 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Metric Color Embeddings for Splicing Localization in Severely Degraded Images
Jun 21, 2022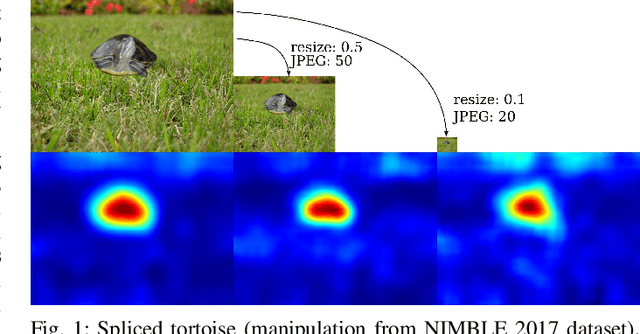
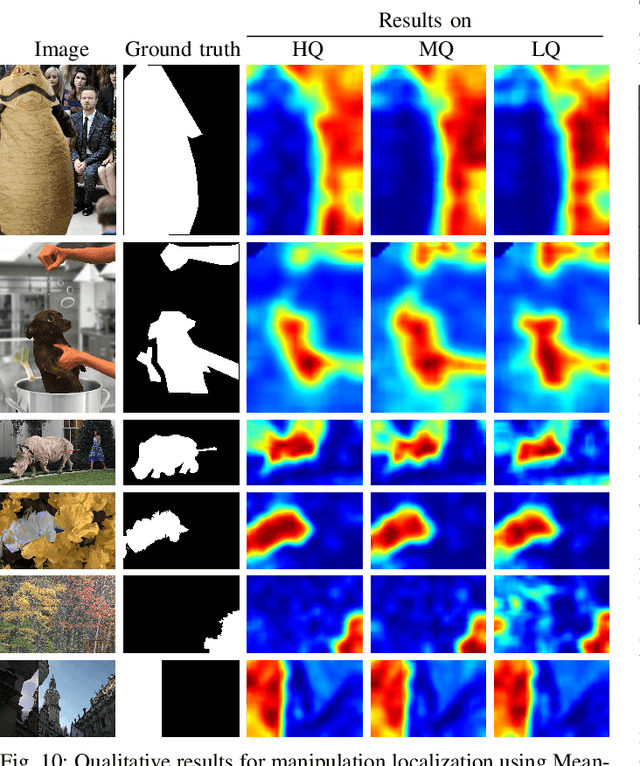
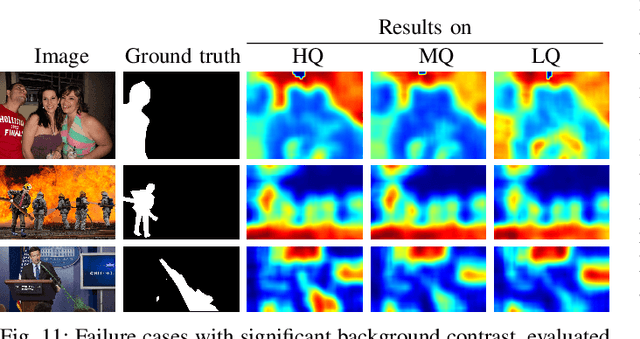
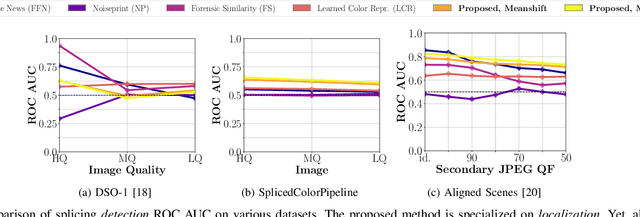
One common task in image forensics is to detect spliced images, where multiple source images are composed to one output image. Most of the currently best performing splicing detectors leverage high-frequency artifacts. However, after an image underwent strong compression, most of the high frequency artifacts are not available anymore. In this work, we explore an alternative approach to splicing detection, which is potentially better suited for images in-the-wild, subject to strong compression and downsampling. Our proposal is to model the color formation of an image. The color formation largely depends on variations at the scale of scene objects, and is hence much less dependent on high-frequency artifacts. We learn a deep metric space that is on one hand sensitive to illumination color and camera white-point estimation, but on the other hand insensitive to variations in object color. Large distances in the embedding space indicate that two image regions either stem from different scenes or different cameras. In our evaluation, we show that the proposed embedding space outperforms the state of the art on images that have been subject to strong compression and downsampling. We confirm in two further experiments the dual nature of the metric space, namely to both characterize the acquisition camera and the scene illuminant color. As such, this work resides at the intersection of physics-based and statistical forensics with benefits from both sides.
