 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering via Boundary Erosion
Apr 13, 2018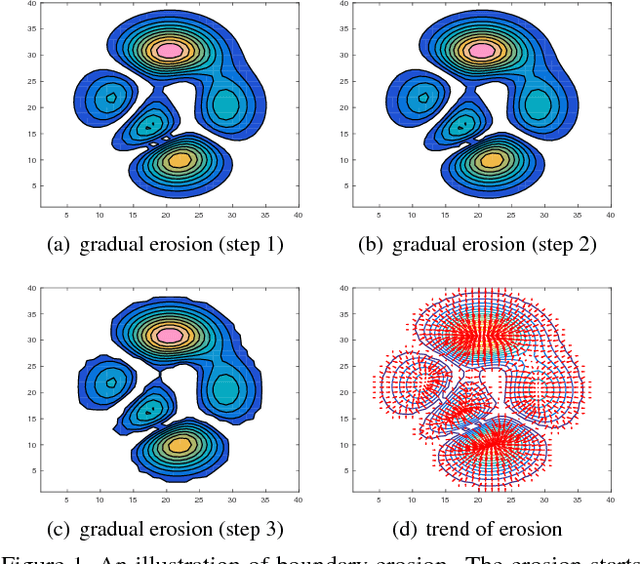

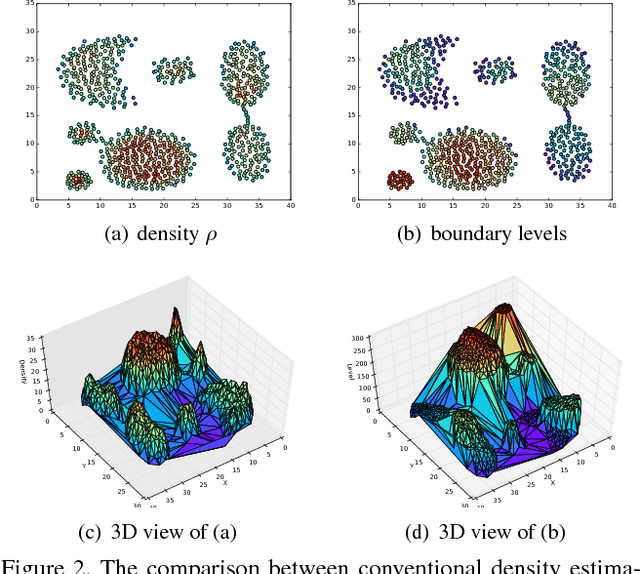
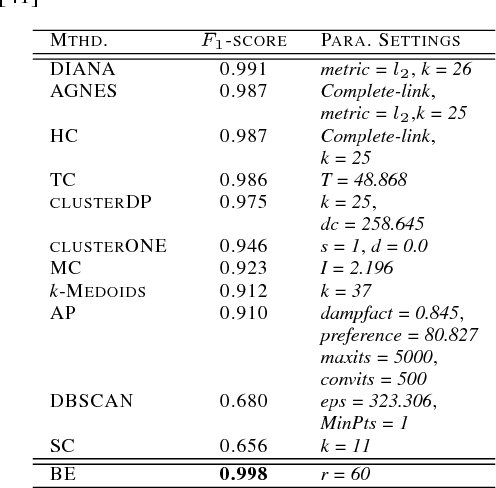
Clustering analysis identifies samples as groups based on either their mutual closeness or homogeneity. In order to detect clusters in arbitrary shapes, a novel and generic solution based on boundary erosion is proposed. The clusters are assumed to be separated by relatively sparse regions. The samples are eroded sequentially according to their dynamic boundary densities. The erosion starts from low density regions, invading inwards, until all the samples are eroded out. By this manner, boundaries between different clusters become more and more apparent. It therefore offers a natural and powerful way to separate the clusters when the boundaries between them are hard to be drawn at once. With the sequential order of being eroded, the sequential boundary levels are produced, following which the clusters in arbitrary shapes are automatically reconstructed. As demonstrated across various clustering tasks, it is able to outperform most of the state-of-the-art algorithms and its performance is nearly perfect in some scenarios.
