 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Machine Learning Methods and Challenges for Windows Malware Classification
Jun 15, 2020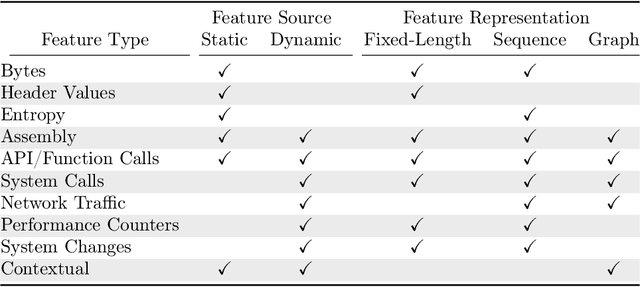
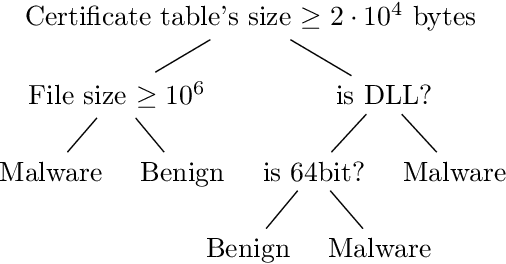

Malware classification is a difficult problem, to which machine learning methods have been applied for decades. Yet progress has often been slow, in part due to a number of unique difficulties with the task that occur through all stages of the developing a machine learning system: data collection, labeling, feature creation and selection, model selection, and evaluation. In this survey we will review a number of the current methods and challenges related to malware classification, including data collection, feature extraction, and model construction, and evaluation. Our discussion will include thoughts on the constraints that must be considered for machine learning based solutions in this domain, and yet to be tackled problems for which machine learning could also provide a solution. This survey aims to be useful both to cybersecurity practitioners who wish to learn more about how machine learning can be applied to the malware problem, and to give data scientists the necessary background into the challenges in this uniquely complicated space.
