 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWisdom Of The (AI) Crowd: Investigating Artificial Swarm Intelligence In Large Language Models
Jun 30, 2026Human swarm intelligence demonstrates remarkable collective accuracy but faces scalability constraints in cost, coordination, and time. We investigate whether large language models (LLMs) can approximate swarm intelligence effects through artificial swarms, addressing a critical gap in understanding AI-based aggregation mechanisms. We conducted a controlled experiment with 960 manually executed prompts across three proprietary models (GPT-5, Gemini 2.5 Pro, Claude Sonnet 4.5), testing intra-model sampling and inter-model aggregation on eight estimation tasks. Results reveal consistent error reduction through intra- and inter-model aggregation, with significant error reductions up to 37 percentage points in MAPE across different aggregation strategies. We observed small to large effect sizes for positive correlations (Spearman's $ρ=0.242-0.568$, all $p<0.001$) between relative confidence interval widths and relative estimation errors, suggesting LLMs possess metacognitive awareness when assessing uncertainty. We discuss implications for research and practice, providing actionable insights for deploying LLM swarms in organizational decision-making.
From Explainable to Explanatory Artificial Intelligence: Toward a New Paradigm for Human-Centered Explanations through Generative AI
Aug 08, 2025Current explainable AI (XAI) approaches prioritize algorithmic transparency and present explanations in abstract, non-adaptive formats that often fail to support meaningful end-user understanding. This paper introduces "Explanatory AI" as a complementary paradigm that leverages generative AI capabilities to serve as explanatory partners for human understanding rather than providers of algorithmic transparency. While XAI reveals algorithmic decision processes for model validation, Explanatory AI addresses contextual reasoning to support human decision-making in sociotechnical contexts. We develop a definition and systematic eight-dimensional conceptual model distinguishing Explanatory AI through narrative communication, adaptive personalization, and progressive