 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying Shelf Life Quality of Pineapples by Combining Audio and Visual Features
May 16, 2025Determining the shelf life quality of pineapples using non-destructive methods is a crucial step to reduce waste and increase income. In this paper, a multimodal and multiview classification model was constructed to classify pineapples into four quality levels based on audio and visual characteristics. For research purposes, we compiled and released the PQC500 dataset consisting of 500 pineapples with two modalities: one was tapping pineapples to record sounds by multiple microphones and the other was taking pictures by multiple cameras at different locations, providing multimodal and multi-view audiovisual features. We modified the contrastive audiovisual masked autoencoder to train the cross-modal-based classification model by abundant combinations of audio and visual pairs. In addition, we proposed to sample a compact size of training data for efficient computation. The experiments were evaluated under various data and model configurations, and the results demonstrated that the proposed cross-modal model trained using audio-major sampling can yield 84% accuracy, outperforming the unimodal models of only audio and only visual by 6% and 18%, respectively.
Attention on Global-Local Embedding Spaces in Recommender Systems
Apr 25, 2021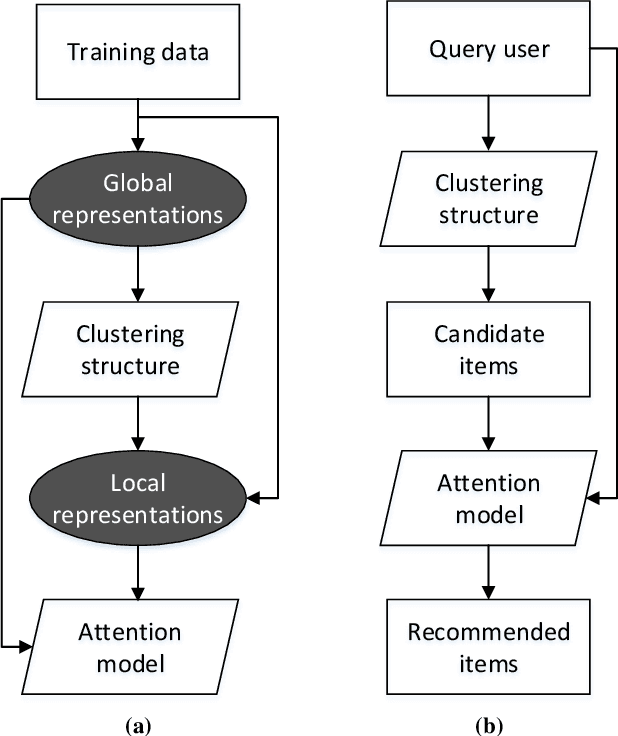

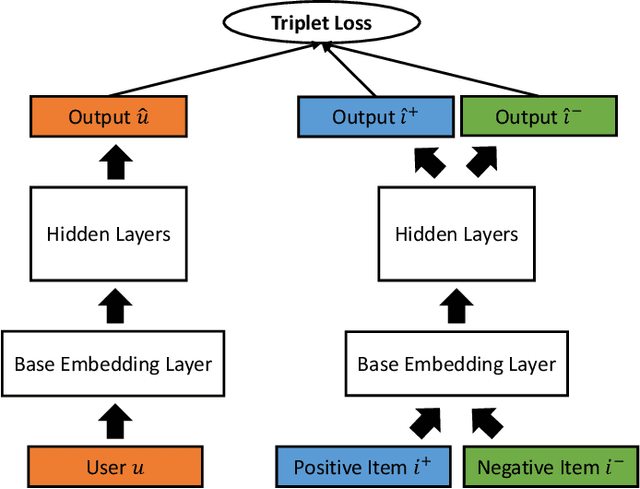
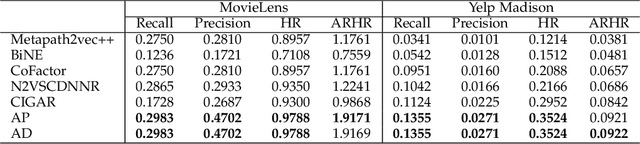
In this study, we present a novel clustering-based collaborative filtering (CF) method for recommender systems. Clustering-based CF methods can effectively deal with data sparsity and scalability problems. However, most of them are applied to a single embedding space, which might not characterize complex user-item interactions well. We argue that user-item interactions should be observed from multiple views and characterized in an adaptive way. To address this issue, we leveraged the relation between global space and local clusters to construct multiple embedding spaces by learning variant training datasets and loss functions. An attention model was then built to provide a dynamic blended representation according to the relative importance of the embedding spaces for each user-item pair, forming a flexible measure to characterize variant user-item interactions. Substantial experiments were performed and evaluated on four popular benchmark datasets. The results show that the proposed method is effective and competitive compared to several CF methods where only one embedding space is considered.
Unifying and Merging Well-trained Deep Neural Networks for Inference Stage
May 14, 2018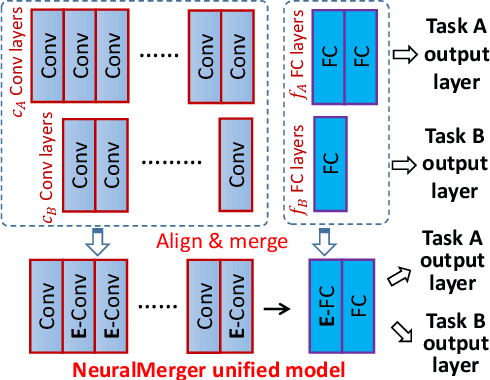

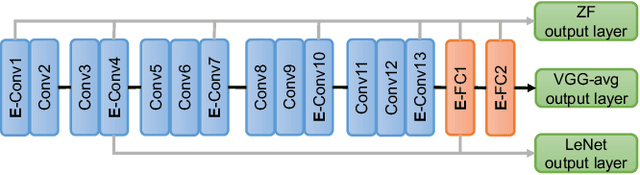

We propose a novel method to merge convolutional neural-nets for the inference stage. Given two well-trained networks that may have different architectures that handle different tasks, our method aligns the layers of the original networks and merges them into a unified model by sharing the representative codes of weights. The shared weights are further re-trained to fine-tune the performance of the merged model. The proposed method effectively produces a compact model that may run original tasks simultaneously on resource-limited devices. As it preserves the general architectures and leverages the co-used weights of well-trained networks, a substantial training overhead can be reduced to shorten the system development time. Experimental results demonstrate a satisfactory performance and validate the effectiveness of the method.