Bayesian Convolutional Neural Networks for Limited Data Hyperspectral Remote Sensing Image Classification
May 30, 2022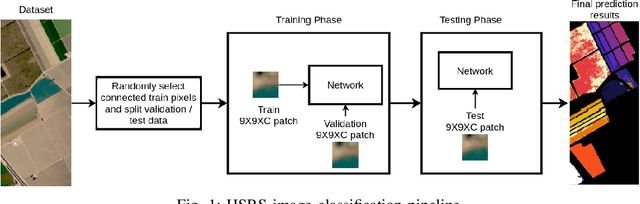

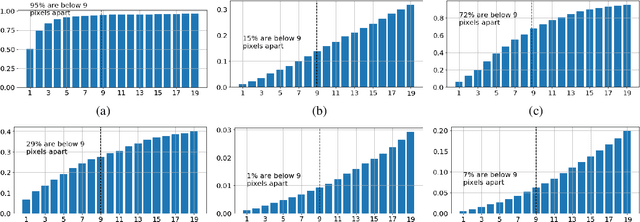
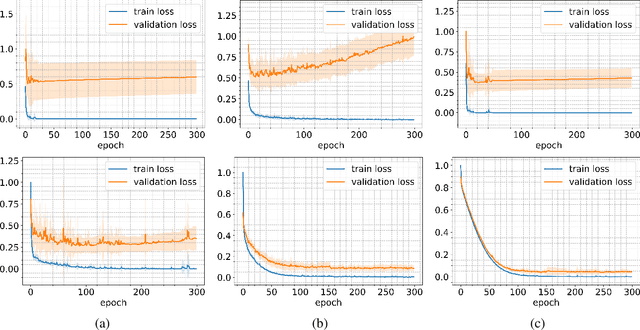
Employing deep neural networks for Hyperspectral remote sensing (HSRS) image classification is a challenging task. HSRS images have high dimensionality and a large number of channels with substantial redundancy between channels. In addition, the training data for classifying HSRS images is limited and the amount of available training data is much smaller compared to other classification tasks. These factors complicate the training process of deep neural networks with many parameters and cause them to not perform well even compared to conventional models. Moreover, convolutional neural networks produce over-confident predictions, which is highly undesirable considering the aforementioned problem. In this work, we use for HSRS image classification a special class of deep neural networks, namely a Bayesian neural network (BNN). To the extent of our knowledge, this is the first time that BNNs are used in HSRS image classification. BNNs inherently provide a measure for uncertainty. We perform extensive experiments on the Pavia Centre, Salinas, and Botswana datasets. We show that a BNN outperforms a standard convolutional neural network (CNN) and an off-the-shelf Random Forest (RF). Further experiments underline that the BNN is more stable and robust to model pruning, and that the uncertainty is higher for samples with higher expected prediction error.
Exploring the Open World Using Incremental Extreme Value Machines
May 30, 2022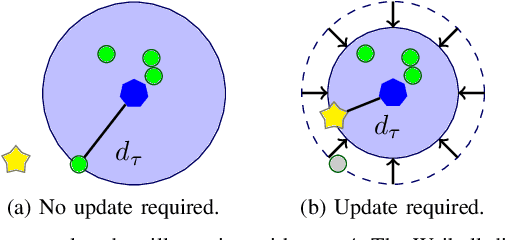

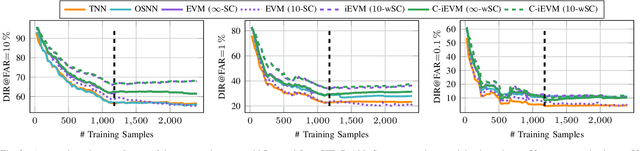
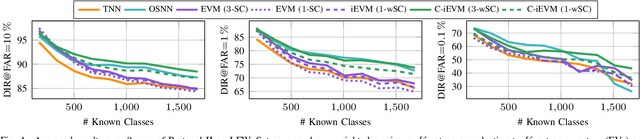
Dynamic environments require adaptive applications. One particular machine learning problem in dynamic environments is open world recognition. It characterizes a continuously changing domain where only some classes are seen in one batch of the training data and such batches can only be learned incrementally. Open world recognition is a demanding task that is, to the best of our knowledge, addressed by only a few methods. This work introduces a modification of the widely known Extreme Value Machine (EVM) to enable open world recognition. Our proposed method extends the EVM with a partial model fitting function by neglecting unaffected space during an update. This reduces the training time by a factor of 28. In addition, we provide a modified model reduction using weighted maximum K-set cover to strictly bound the model complexity and reduce the computational effort by a factor of 3.5 from 2.1 s to 0.6 s. In our experiments, we rigorously evaluate openness with two novel evaluation protocols. The proposed method achieves superior accuracy of about 12 % and computational efficiency in the tasks of image classification and face recognition.
