 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Principled Self-Referenced Early Stopping Approach for Deep Image Prior
May 27, 2026Recently, Deep Image Prior (DIP) has demonstrated strong capabilities for solving inverse imaging problems (IIPs) by optimizing a randomly initialized convolutional neural network in a training-data-free regime. However, DIP suffers from overfitting to noisy measurements due to network over-parameterization, making early stopping (ES) essential. The most successful ES method tracks fluctuations in the running variance of the network output to detect overfitting. However, in many applications, these fluctuations may appear prematurely, leading to unstable reconstructions. In this paper, we first show that nearly optimal DIP early stopping can be achieved when two independent noisy copies of the degraded image are available. Motivated by this observation, and since obtaining two fully independent copies is infeasible, we propose an overfitting detection framework based on constructing pseudo self-referenced images, resulting in three IIP-specific algorithms. Our approach is further supported by theoretical results on single-reference validation, pseudo-validation estimation, and the impact of shared noise. Across different IIPs, ranging from natural image restoration to medical image reconstruction, and under varying noise levels and noise types, our methods consistently outperform existing DIP early stopping approaches, all without requiring an accurate estimate of the noise level.
SITCOM: Step-wise Triple-Consistent Diffusion Sampling for Inverse Problems
Oct 06, 2024



Diffusion models (DMs) are a class of generative models that allow sampling from a distribution learned over a training set. When applied to solving inverse imaging problems (IPs), the reverse sampling steps of DMs are typically modified to approximately sample from a measurement-conditioned distribution in the image space. However, these modifications may be unsuitable for certain settings (such as in the presence of measurement noise) and non-linear tasks, as they often struggle to correct errors from earlier sampling steps and generally require a large number of optimization and/or sampling steps. To address these challenges, we state three conditions for achieving measurement-consistent diffusion trajectories. Building on these conditions, we propose a new optimization-based sampling method that not only enforces the standard data manifold measurement consistency and forward diffusion consistency, as seen in previous studies, but also incorporates backward diffusion consistency that maintains a diffusion trajectory by optimizing over the input of the pre-trained model at every sampling step. By enforcing these conditions, either implicitly or explicitly, our sampler requires significantly fewer reverse steps. Therefore, we refer to our accelerated method as Step-wise Triple-Consistent Sampling (SITCOM). Compared to existing state-of-the-art baseline methods, under different levels of measurement noise, our extensive experiments across five linear and three non-linear image restoration tasks demonstrate that SITCOM achieves competitive or superior results in terms of standard image similarity metrics while requiring a significantly reduced run-time across all considered tasks.
Few-Shot and Continual Learning with Attentive Independent Mechanisms
Jul 29, 2021
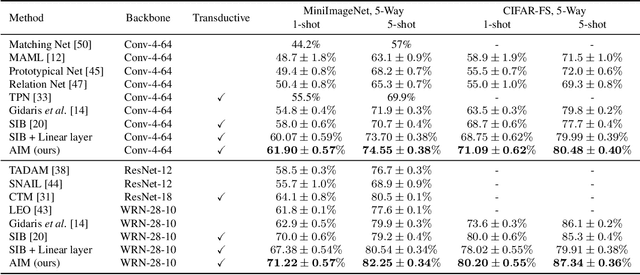


Deep neural networks (DNNs) are known to perform well when deployed to test distributions that shares high similarity with the training distribution. Feeding DNNs with new data sequentially that were unseen in the training distribution has two major challenges -- fast adaptation to new tasks and catastrophic forgetting of old tasks. Such difficulties paved way for the on-going research on few-shot learning and continual learning. To tackle these problems, we introduce Attentive Independent Mechanisms (AIM). We incorporate the idea of learning using fast and slow weights in conjunction with the decoupling of the feature extraction and higher-order conceptual learning of a DNN. AIM is designed for higher-order conceptual learning, modeled by a mixture of experts that compete to learn independent concepts to solve a new task. AIM is a modular component that can be inserted into existing deep learning frameworks. We demonstrate its capability for few-shot learning by adding it to SIB and trained on MiniImageNet and CIFAR-FS, showing significant improvement. AIM is also applied to ANML and OML trained on Omniglot, CIFAR-100 and MiniImageNet to demonstrate its capability in continual learning. Code made publicly available at https://github.com/huang50213/AIM-Fewshot-Continual.