 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Offline Deep Reinforcement Learning for Maintenance Decision-Making
Sep 28, 2021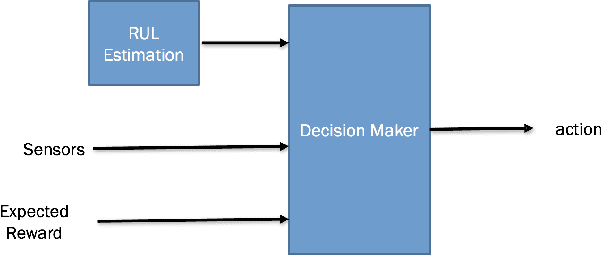
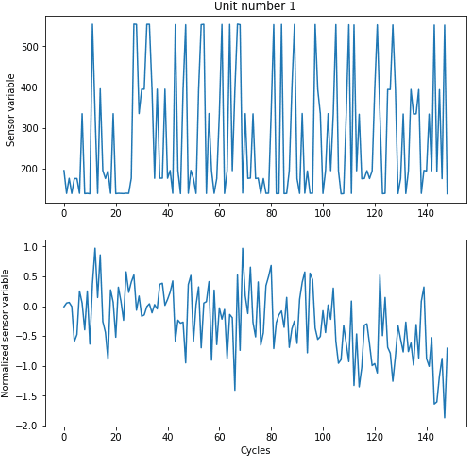
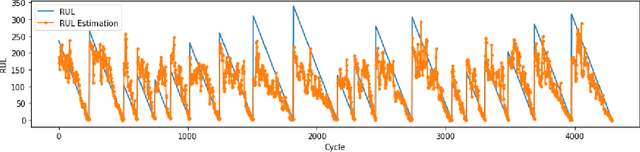
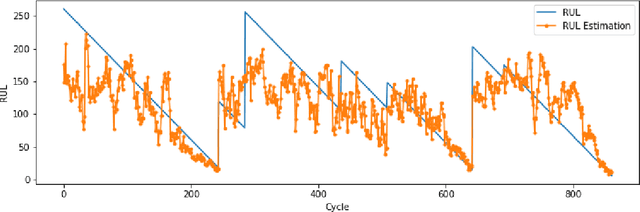
Several machine learning and deep learning frameworks have been proposed to solve remaining useful life estimation and failure prediction problems in recent years. Having access to the remaining useful life estimation or likelihood of failure in near future helps operators to assess the operating conditions and, therefore, provides better opportunities for sound repair and maintenance decisions. However, many operators believe remaining useful life estimation and failure prediction solutions are incomplete answers to the maintenance challenge. They argue that knowing the likelihood of failure in the future is not enough to make maintenance decisions that minimize costs and keep the operators safe. In this paper, we present a maintenance framework based on offline supervised deep reinforcement learning that instead of providing information such as likelihood of failure, suggests actions such as "continuation of the operation" or "the visitation of the repair shop" to the operators in order to maximize the overall profit. Using offline reinforcement learning makes it possible to learn the optimum maintenance policy from historical data without relying on expensive simulators. We demonstrate the application of our solution in a case study using the NASA C-MAPSS dataset.