Fast k-means based on KNN Graph
May 04, 2017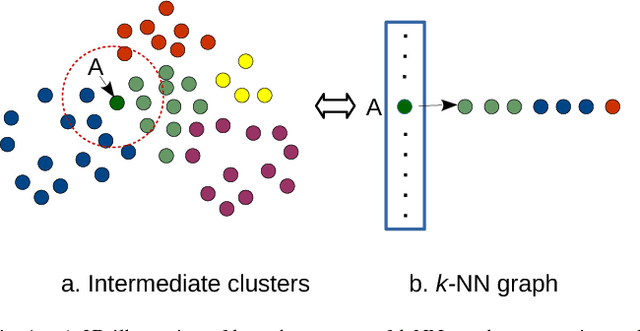
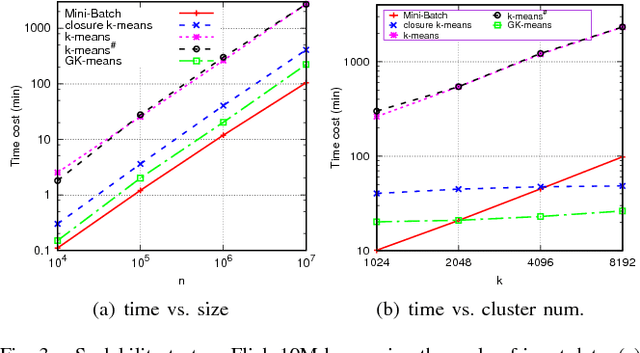
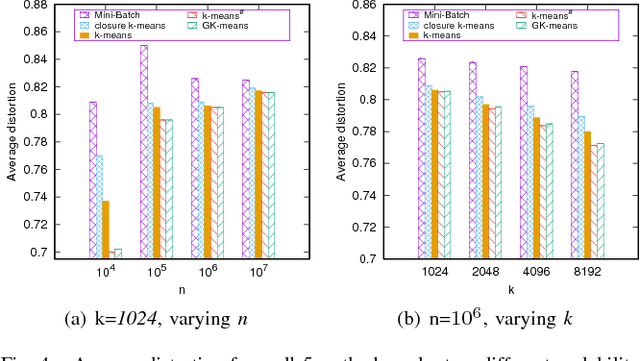
In the era of big data, k-means clustering has been widely adopted as a basic processing tool in various contexts. However, its computational cost could be prohibitively high as the data size and the cluster number are large. It is well known that the processing bottleneck of k-means lies in the operation of seeking closest centroid in each iteration. In this paper, a novel solution towards the scalability issue of k-means is presented. In the proposal, k-means is supported by an approximate k-nearest neighbors graph. In the k-means iteration, each data sample is only compared to clusters that its nearest neighbors reside. Since the number of nearest neighbors we consider is much less than k, the processing cost in this step becomes minor and irrelevant to k. The processing bottleneck is therefore overcome. The most interesting thing is that k-nearest neighbor graph is constructed by iteratively calling the fast $k$-means itself. Comparing with existing fast k-means variants, the proposed algorithm achieves hundreds to thousands times speed-up while maintaining high clustering quality. As it is tested on 10 million 512-dimensional data, it takes only 5.2 hours to produce 1 million clusters. In contrast, to fulfill the same scale of clustering, it would take 3 years for traditional k-means.
Scalable Nearest Neighbor Search based on kNN Graph
Feb 03, 2017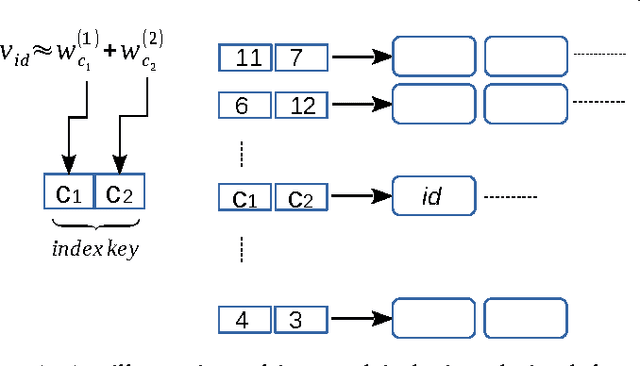
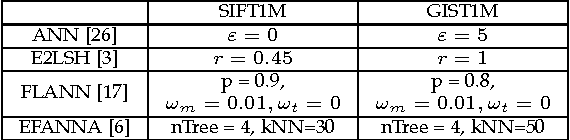
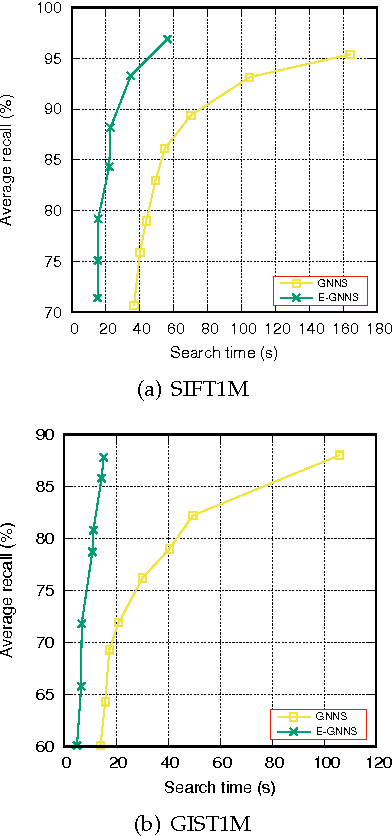
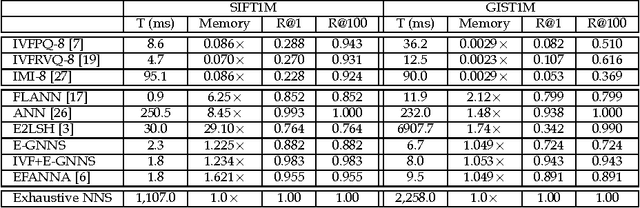
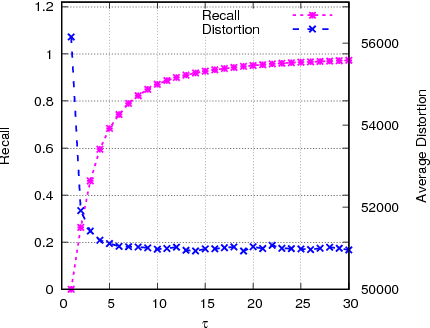
Nearest neighbor search is known as a challenging issue that has been studied for several decades. Recently, this issue becomes more and more imminent in viewing that the big data problem arises from various fields. In this paper, a scalable solution based on hill-climbing strategy with the support of k-nearest neighbor graph (kNN) is presented. Two major issues have been considered in the paper. Firstly, an efficient kNN graph construction method based on two means tree is presented. For the nearest neighbor search, an enhanced hill-climbing procedure is proposed, which sees considerable performance boost over original procedure. Furthermore, with the support of inverted indexing derived from residue vector quantization, our method achieves close to 100% recall with high speed efficiency in two state-of-the-art evaluation benchmarks. In addition, a comparative study on both the compressional and traditional nearest neighbor search methods is presented. We show that our method achieves the best trade-off between search quality, efficiency and memory complexity.
