cycling situations. The resulting data set will facilitate projects to improve the safety and experience of cyclists. Since cyclists are highly sensitive to road surface conditions and hazards they require more detail about road conditions when navigating their route. Features such as tram tracks, cobblestones, gratings, and utility access points can pose hazards or uncomfortable riding conditions for their journeys. Possible uses for the data set are identifying existing hazards in cycling infrastructure for municipal authorities, real time hazard and surface condition warnings for cyclists, and the identification of conditions that cause cyclists to make sudden changes in their immediate route.