 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTAfrica: Multilingual Machine Translation for African Languages
Apr 08, 2022
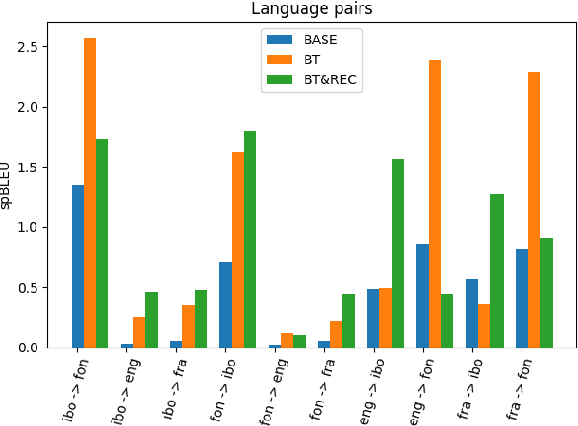
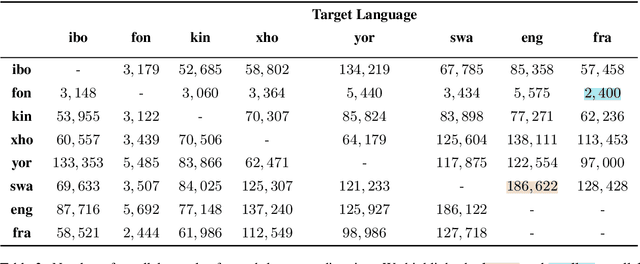
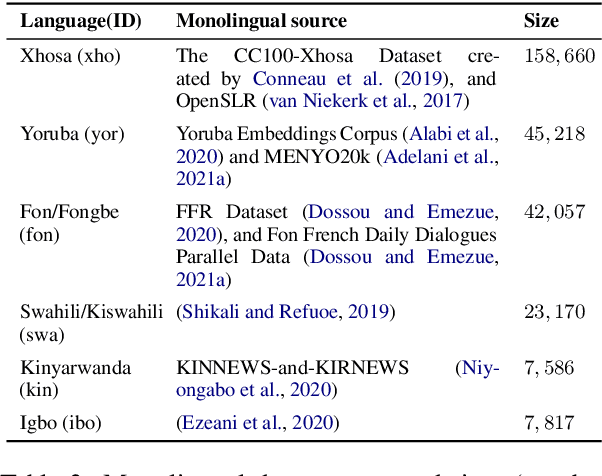
In this paper, we focus on the task of multilingual machine translation for African languages and describe our contribution in the 2021 WMT Shared Task: Large-Scale Multilingual Machine Translation. We introduce MMTAfrica, the first many-to-many multilingual translation system for six African languages: Fon (fon), Igbo (ibo), Kinyarwanda (kin), Swahili/Kiswahili (swa), Xhosa (xho), and Yoruba (yor) and two non-African languages: English (eng) and French (fra). For multilingual translation concerning African languages, we introduce a novel backtranslation and reconstruction objective, BT\&REC, inspired by the random online back translation and T5 modeling framework respectively, to effectively leverage monolingual data. Additionally, we report improvements from MMTAfrica over the FLORES 101 benchmarks (spBLEU gains ranging from $+0.58$ in Swahili to French to $+19.46$ in French to Xhosa). We release our dataset and code source at https://github.com/edaiofficial/mmtafrica.
* WMT Shared Task, EMNLP 2021 (version 2)
Crowdsourced Phrase-Based Tokenization for Low-Resourced Neural Machine Translation: The Case of Fon Language
Mar 17, 2021
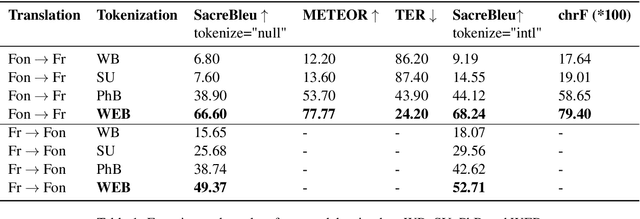
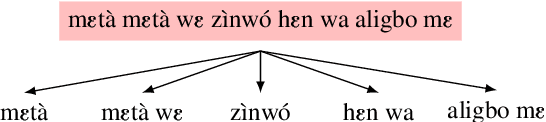

Building effective neural machine translation (NMT) models for very low-resourced and morphologically rich African indigenous languages is an open challenge. Besides the issue of finding available resources for them, a lot of work is put into preprocessing and tokenization. Recent studies have shown that standard tokenization methods do not always adequately deal with the grammatical, diacritical, and tonal properties of some African languages. That, coupled with the extremely low availability of training samples, hinders the production of reliable NMT models. In this paper, using Fon language as a case study, we revisit standard tokenization methods and introduce Word-Expressions-Based (WEB) tokenization, a human-involved super-words tokenization strategy to create a better representative vocabulary for training. Furthermore, we compare our tokenization strategy to others on the Fon-French and French-Fon translation tasks.