disclosure principles. Empirical validation through Rapid Contextual Design methodology with healthcare professionals demonstrates that users consistently prefer context-sensitive, multimodal explanations over technical transparency. Our findings reveal the practical urgency for AI systems designed for human comprehension rather than algorithmic introspection, establishing a comprehensive research agenda for advancing user-centered AI explanation approaches across diverse domains and cultural contexts.
Vibe Coding as a Reconfiguration of Intent Mediation in Software Development: Definition, Implications, and Research Agenda
Jul 29, 2025
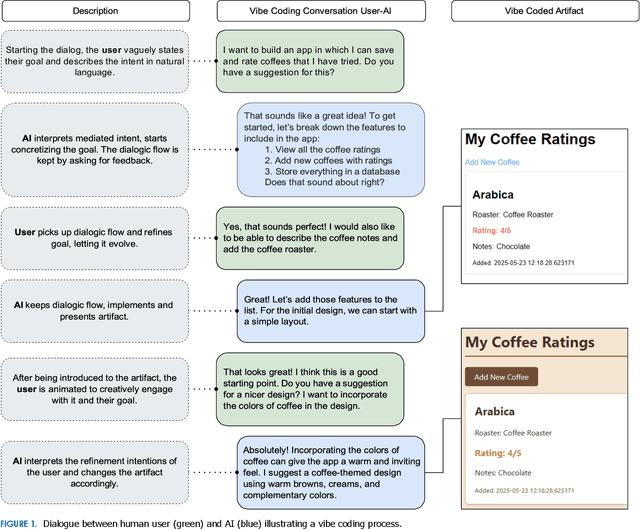
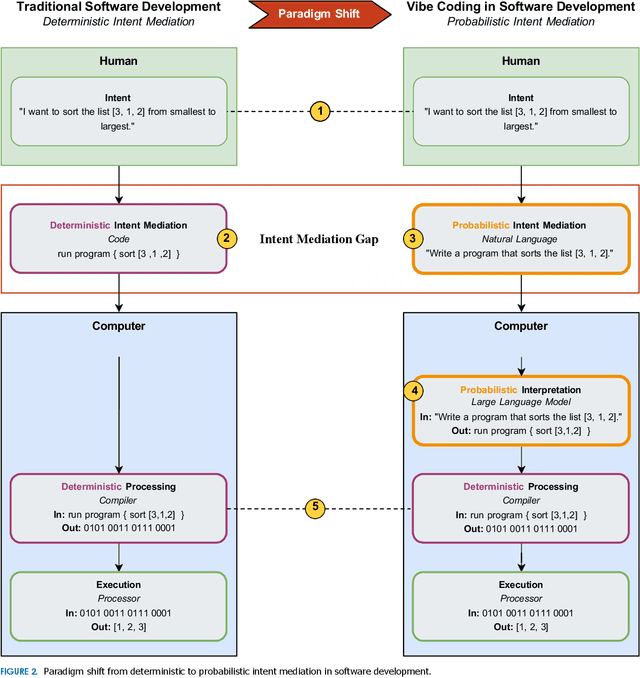
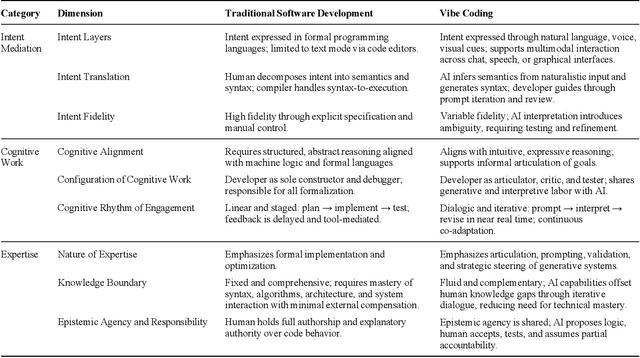
Software development is undergoing a fundamental transformation as vibe coding becomes widespread, with large portions of contemporary codebases now being AI-generated. The disconnect between rapid adoption and limited conceptual understanding highlights the need for an inquiry into this emerging paradigm. Drawing on an intent perspective and historical analysis, we define vibe coding as a software development paradigm where humans and generative AI engage in collaborative flow to co-create software artifacts through natural language dialogue, shifting the mediation of developer intent from deterministic instruction to probabilistic inference. By intent mediation, we refer to the fundamental process through which developers translate their conceptual goals into representations that computational systems can execute. Our results show that vibe coding reconfigures cognitive work by redistributing epistemic labor between humans and machines, shifting the expertise in the software development process away from traditional areas such as design or technical implementation toward collaborative orchestration. We identify key opportunities, including democratization, acceleration, and systemic leverage, alongside risks, such as black box codebases, responsibility gaps, and ecosystem bias. We conclude with a research agenda spanning human-, technology-, and organization-centered directions to guide future investigations of this paradigm.
