 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Source-Channel Noise Adding with Adaptive Denoising for Diffusion-Based Semantic Communications
May 11, 2025



Semantic communication (SemCom) aims to convey the intended meaning of messages rather than merely transmitting bits, thereby offering greater efficiency and robustness, particularly in resource-constrained or noisy environments. In this paper, we propose a novel framework which is referred to as joint source-channel noise adding with adaptive denoising (JSCNA-AD) for SemCom based on a diffusion model (DM). Unlike conventional encoder-decoder designs, our approach intentionally incorporates the channel noise during transmission, effectively transforming the harmful channel noise into a constructive component of the diffusion-based semantic reconstruction process. Besides, we introduce an attention-based adaptive denoising mechanism, in which transmitted images are divided into multiple regions, and the number of denoising steps is dynamically allocated based on the semantic importance of each region. This design effectively balances the reception quality and the inference latency by prioritizing the critical semantic information. Extensive experiments demonstrate that our method significantly outperforms existing SemCom schemes under various noise conditions, underscoring the potential of diffusion-based models in next-generation communication systems.
Image Generation with Multimodule Semantic Feature-Aided Selection for Semantic Communications
Nov 26, 2024Semantic communication (SemCom) has emerged as a promising technique for the next-generation communication systems, in which the generation at the receiver side is allowed without semantic features' recovery. However, the majority of existing research predominantly utilizes a singular type of semantic information, such as text, images, or speech, to supervise and choose the generated source signals, which may not sufficiently encapsulate the comprehensive and accurate semantic information, and thus creating a performance bottleneck. In order to bridge this gap, in this paper, we propose and investigate a multimodal information-aided SemCom framework (MMSemCom) for image transmission. To be specific, in this framework, we first extract semantic features at both the image and text levels utilizing the Convolutional Neural Network (CNN) architecture and the Contrastive Language-Image Pre-Training (CLIP) model before transmission. Then, we employ a generative diffusion model at the receiver to generate multiple images. In order to ensure the accurate extraction and facilitate high-fidelity image reconstruction, we select the "best" image with the minimum reconstruction errors by taking both the aided image and text semantic features into account. We further extend MMSemCom to the multiuser scenario for orthogonal transmission. Experimental results demonstrate that the proposed framework can not only achieve the enhanced fidelity and robustness in image transmission compared with existing communication systems but also sustain a high performance in the low signal-to-noise ratio (SNR) conditions.
Domain Adaptive Object Detection via Feature Separation and Alignment
Dec 16, 2020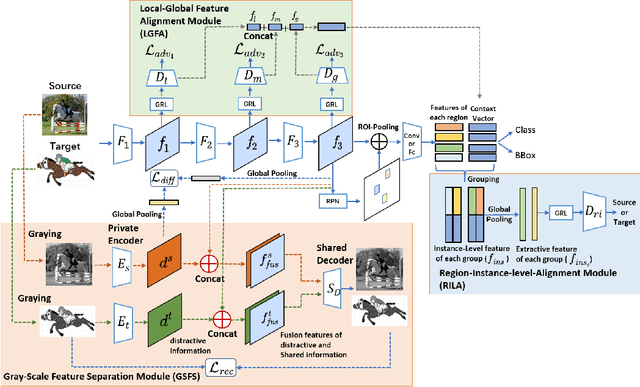
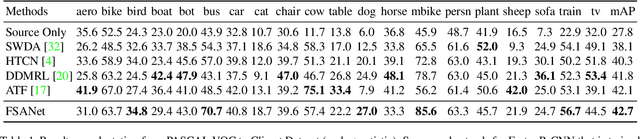
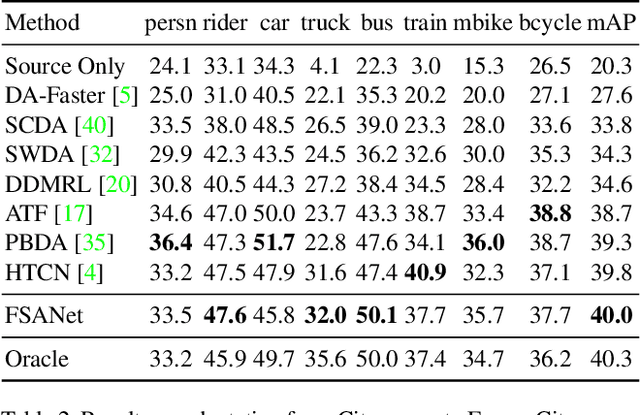

Recently, adversarial-based domain adaptive object detection (DAOD) methods have been developed rapidly. However, there are two issues that need to be resolved urgently. Firstly, numerous methods reduce the distributional shifts only by aligning all the feature between the source and target domain, while ignoring the private information of each domain. Secondly, DAOD should consider the feature alignment on object existing regions in images. But redundancy of the region proposals and background noise could reduce the domain transferability. Therefore, we establish a Feature Separation and Alignment Network (FSANet) which consists of a gray-scale feature separation (GSFS) module, a local-global feature alignment (LGFA) module and a region-instance-level alignment (RILA) module. The GSFS module decomposes the distractive/shared information which is useless/useful for detection by a dual-stream framework, to focus on intrinsic feature of objects and resolve the first issue. Then, LGFA and RILA modules reduce the distributional shifts of the multi-level features. Notably, scale-space filtering is exploited to implement adaptive searching for regions to be aligned, and instance-level features in each region are refined to reduce redundancy and noise mentioned in the second issue. Various experiments on multiple benchmark datasets prove that our FSANet achieves better performance on the target domain detection and surpasses the state-of-the-art methods.