 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cross-Joint Attention for Generalizable Video-Based Seizure Detection
Mar 24, 2026Automated seizure detection from long-term clinical videos can substantially reduce manual review time and enable real-time monitoring. However, existing video-based methods often struggle to generalize to unseen subjects due to background bias and reliance on subject-specific appearance cues. We propose a joint-centric attention model that focuses exclusively on body dynamics to improve cross-subject generalization. For each video segment, body joints are detected and joint-centered clips are extracted, suppressing background context. These joint-centered clips are tokenized using a Video Vision Transformer (ViViT), and cross-joint attention is learned to model spatial and temporal interactions between body parts, capturing coordinated movement patterns characteristic of seizure semiology. Extensive cross-subject experiments show that the proposed method consistently outperforms state-of-the-art CNN-, graph-, and transformer-based approaches on unseen subjects.
Learning Formation of Physically-Based Face Attributes
Apr 24, 2020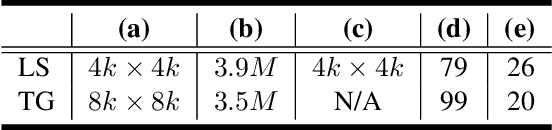

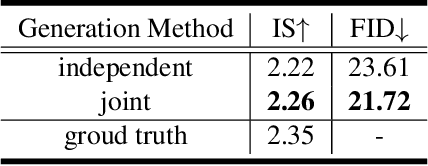
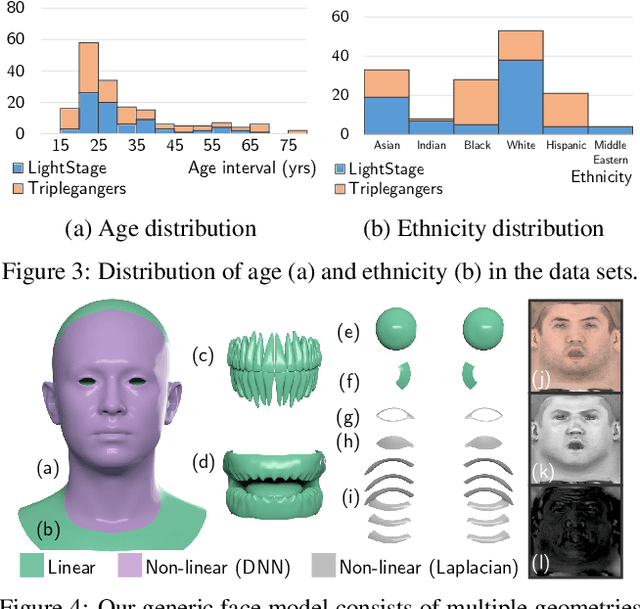
Based on a combined data set of 4000 high resolution facial scans, we introduce a non-linear morphable face model, capable of producing multifarious face geometry of pore-level resolution, coupled with material attributes for use in physically-based rendering. We aim to maximize the variety of face identities, while increasing the robustness of correspondence between unique components, including middle-frequency geometry, albedo maps, specular intensity maps and high-frequency displacement details. Our deep learning based generative model learns to correlate albedo and geometry, which ensures the anatomical correctness of the generated assets. We demonstrate potential use of our generative model for novel identity generation, model fitting, interpolation, animation, high fidelity data visualization, and low-to-high resolution data domain transferring. We hope the release of this generative model will encourage further cooperation between all graphics, vision, and data focused professionals while demonstrating the cumulative value of every individual's complete biometric profile.
A Novel Approach to Skew-Detection and Correction of English Alphabets for OCR
Jan 02, 2018
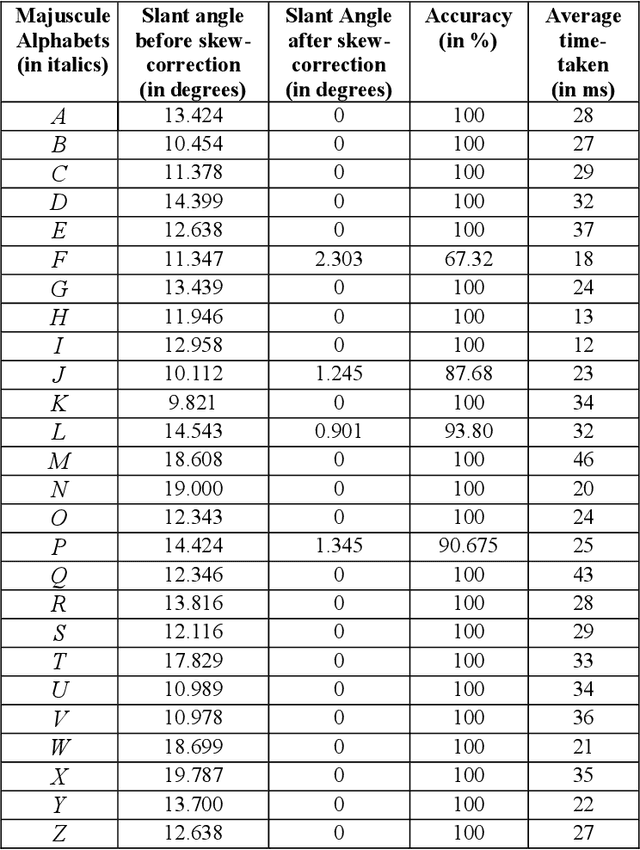

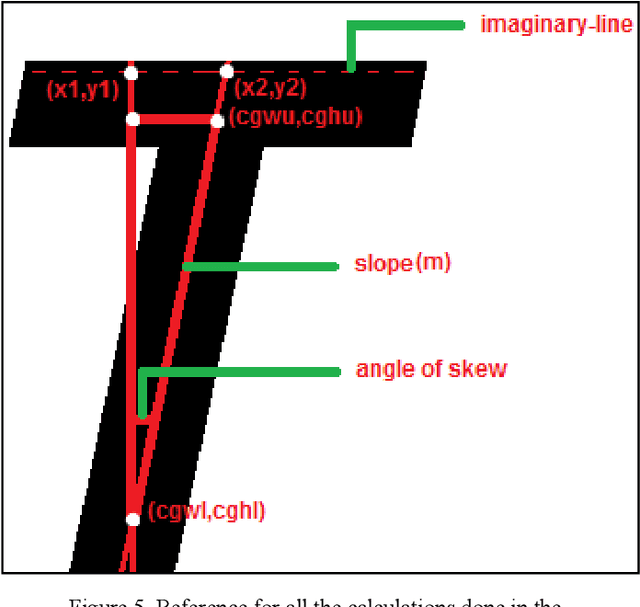
Optical Character Recognition has been a challenging field in the advent of digital computers. It is needed where information is to be readable both to humans and machines. The process of OCR is composed of a set of pre and post processing steps that decide the level of accuracy of recognition. This paper deals with one of the pre-processing steps involved in the OCR process i.e. Skew (Slant) Detection and Correction. The proposed algorithm implemented for skew-detection is termed as the COG (Centre of Gravity) method and for that of skew-correction is Sub-Pixel Shifting method. The algorithm has been kept simple and optimized for efficient skew-detection and correction. The performance analysis of the algorithm after testing has been aptly demonstrated.
* 4 pages, 11 figures, 8 references, 2012 IEEE Student Conference on Research and Development