Investigating the Role of Explainability and AI Literacy in User Compliance
Jun 18, 2024AI is becoming increasingly common across different domains. However, as sophisticated AI-based systems are often black-boxed, rendering the decision-making logic opaque, users find it challenging to comply with their recommendations. Although researchers are investigating Explainable AI (XAI) to increase the transparency of the underlying machine learning models, it is unclear what types of explanations are effective and what other factors increase compliance. To better understand the interplay of these factors, we conducted an experiment with 562 participants who were presented with the recommendations of an AI and two different types of XAI. We find that users' compliance increases with the introduction of XAI but is also affected by AI literacy. We also find that the relationships between AI literacy XAI and users' compliance are mediated by the users' mental model of AI. Our study has several implications for successfully designing AI-based systems utilizing XAI.
Fake or Credible? Towards Designing Services to Support Users' Credibility Assessment of News Content
Sep 21, 2021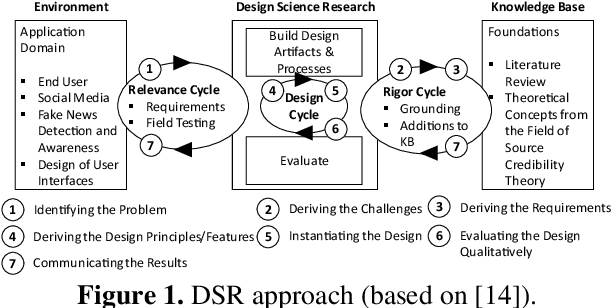
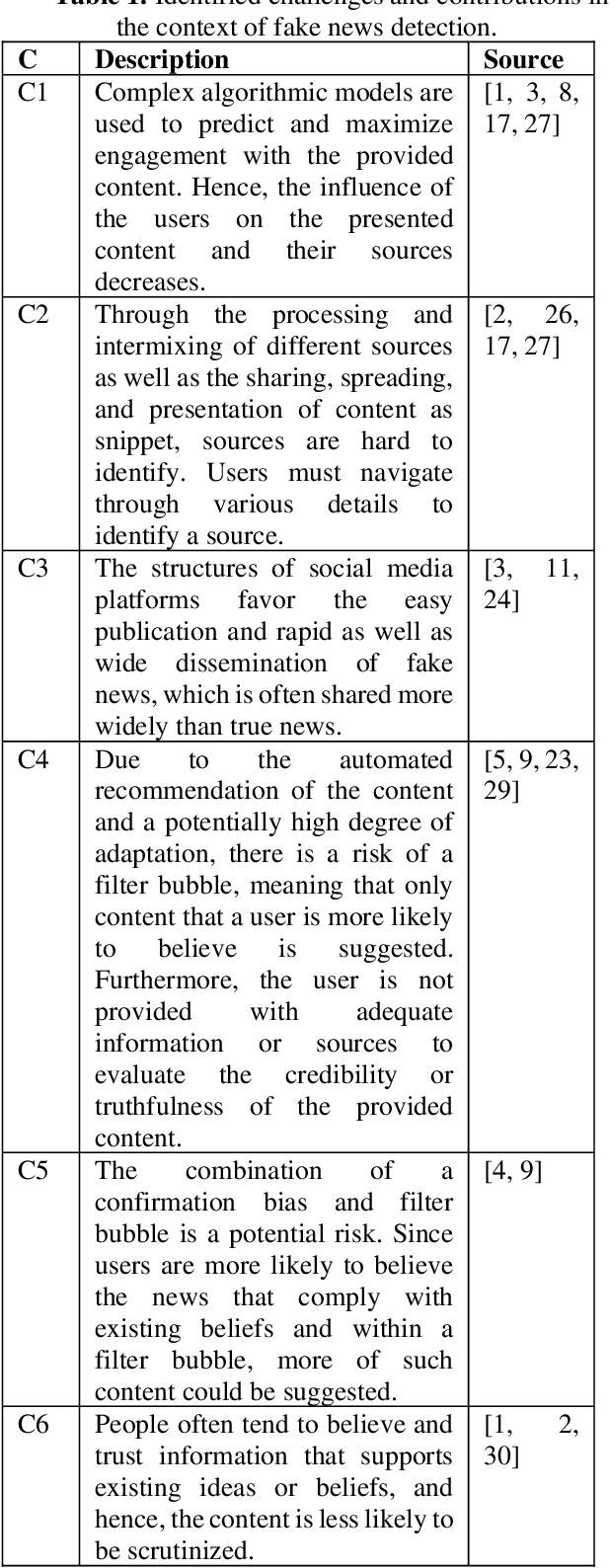
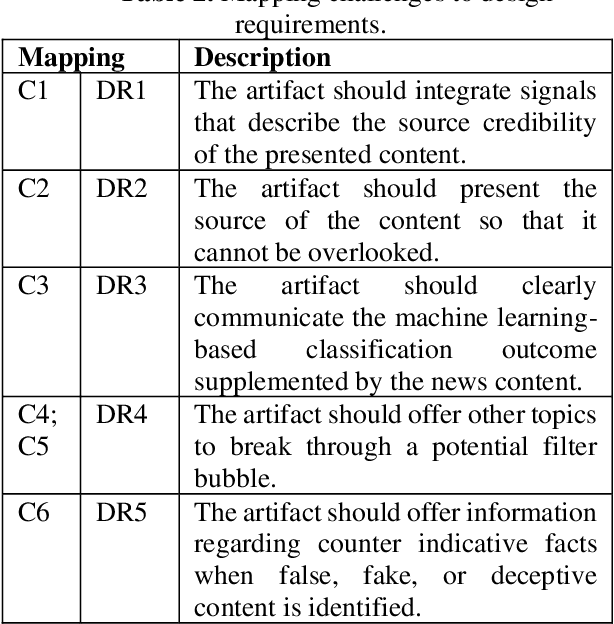
Fake news has become omnipresent in digitalized areas such as social media platforms. While being disseminated online, it also poses a threat to individuals and societies offline, for example, in the context of democratic elections. Research and practice have investigated the detection of fake news with behavioral science or method-related perspectives. However, to date, we lack design knowledge on presenting fake news warnings to users to support their individual news credibility assessment. We present the journey through the first design cycle on developing a fake news detection service focusing on the user interface design. The design is grounded in concepts from the field of source credibility theory and instantiated in a prototype that was qualitatively evaluated. The 13 participants communicated their interest in a lightweight application that aids in the news credibility assessment and rated the design features as useful as well as desirable.