Deep Reinforcement Learning with Adjustments
Sep 28, 2021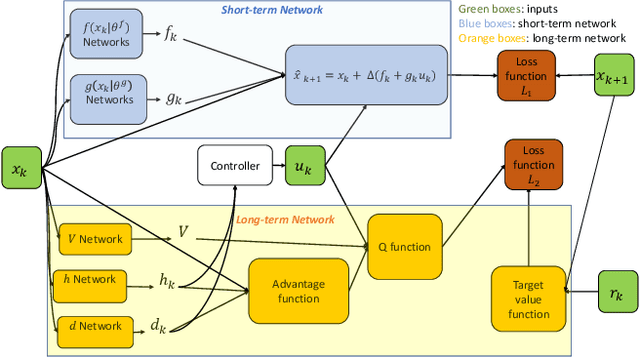
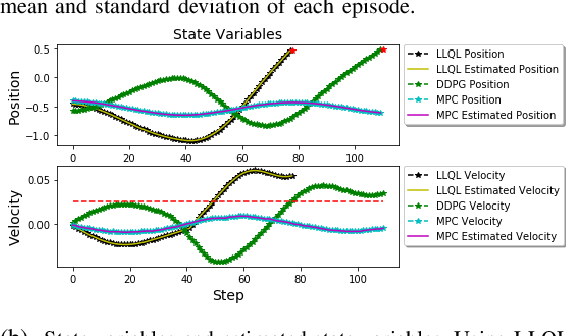
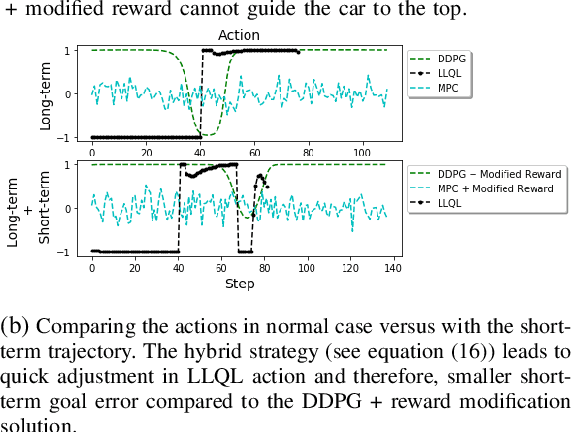
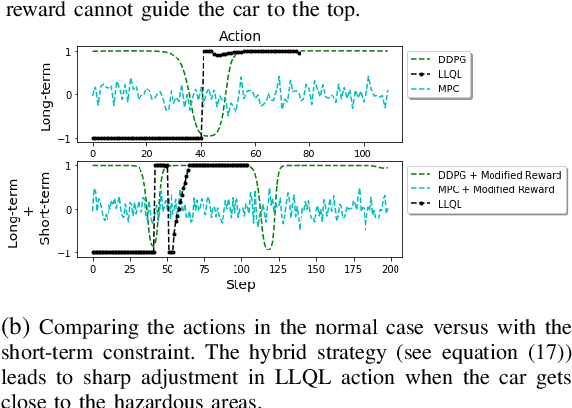
Deep reinforcement learning (RL) algorithms can learn complex policies to optimize agent operation over time. RL algorithms have shown promising results in solving complicated problems in recent years. However, their application on real-world physical systems remains limited. Despite the advancements in RL algorithms, the industries often prefer traditional control strategies. Traditional methods are simple, computationally efficient and easy to adjust. In this paper, we first propose a new Q-learning algorithm for continuous action space, which can bridge the control and RL algorithms and bring us the best of both worlds. Our method can learn complex policies to achieve long-term goals and at the same time it can be easily adjusted to address short-term requirements without retraining. Next, we present an approximation of our algorithm which can be applied to address short-term requirements of any pre-trained RL algorithm. The case studies demonstrate that both our proposed method as well as its practical approximation can achieve short-term and long-term goals without complex reward functions.