OkwuGbé: End-to-End Speech Recognition for Fon and Igbo
Mar 16, 2021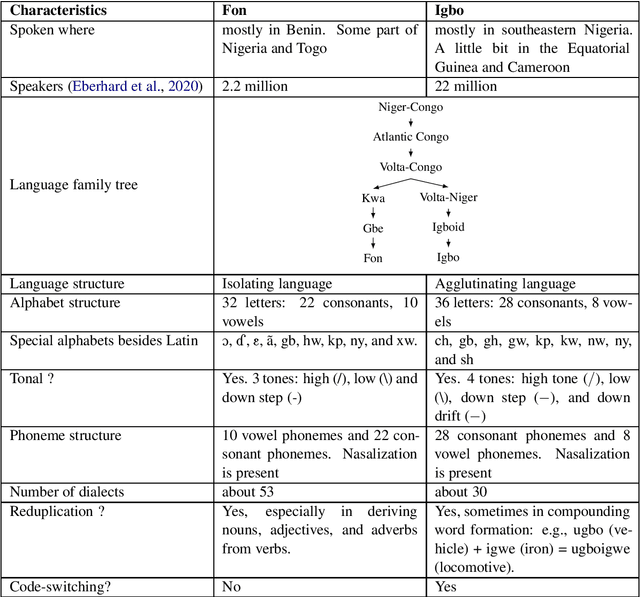
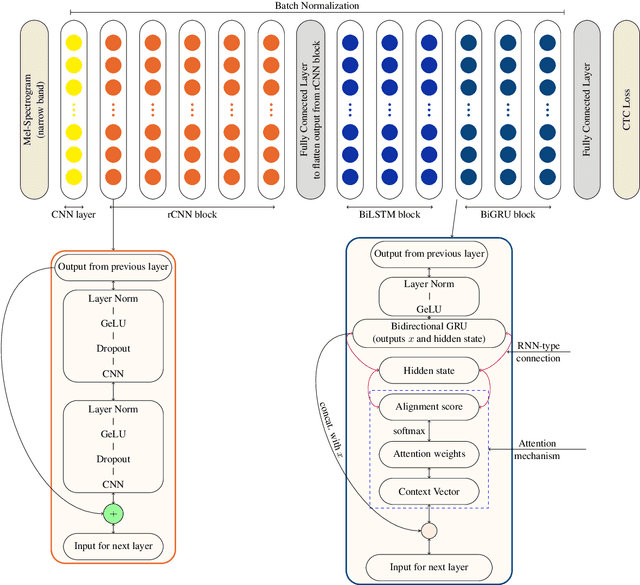
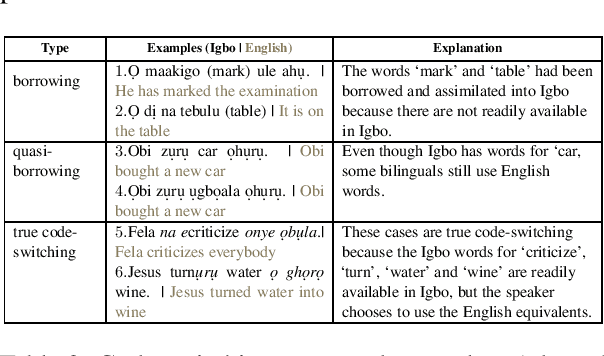
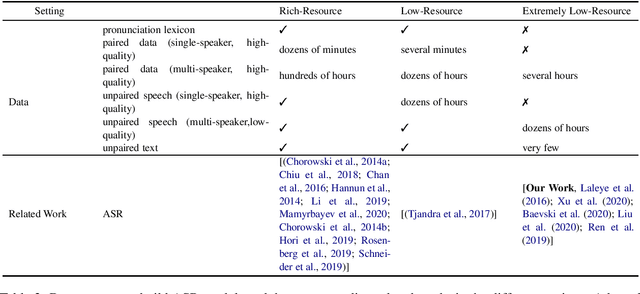
Language is inherent and compulsory for human communication. Whether expressed in a written or spoken way, it ensures understanding between people of the same and different regions. With the growing awareness and effort to include more low-resourced languages in NLP research, African languages have recently been a major subject of research in machine translation, and other text-based areas of NLP. However, there is still very little comparable research in speech recognition for African languages. Interestingly, some of the unique properties of African languages affecting NLP, like their diacritical and tonal complexities, have a major root in their speech, suggesting that careful speech interpretation could provide more intuition on how to deal with the linguistic complexities of African languages for text-based NLP. OkwuGb\'e is a step towards building speech recognition systems for African low-resourced languages. Using Fon and Igbo as our case study, we conduct a comprehensive linguistic analysis of each language and describe the creation of end-to-end, deep neural network-based speech recognition models for both languages. We present a state-of-art ASR model for Fon, as well as benchmark ASR model results for Igbo. Our linguistic analyses (for Fon and Igbo) provide valuable insights and guidance into the creation of speech recognition models for other African low-resourced languages, as well as guide future NLP research for Fon and Igbo. The Fon and Igbo models source code have been made publicly available.
