 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Bias in Active Learning with Depth Uncertainty Networks or Not
Dec 13, 2021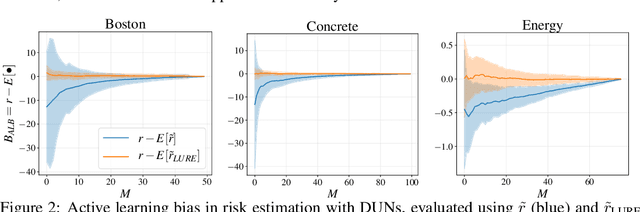
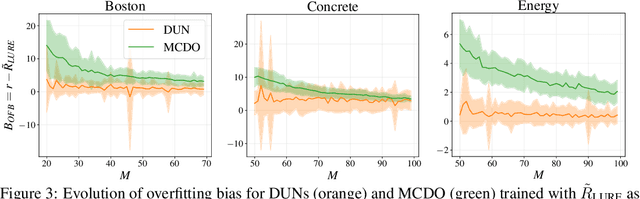
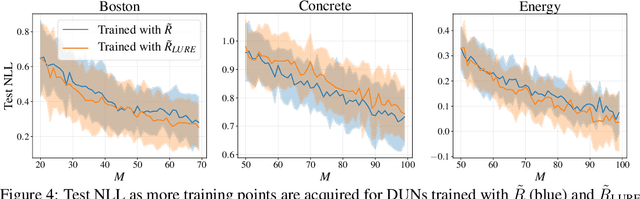
Farquhar et al. [2021] show that correcting for active learning bias with underparameterised models leads to improved downstream performance. For overparameterised models such as NNs, however, correction leads either to decreased or unchanged performance. They suggest that this is due to an "overfitting bias" which offsets the active learning bias. We show that depth uncertainty networks operate in a low overfitting regime, much like underparameterised models. They should therefore see an increase in performance with bias correction. Surprisingly, they do not. We propose that this negative result, as well as the results Farquhar et al. [2021], can be explained via the lens of the bias-variance decomposition of generalisation error.
Depth Uncertainty Networks for Active Learning
Dec 13, 2021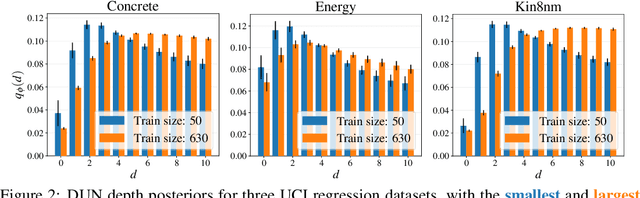
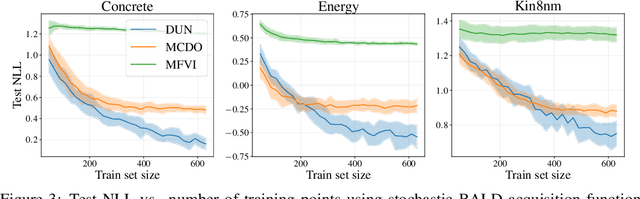
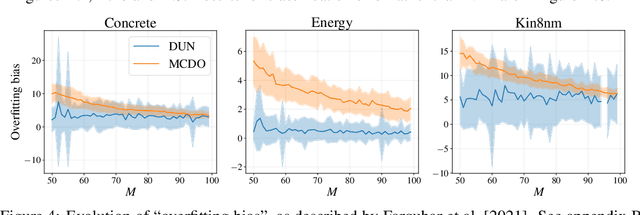
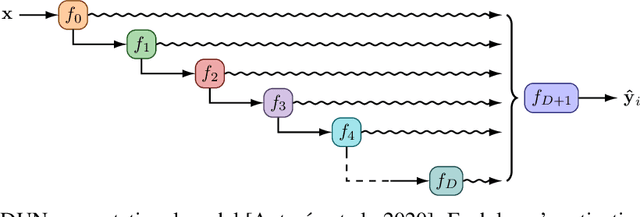
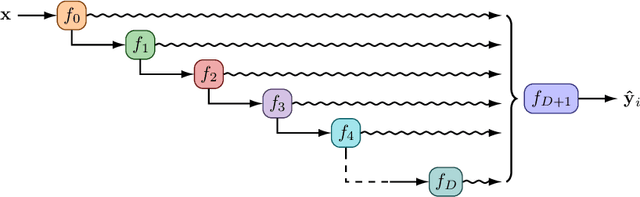
In active learning, the size and complexity of the training dataset changes over time. Simple models that are well specified by the amount of data available at the start of active learning might suffer from bias as more points are actively sampled. Flexible models that might be well suited to the full dataset can suffer from overfitting towards the start of active learning. We tackle this problem using Depth Uncertainty Networks (DUNs), a BNN variant in which the depth of the network, and thus its complexity, is inferred. We find that DUNs outperform other BNN variants on several active learning tasks. Importantly, we show that on the tasks in which DUNs perform best they present notably less overfitting than baselines.