Deep Time Series Models for Scarce Data
Mar 16, 2021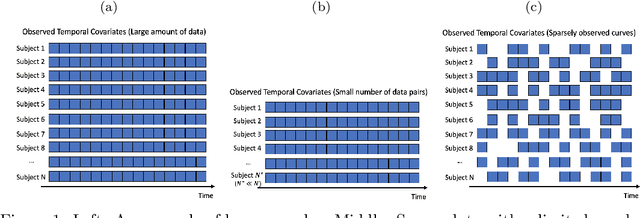
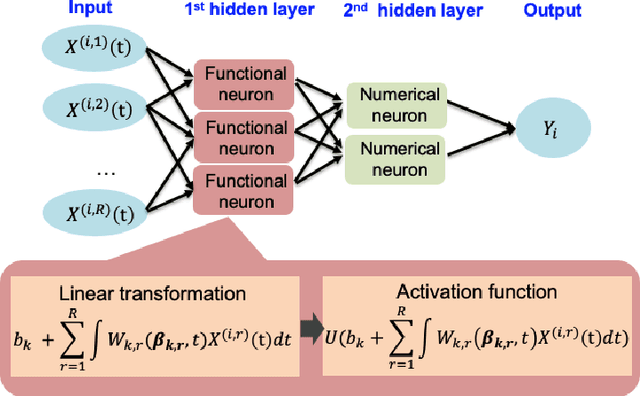
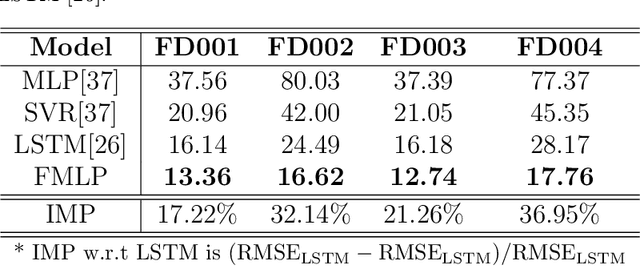
Time series data have grown at an explosive rate in numerous domains and have stimulated a surge of time series modeling research. A comprehensive comparison of different time series models, for a considered data analytics task, provides useful guidance on model selection for data analytics practitioners. Data scarcity is a universal issue that occurs in a vast range of data analytics problems, due to the high costs associated with collecting, generating, and labeling data as well as some data quality issues such as missing data. In this paper, we focus on the temporal classification/regression problem that attempts to build a mathematical mapping from multivariate time series inputs to a discrete class label or a real-valued response variable. For this specific problem, we identify two types of scarce data: scarce data with small samples and scarce data with sparsely and irregularly observed time series covariates. Observing that all existing works are incapable of utilizing the sparse time series inputs for proper modeling building, we propose a model called sparse functional multilayer perceptron (SFMLP) for handling the sparsity in the time series covariates. The effectiveness of the proposed SFMLP under each of the two types of data scarcity, in comparison with the conventional deep sequential learning models (e.g., Recurrent Neural Network, and Long Short-Term Memory), is investigated through mathematical arguments and numerical experiments.
A Non-linear Function-on-Function Model for Regression with Time Series Data
Nov 24, 2020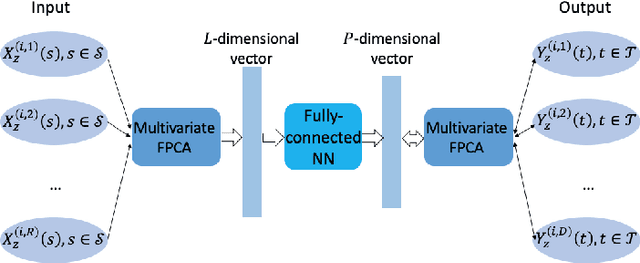
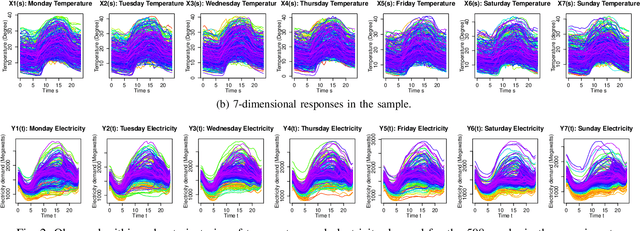
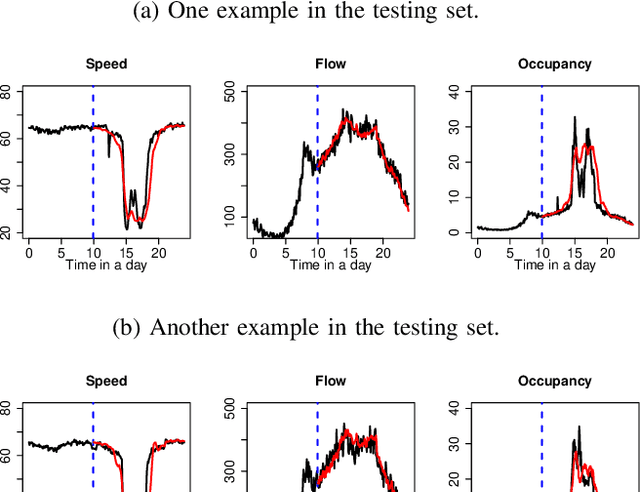

In the last few decades, building regression models for non-scalar variables, including time series, text, image, and video, has attracted increasing interests of researchers from the data analytic community. In this paper, we focus on a multivariate time series regression problem. Specifically, we aim to learn mathematical mappings from multiple chronologically measured numerical variables within a certain time interval S to multiple numerical variables of interest over time interval T. Prior arts, including the multivariate regression model, the Seq2Seq model, and the functional linear models, suffer from several limitations. The first two types of models can only handle regularly observed time series. Besides, the conventional multivariate regression models tend to be biased and inefficient, as they are incapable of encoding the temporal dependencies among observations from the same time series. The sequential learning models explicitly use the same