AI Governance for Businesses
Nov 20, 2020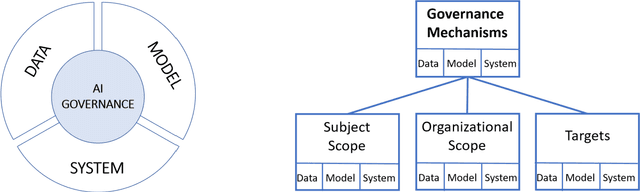
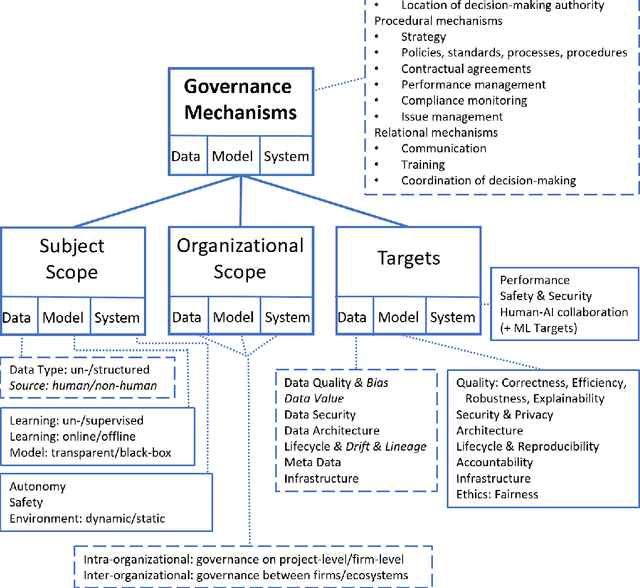
Artificial Intelligence (AI) governance regulates the exercise of authority and control over the management of AI. It aims at leveraging AI through effective use of data and minimization of AI-related cost and risk. While topics such as AI governance and AI ethics are thoroughly discussed on a theoretical, philosophical, societal and regulatory level, there is limited work on AI governance targeted to companies and corporations. This work views AI products as systems, where key functionality is delivered by machine learning (ML) models leveraging (training) data. We derive a conceptual framework by synthesizing literature on AI and related fields such as ML. Our framework decomposes AI governance into governance of data, (ML) models and (AI) systems along four dimensions. It relates to existing IT and data governance frameworks and practices. It can be adopted by practitioners and academics alike. For practitioners the synthesis of mainly research papers, but also practitioner publications and publications of regulatory bodies provides a valuable starting point to implement AI governance, while for academics the paper highlights a number of areas of AI governance that deserve more attention.
Do you comply with AI? -- Personalized explanations of learning algorithms and their impact on employees' compliance behavior
Feb 20, 2020
Machine Learning algorithms are technological key enablers for artificial intelligence (AI). Due to the inherent complexity, these learning algorithms represent black boxes and are difficult to comprehend, therefore influencing compliance behavior. Hence, compliance with the recommendations of such artifacts, which can impact employees' task performance significantly, is still subject to research - and personalization of AI explanations seems to be a promising concept in this regard. In our work, we hypothesize that, based on varying backgrounds like training, domain knowledge and demographic characteristics, individuals have different understandings and hence mental models about the learning algorithm. Personalization of AI explanations, related to the individuals' mental models, may thus be an instrument to affect compliance and therefore employee task performance. Our preliminary results already indicate the importance of personalized explanations in industry settings and emphasize the importance of this research endeavor.
Deceptive AI Explanations: Creation and Detection
Jan 21, 2020
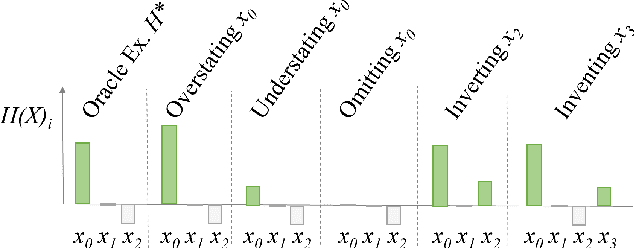


Artificial intelligence comes with great opportunities and but also great risks. We investigate to what extent deep learning can be used to create and detect deceptive explanations that either aim to lure a human into believing a decision that is not truthful to the model or provide reasoning that is non-faithful to the decision. Our theoretical insights show some limits of deception and detection in the absence of domain knowledge. For empirical evaluation, we focus on text classification. To create deceptive explanations, we alter explanations originating from GradCAM, a state-of-art technique for creating explanations in neural networks. We evaluate the effectiveness of deceptive explanations on 200 participants. Our findings indicate that deceptive explanations can indeed fool humans. Our classifier can detect even seemingly minor attempts of deception with accuracy that exceeds 80\% given sufficient domain knowledge encoded in the form of training data.