 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLOR: A Flexible Framework of Deep Reinforcement Learning for Operation Research
Mar 23, 2023Reinforcement learning has been applied in operation research and has shown promise in solving large combinatorial optimization problems. However, existing works focus on developing neural network architectures for certain problems. These works lack the flexibility to incorporate recent advances in reinforcement learning, as well as the flexibility of customizing model architectures for operation research problems. In this work, we analyze the end-to-end autoregressive models for vehicle routing problems and show that these models can benefit from the recent advances in reinforcement learning with a careful re-implementation of the model architecture. In particular, we re-implemented the Attention Model and trained it with Proximal Policy Optimization (PPO) in CleanRL, showing at least 8 times speed up in training time. We hereby introduce RLOR, a flexible framework for Deep Reinforcement Learning for Operation Research. We believe that a flexible framework is key to developing deep reinforcement learning models for operation research problems. The code of our work is publicly available at https://github.com/cpwan/RLOR.
Robust Federated Learning with Attack-Adaptive Aggregation
Feb 10, 2021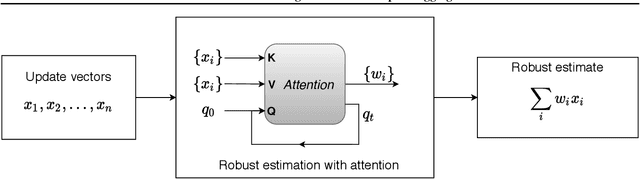
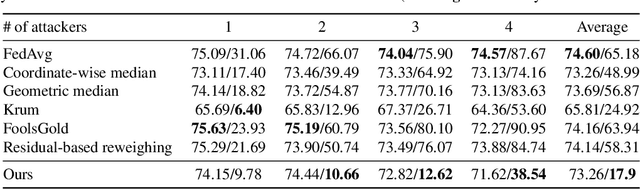
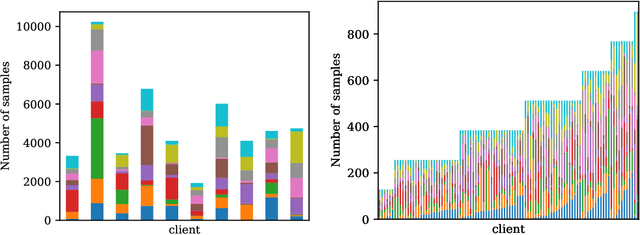
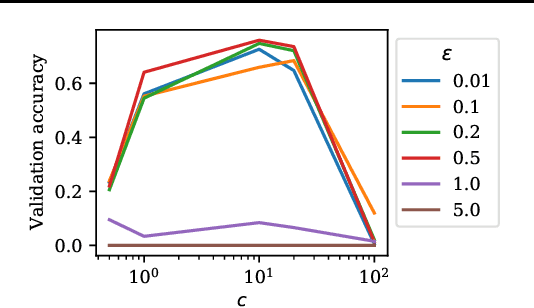
Federated learning is vulnerable to various attacks, such as model poisoning and backdoor attacks, even if some existing defense strategies are used. To address this challenge, we propose an attack-adaptive aggregation strategy to defend against various attacks for robust federated learning. The proposed approach is based on training a neural network with an attention mechanism that learns the vulnerability of federated learning models from a set of plausible attacks. To the best of our knowledge, our aggregation strategy is the first one that can be adapted to defend against various attacks in a data-driven fashion. Our approach has achieved competitive performance in defending model poisoning and backdoor attacks in federated learning tasks on image and text datasets.