Boost K-Means
Dec 04, 2016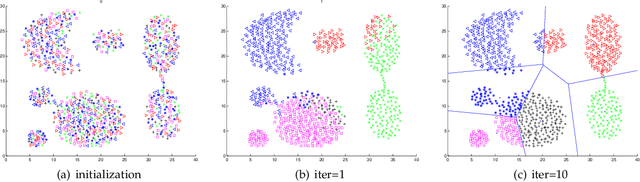
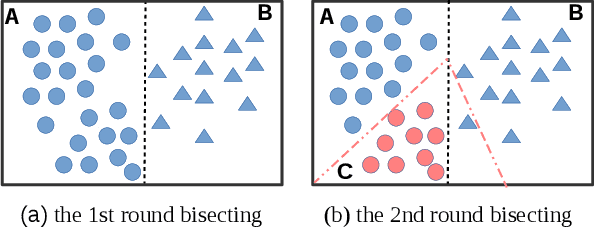
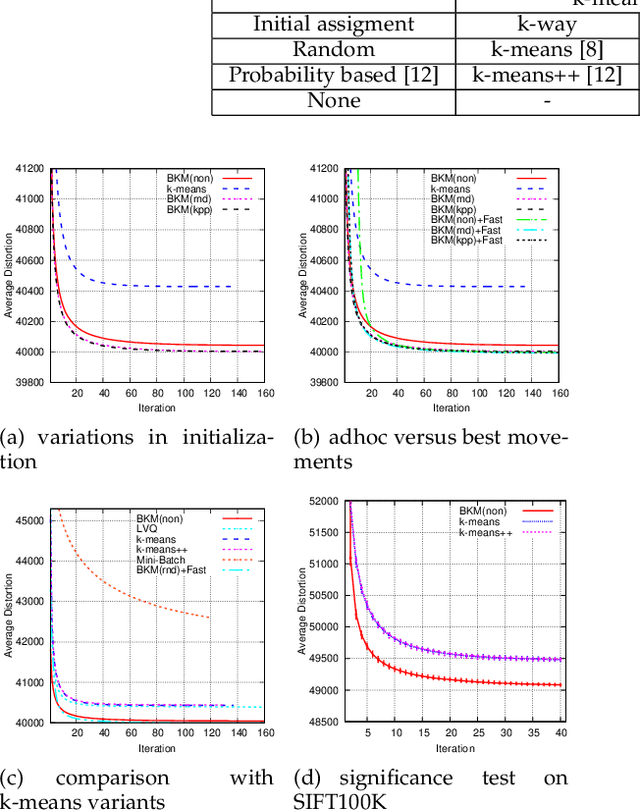
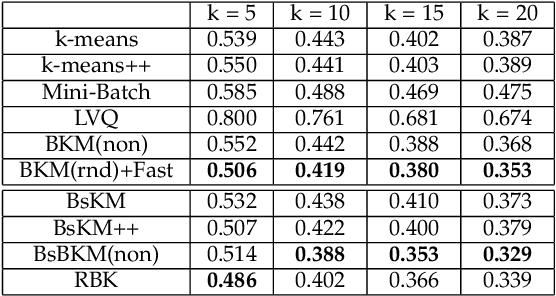
Due to its simplicity and versatility, k-means remains popular since it was proposed three decades ago. The performance of k-means has been enhanced from different perspectives over the years. Unfortunately, a good trade-off between quality and efficiency is hardly reached. In this paper, a novel k-means variant is presented. Different from most of k-means variants, the clustering procedure is driven by an explicit objective function, which is feasible for the whole l2-space. The classic egg-chicken loop in k-means has been simplified to a pure stochastic optimization procedure. The procedure of k-means becomes simpler and converges to a considerably better local optima. The effectiveness of this new variant has been studied extensively in different contexts, such as document clustering, nearest neighbor search and image clustering. Superior performance is observed across different scenarios.