Compliance Challenges in Forensic Image Analysis Under the Artificial Intelligence Act
Mar 01, 2022In many applications of forensic image analysis, state-of-the-art results are nowadays achieved with machine learning methods. However, concerns about their reliability and opaqueness raise the question whether such methods can be used in criminal investigations. So far, this question of legal compliance has hardly been discussed, also because legal regulations for machine learning methods were not defined explicitly. To this end, the European Commission recently proposed the artificial intelligence (AI) act, a regulatory framework for the trustworthy use of AI. Under the draft AI act, high-risk AI systems for use in law enforcement are permitted but subject to compliance with mandatory requirements. In this paper, we review why the use of machine learning in forensic image analysis is classified as high-risk. We then summarize the mandatory requirements for high-risk AI systems and discuss these requirements in light of two forensic applications, license plate recognition and deep fake detection. The goal of this paper is to raise awareness of the upcoming legal requirements and to point out avenues for future research.
Deep learning architectural designs for super-resolution of noisy images
Feb 09, 2021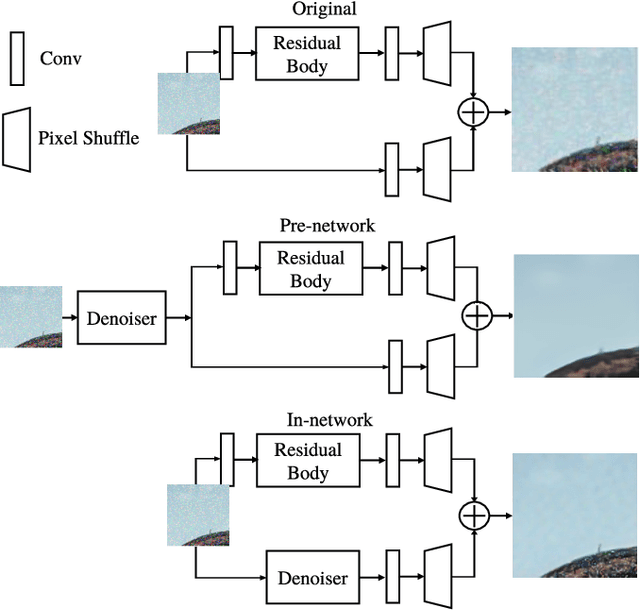
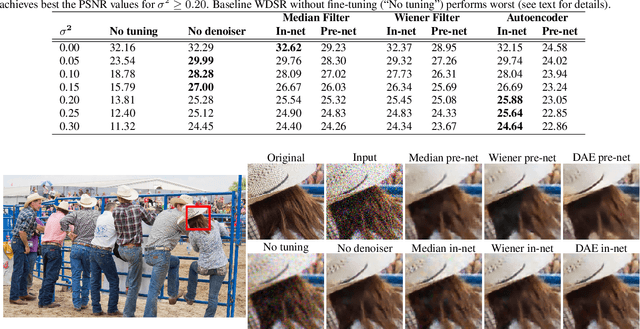
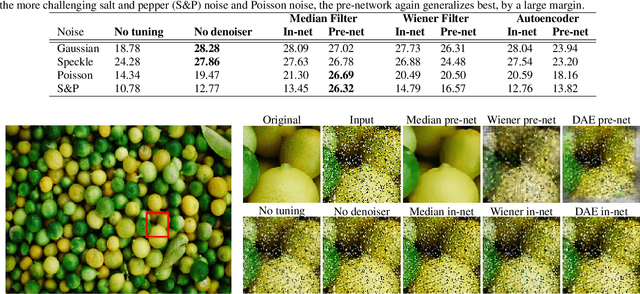

Recent advances in deep learning have led to significant improvements in single image super-resolution (SR) research. However, due to the amplification of noise during the upsampling steps, state-of-the-art methods often fail at reconstructing high-resolution images from noisy versions of their low-resolution counterparts. However, this is especially important for images from unknown cameras with unseen types of image degradation. In this work, we propose to jointly perform denoising and super-resolution. To this end, we investigate two architectural designs: "in-network" combines both tasks at feature level, while "pre-network" first performs denoising and then super-resolution. Our experiments show that both variants have specific advantages: The in-network design obtains the strongest results when the type of image corruption is aligned in the training and testing dataset, for any choice of denoiser. The pre-network design exhibits superior performance on unseen types of image corruption, which is a pathological failure case of existing super-resolution models. We hope that these findings help to enable super-resolution also in less constrained scenarios where source camera or imaging conditions are not well controlled. Source code and pretrained models are available at https://github.com/ angelvillar96/super-resolution-noisy-images.