set of parameters along time, which has negative impacts on accuracy. The function-on-function linear model in functional data analysis (a branch of statistics) is insufficient to capture complex correlations among the considered time series and suffer from underfitting easily. In this paper, we propose a general functional mapping that embraces the function-on-function linear model as a special case. We then propose a non-linear function-on-function model using the fully connected neural network to learn the mapping from data, which addresses the aforementioned concerns in the existing approaches. For the proposed model, we describe in detail the corresponding numerical implementation procedures. The effectiveness of the proposed model is demonstrated through the application to two real-world problems.
Wisdom of the Ensemble: Improving Consistency of Deep Learning Models
Nov 13, 2020

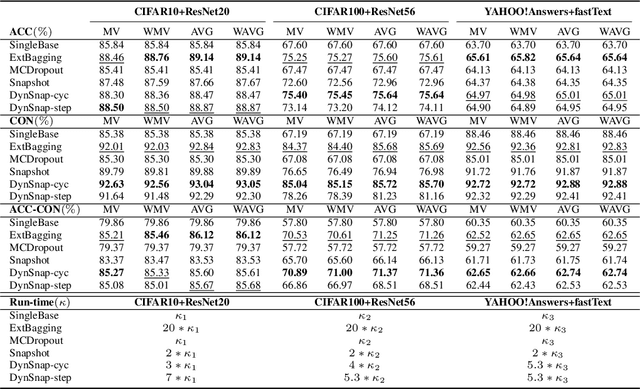
Deep learning classifiers are assisting humans in making decisions and hence the user's trust in these models is of paramount importance. Trust is often a function of constant behavior. From an AI model perspective it means given the same input the user would expect the same output, especially for correct outputs, or in other words consistently correct outputs. This paper studies a model behavior in the context of periodic retraining of deployed models where the outputs from successive generations of the models might not agree on the correct labels assigned to the same input. We formally define consistency and correct-consistency of a learning model. We prove that consistency and correct-consistency of an ensemble learner is not less than the average consistency and correct-consistency of individual learners and correct-consistency can be improved with a probability by combining learners with accuracy not less than the average accuracy of ensemble component learners. To validate the theory using three datasets and two state-of-the-art deep learning classifiers we also propose an efficient dynamic snapshot ensemble method and demonstrate its value.
Challenges of Applying Deep Reinforcement Learning in Dynamic Dispatching
Nov 09, 2020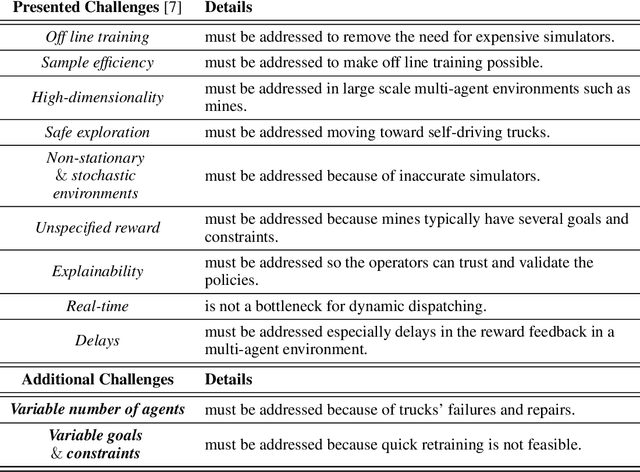
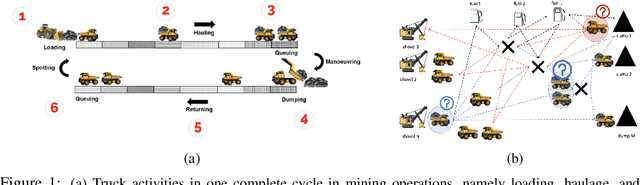
Dynamic dispatching aims to smartly allocate the right resources to the right place at the right time. Dynamic dispatching is one of the core problems for operations optimization in the mining industry. Theoretically, deep reinforcement learning (RL) should be a natural fit to solve this problem. However, the industry relies on heuristics or even human intuitions, which are often short-sighted and sub-optimal solutions. In this paper, we review the main challenges in using deep RL to address the dynamic dispatching problem in the mining industry.