Lanfrica: A Participatory Approach to Documenting Machine Translation Research on African Languages
Aug 03, 2020
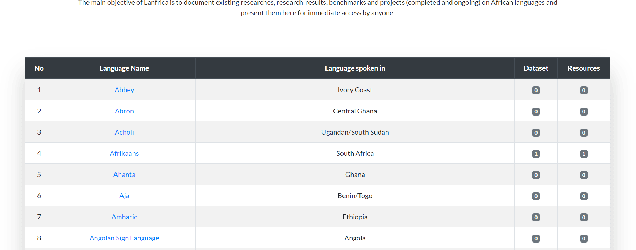
Over the years, there have been campaigns to include the African languages in the growing research on machine translation (MT) in particular, and natural language processing (NLP) in general. Africa has the highest language diversity, with 1500-2000 documented languages and many more undocumented or extinct languages(Lewis, 2009; Bendor-Samuel, 2017). This makes it hard to keep track of the MT research, models and dataset that have been developed for some of them. As the internet and social media make up the daily lives of more than half of the world(Lin, 2020), as well as over 40% of Africans(Campbell, 2019), online platforms can be useful in creating accessibility to researches, benchmarks and datasets in these African languages, thereby improving reproducibility and sharing of existing research and their results. In this paper, we introduce Lanfrica, a novel, on-going framework that employs a participatory approach to documenting researches, projects, benchmarks and dataset on African languages.
FFR v1.1: Fon-French Neural Machine Translation
Jun 14, 2020
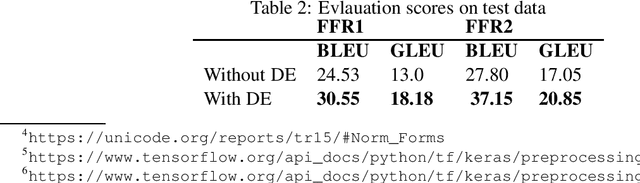

All over the world and especially in Africa, researchers are putting efforts into building Neural Machine Translation (NMT) systems to help tackle the language barriers in Africa, a continent of over 2000 different languages. However, the low-resourceness, diacritical, and tonal complexities of African languages are major issues being faced. The FFR project is a major step towards creating a robust translation model from Fon, a very low-resource and tonal language, to French, for research and public use. In this paper, we introduce FFR Dataset, a corpus of Fon-to-French translations, describe the diacritical encoding process, and introduce our FFR v1.1 model, trained on the dataset. The dataset and model are made publicly available at https://github.com/ bonaventuredossou/ffr-v1, to promote collaboration and reproducibility.
FFR V1.0: Fon-French Neural Machine Translation
Mar 26, 2020
Africa has the highest linguistic diversity in the world. On account of the importance of language to communication, and the importance of reliable, powerful and accurate machine translation models in modern inter-cultural communication, there have been (and still are) efforts to create state-of-the-art translation models for the many African languages. However, the low-resources, diacritical and tonal complexities of African languages are major issues facing African NLP today. The FFR is a major step towards creating a robust translation model from Fon, a very low-resource and tonal language, to French, for research and public use. In this paper, we describe our pilot project: the creation of a large growing corpora for Fon-to-French translations and our FFR v1.0 model, trained on this dataset. The dataset and model are made publicly available.