Synthetic Glacier SAR Image Generation from Arbitrary Masks Using Pix2Pix Algorithm
Jan 14, 2021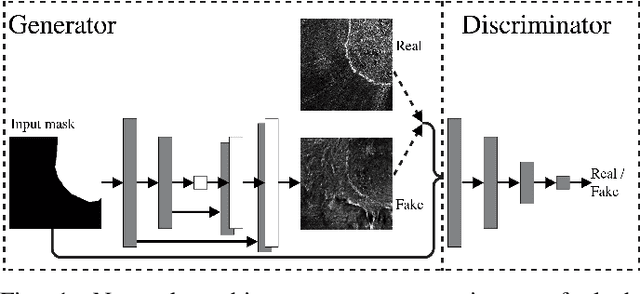
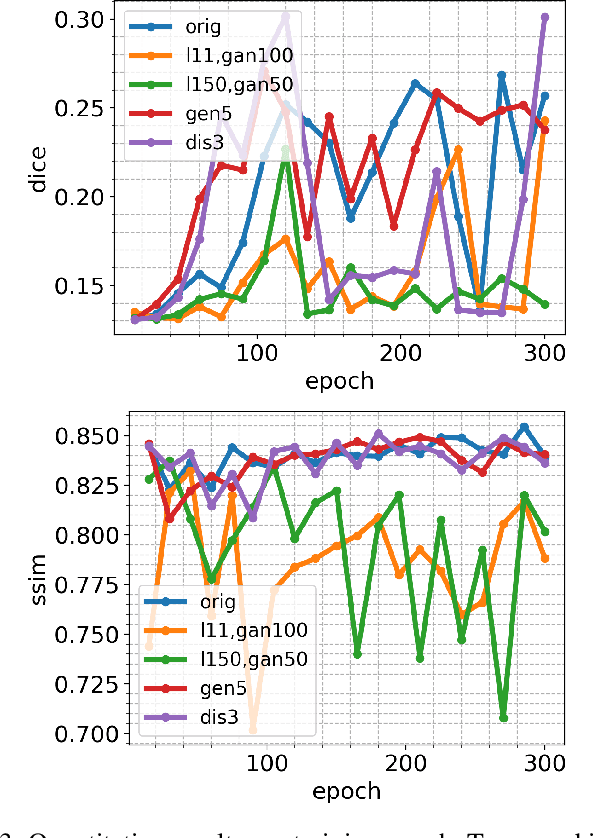

Supervised machine learning requires a large amount of labeled data to achieve proper test results. However, generating accurately labeled segmentation maps on remote sensing imagery, including images from synthetic aperture radar (SAR), is tedious and highly subjective. In this work, we propose to alleviate the issue of limited training data by generating synthetic SAR images with the pix2pix algorithm. This algorithm uses conditional Generative Adversarial Networks (cGANs) to generate an artificial image while preserving the structure of the input. In our case, the input is a segmentation mask, from which a corresponding synthetic SAR image is generated. We present different models, perform a comparative study and demonstrate that this approach synthesizes convincing glaciers in SAR images with promising qualitative and quantitative results.