Spatio-Temporal Functional Neural Networks
Sep 11, 2020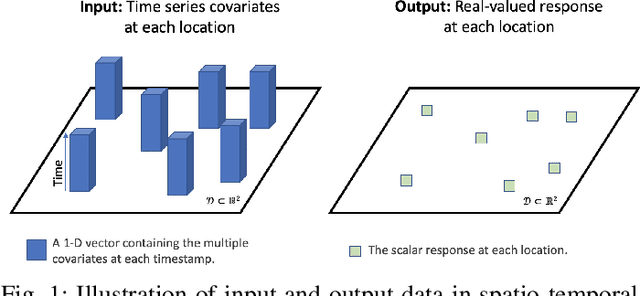
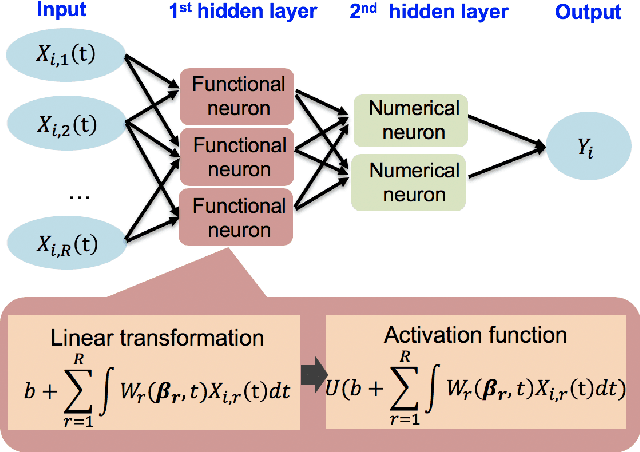
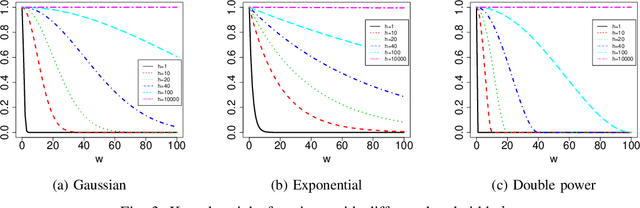
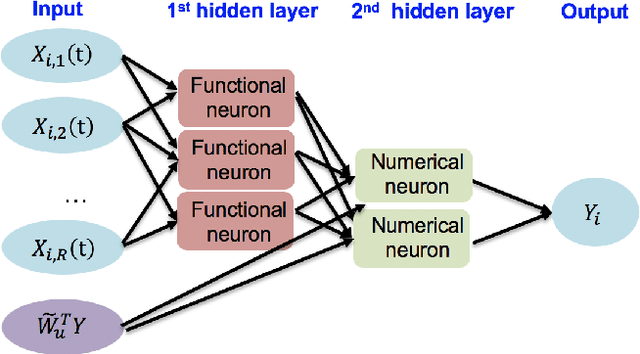
Explosive growth in spatio-temporal data and its wide range of applications have attracted increasing interests of researchers in the statistical and machine learning fields. The spatio-temporal regression problem is of paramount importance from both the methodology development and real-world application perspectives. Given the observed spatially encoded time series covariates and real-valued response data samples, the goal of spatio-temporal regression is to leverage the temporal and spatial dependencies to build a mapping from covariates to response with minimized prediction error. Prior arts, including the convolutional Long Short-Term Memory (CovLSTM) and variations of the functional linear models, cannot learn the spatio-temporal information in a simple and efficient format for proper model building. In this work, we propose two novel extensions of the Functional Neural Network (FNN), a temporal regression model whose effectiveness and superior performance over alternative sequential models have been proven by many researchers. The effectiveness of the proposed spatio-temporal FNNs in handling varying spatial correlations is demonstrated in comprehensive simulation studies. The proposed models are then deployed to solve a practical and challenging precipitation prediction problem in the meteorology field.