The Forchheim Image Database for Camera Identification in the Wild
Nov 04, 2020
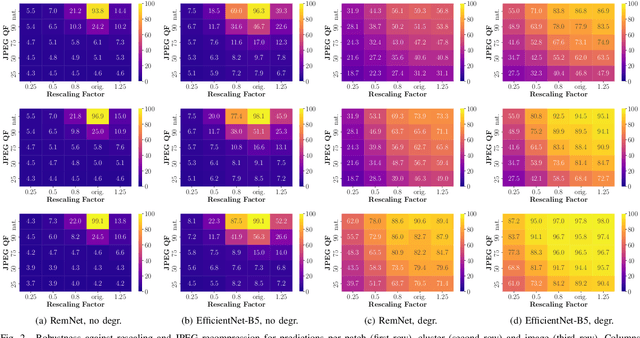
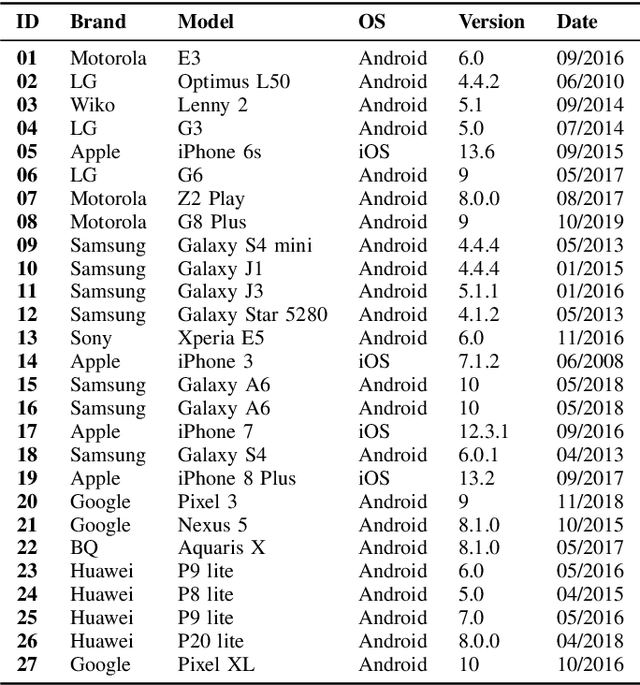
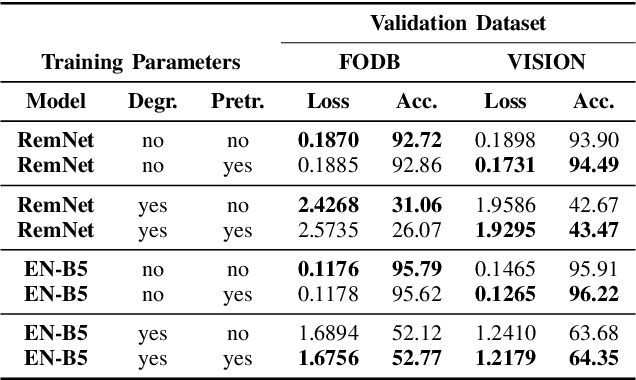
Image provenance can represent crucial knowledge in criminal investigation and journalistic fact checking. In the last two decades, numerous algorithms have been proposed for obtaining information on the source camera and distribution history of an image. For a fair ranking of these techniques, it is important to rigorously assess their performance on practically relevant test cases. To this end, a number of datasets have been proposed. However, we argue that there is a gap in existing databases: to our knowledge, there is currently no dataset that simultaneously satisfies two goals, namely a) to cleanly separate scene content and forensic traces, and b) to support realistic post-processing like social media recompression. In this work, we propose the Forchheim Image Database (FODB) to close this gap. It consists of more than 23,000 images of 143 scenes by 27 smartphone cameras, and it allows to cleanly separate image content from forensic artifacts. Each image is provided in 6 different qualities: the original camera-native version, and five copies from social networks. We demonstrate the usefulness of FODB in an evaluation of methods for camera identification. We report three findings. First, the recently proposed general-purpose EfficientNet remarkably outperforms several dedicated forensic CNNs both on clean and compressed images. Second, classifiers obtain a performance boost even on unknown post-processing after augmentation by artificial degradations. Third, FODB's clean separation of scene content and forensic traces imposes important, rigorous boundary conditions for algorithm benchmarking.
Reconstruction of Voxels with Position- and Angle-Dependent Weightings
Oct 27, 2020

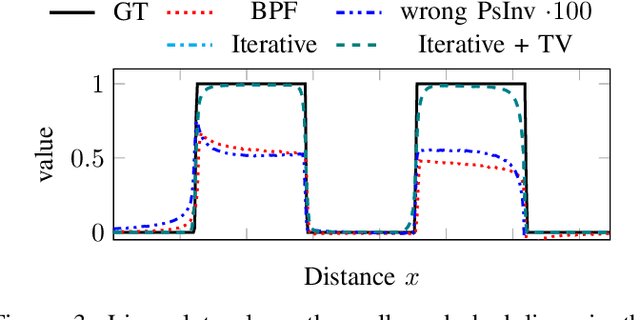
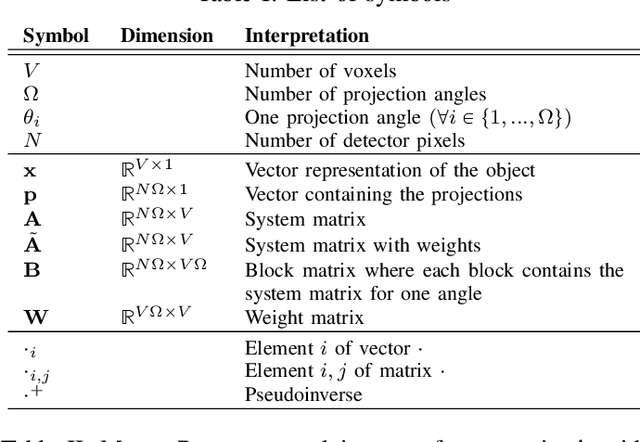
The reconstruction problem of voxels with individual weightings can be modeled a position- and angle- dependent function in the forward-projection. This changes the system matrix and prohibits to use standard filtered backprojection. In this work we first formulate this reconstruction problem in terms of a system matrix and weighting part. We compute the pseudoinverse and show that the solution is rank-deficient and hence very ill posed. This is a fundamental limitation for reconstruction. We then derive an iterative solution and experimentally show its uperiority to any closed-form solution.
Toward Reliable Models for Authenticating Multimedia Content: Detecting Resampling Artifacts With Bayesian Neural Networks
Jul 28, 2020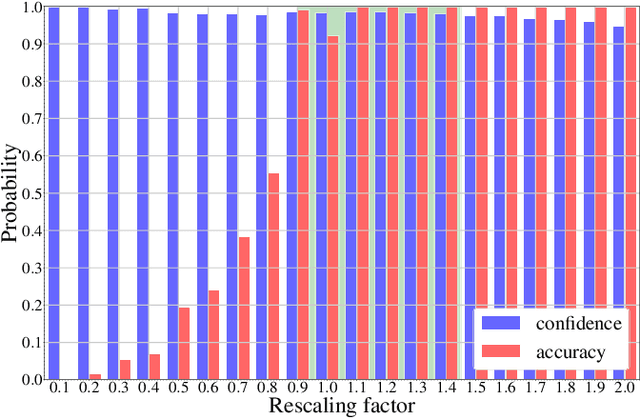
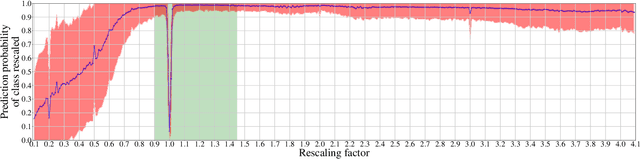
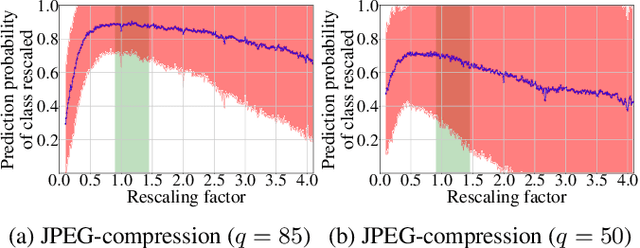
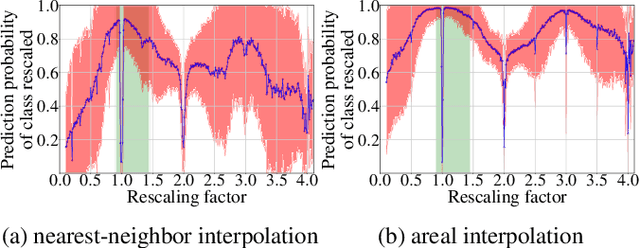
In multimedia forensics, learning-based methods provide state-of-the-art performance in determining origin and authenticity of images and videos. However, most existing methods are challenged by out-of-distribution data, i.e., with characteristics that are not covered in the training set. This makes it difficult to know when to trust a model, particularly for practitioners with limited technical background. In this work, we make a first step toward redesigning forensic algorithms with a strong focus on reliability. To this end, we propose to use Bayesian neural networks (BNN), which combine the power of deep neural networks with the rigorous probabilistic formulation of a Bayesian framework. Instead of providing a point estimate like standard neural networks, BNNs provide distributions that express both the estimate and also an uncertainty range. We demonstrate the usefulness of this framework on a classical forensic task: resampling detection. The BNN yields state-of-the-art detection performance, plus excellent capabilities for detecting out-of-distribution samples. This is demonstrated for three pathologic issues in resampling detection, namely unseen resampling factors, unseen JPEG compression, and unseen resampling algorithms. We hope that this proposal spurs further research toward reliability in multimedia forensics.