Dynamic Dispatching for Large-Scale Heterogeneous Fleet via Multi-agent Deep Reinforcement Learning
Aug 24, 2020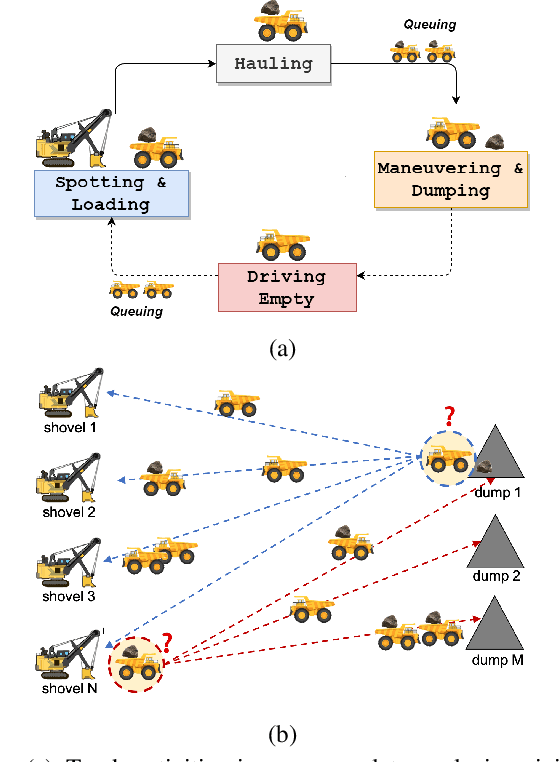
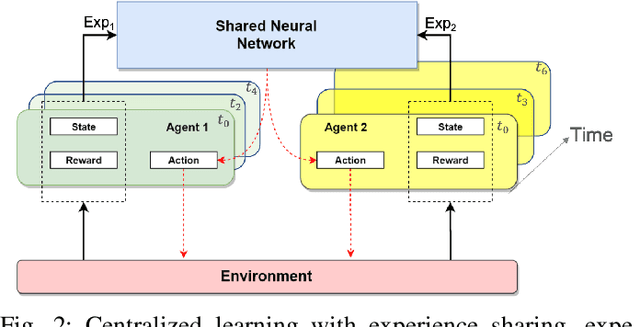
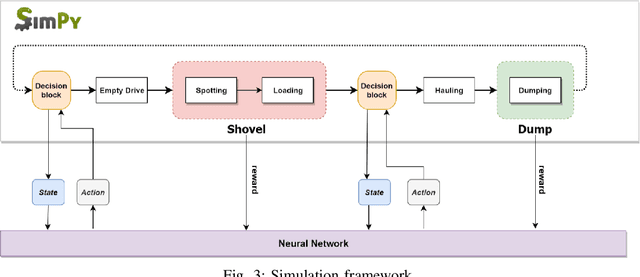
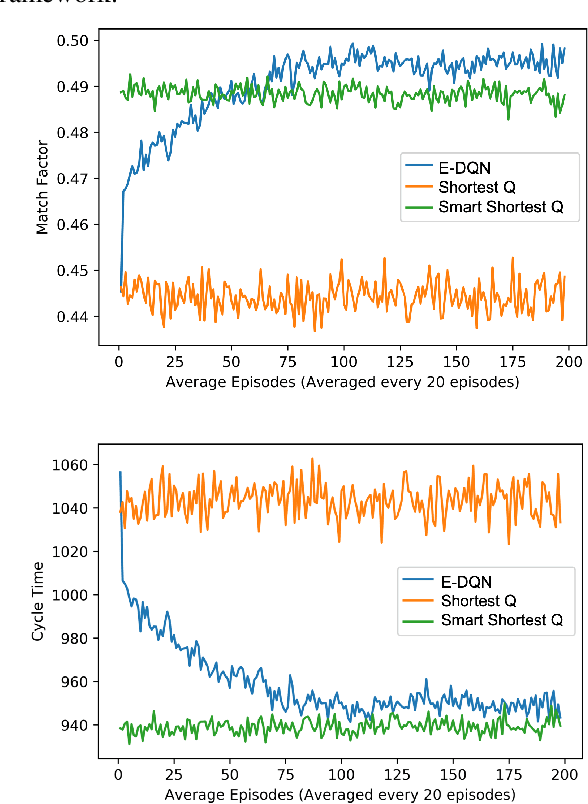
Dynamic dispatching is one of the core problems for operation optimization in traditional industries such as mining, as it is about how to smartly allocate the right resources to the right place at the right time. Conventionally, the industry relies on heuristics or even human intuitions which are often short-sighted and sub-optimal solutions. Leveraging the power of AI and Internet of Things (IoT), data-driven automation is reshaping this area. However, facing its own challenges such as large-scale and heterogenous trucks running in a highly dynamic environment, it can barely adopt methods developed in other domains (e.g., ride-sharing). In this paper, we propose a novel Deep Reinforcement Learning approach to solve the dynamic dispatching problem in mining. We first develop an event-based mining simulator with parameters calibrated in real mines. Then we propose an experience-sharing Deep Q Network with a novel abstract state/action representation to learn memories from heterogeneous agents altogether and realizes learning in a centralized way. We demonstrate that the proposed methods significantly outperform the most widely adopted approaches in the industry by $5.56\%$ in terms of productivity. The proposed approach has great potential in a broader range of industries (e.g., manufacturing, logistics) which have a large-scale of heterogenous equipment working in a highly dynamic environment, as a general framework for dynamic resource allocation.