Merging-ISP: Multi-Exposure High Dynamic Range Image Signal Processing
Nov 12, 2019
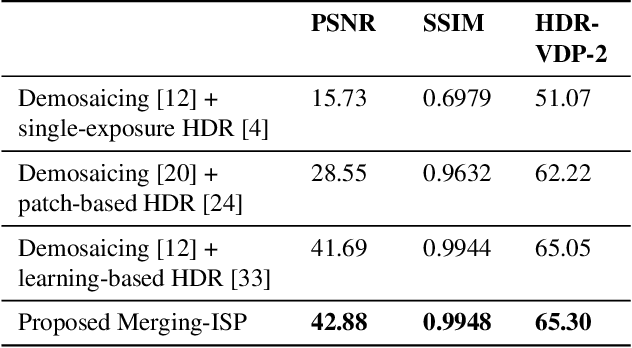
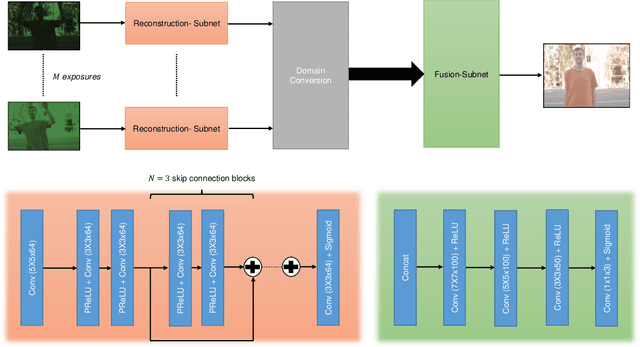
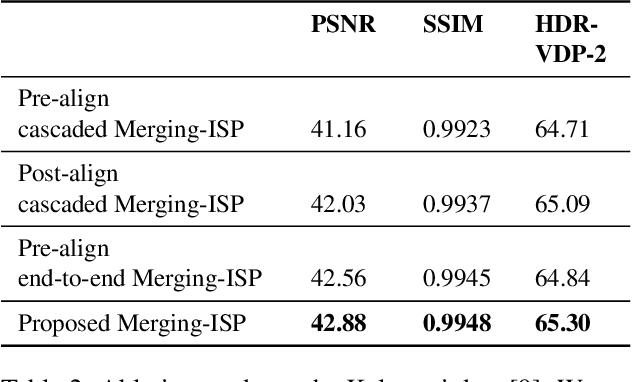
The image signal processing pipeline (ISP) is a core element of digital cameras to capture high-quality displayable images from raw data. In high dynamic range (HDR) imaging, ISPs include steps like demosaicing of raw color filter array (CFA) data at different exposure times, alignment of the exposures, conversion to HDR domain, and exposure merging into an HDR image. Traditionally, such pipelines are built by cascading algorithms addressing the individual subtasks. However, cascaded designs suffer from error propagations since simply combining multiple processing steps is not necessarily optimal for the entire imaging task. This paper proposes a multi-exposure high dynamic range image signal processing pipeline (Merging-ISP) to jointly solve all subtasks for HDR imaging. Our pipeline is modeled by a deep neural network architecture. As such, it is end-to-end trainable, circumvents the use of complex, hand-crafted algorithms in its core, and mitigates error propagation. Merging-ISP enables direct reconstructions of HDR images from multiple differently exposed raw CFA images captured from dynamic scenes. We compared Merging-ISP against different alternative cascaded pipelines. End-to-end learning leads to HDR reconstructions of high perceptual quality and quantitatively outperforms competing ISPs by more than 1 dB in terms of PSNR.