Health Indicator Forecasting for Improving Remaining Useful Life Estimation
Jun 05, 2020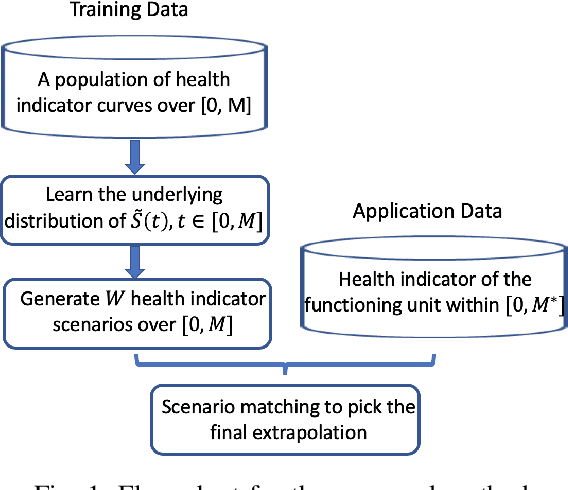
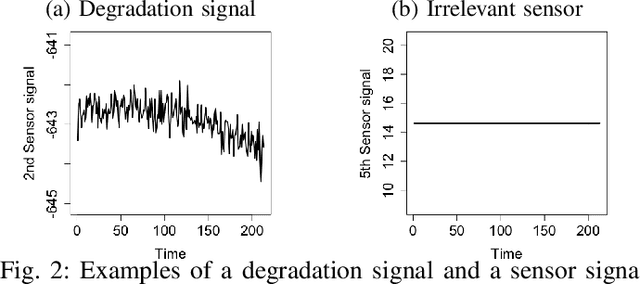
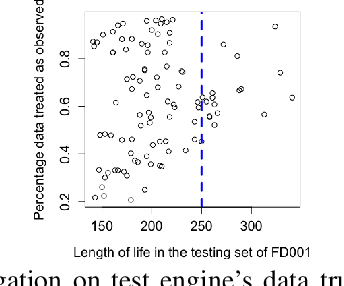
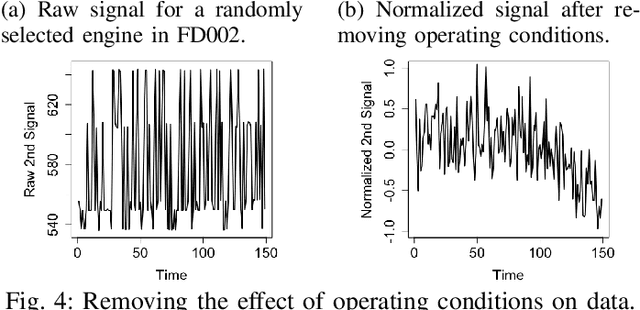
Prognostics is concerned with predicting the future health of the equipment and any potential failures. With the advances in the Internet of Things (IoT), data-driven approaches for prognostics that leverage the power of machine learning models are gaining popularity. One of the most important categories of data-driven approaches relies on a predefined or learned health indicator to characterize the equipment condition up to the present time and make inference on how it is likely to evolve in the future. In these approaches, health indicator forecasting that constructs the health indicator curve over the lifespan using partially observed measurements (i.e., health indicator values within an initial period) plays a key role. Existing health indicator forecasting algorithms, such as the functional Empirical Bayesian approach, the regression-based formulation, a naive scenario matching based on the nearest neighbor, have certain limitations. In this paper, we propose a new `generative + scenario matching' algorithm for health indicator forecasting. The key idea behind the proposed approach is to first non-parametrically fit the underlying health indicator curve with a continuous Gaussian Process using a sample of run-to-failure health indicator curves. The proposed approach then generates a rich set of random curves from the learned distribution, attempting to obtain all possible variations of the target health condition evolution process over the system's lifespan. The health indicator extrapolation for a piece of functioning equipment is inferred as the generated curve that has the highest matching level within the observed period. Our experimental results show the superiority of our algorithm over the other state-of-the-art methods.
Building chatbots from large scale domain-specific knowledge bases: challenges and opportunities
Dec 31, 2019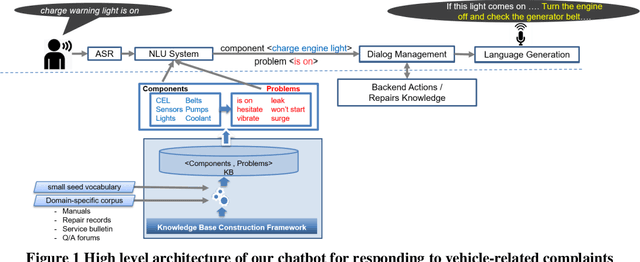

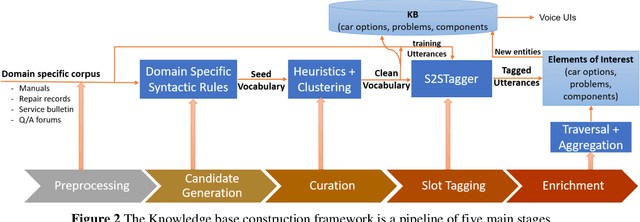

Popular conversational agents frameworks such as Alexa Skills Kit (ASK) and Google Actions (gActions) offer unprecedented opportunities for facilitating the development and deployment of voice-enabled AI solutions in various verticals. Nevertheless, understanding user utterances with high accuracy remains a challenging task with these frameworks. Particularly, when building chatbots with large volume of domain-specific entities. In this paper, we describe the challenges and lessons learned from building a large scale virtual assistant for understanding and responding to equipment-related complaints. In the process, we describe an alternative scalable framework for: 1) extracting the knowledge about equipment components and their associated problem entities from short texts, and 2) learning to identify such entities in user utterances. We show through evaluation on a real dataset that the proposed framework, compared to off-the-shelf popular ones, scales better with large volume of entities being up to 30% more accurate, and is more effective in understanding user utterances with domain-specific entities.