A New Burrows Wheeler Transform Markov Distance
Dec 30, 2019
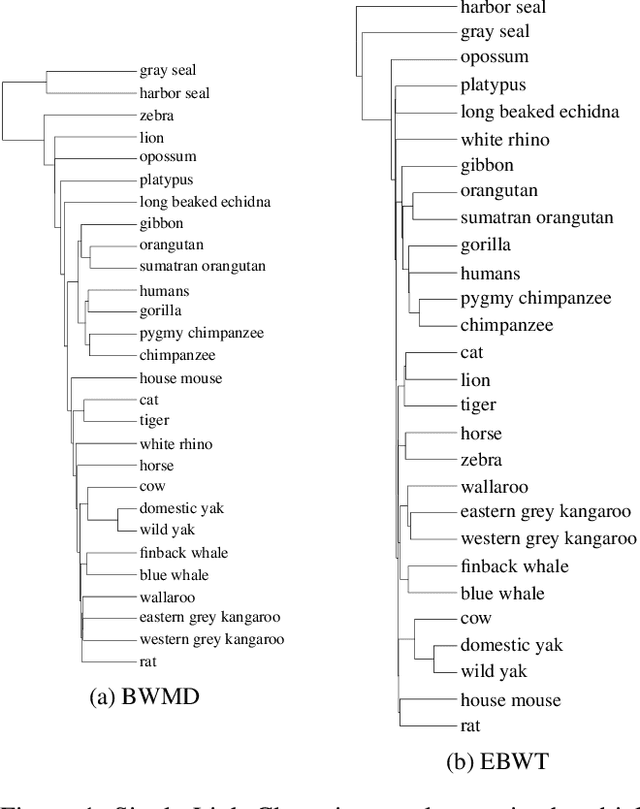
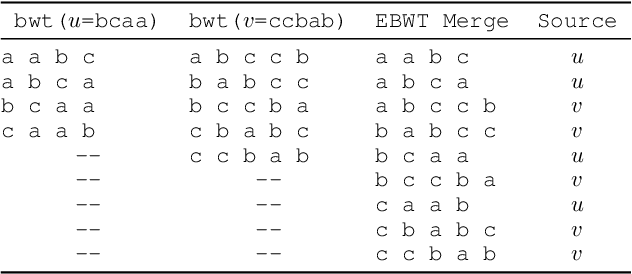
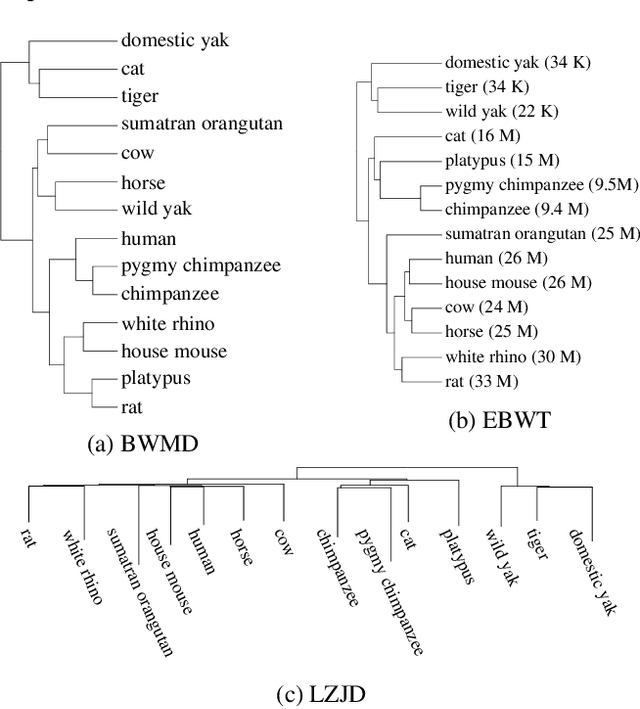
Prior work inspired by compression algorithms has described how the Burrows Wheeler Transform can be used to create a distance measure for bioinformatics problems. We describe issues with this approach that were not widely known, and introduce our new Burrows Wheeler Markov Distance (BWMD) as an alternative. The BWMD avoids the shortcomings of earlier efforts, and allows us to tackle problems in variable length DNA sequence clustering. BWMD is also more adaptable to other domains, which we demonstrate on malware classification tasks. Unlike other compression-based distance metrics known to us, BWMD works by embedding sequences into a fixed-length feature vector. This allows us to provide significantly improved clustering performance on larger malware corpora, a weakness of prior methods.
KiloGrams: Very Large N-Grams for Malware Classification
Aug 01, 2019
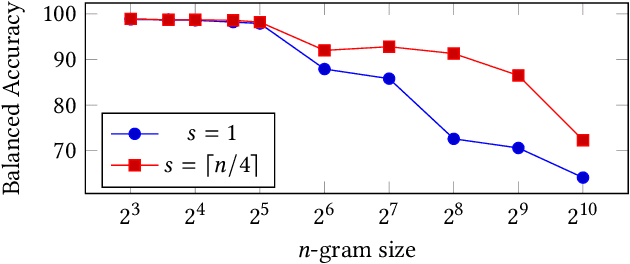
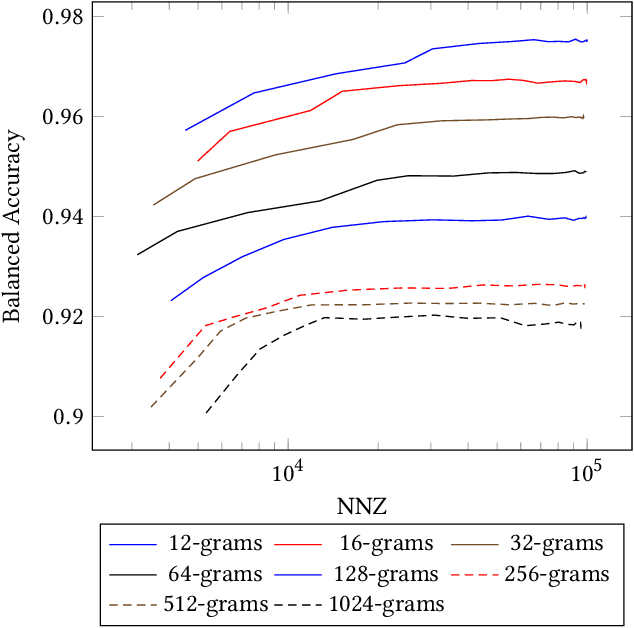
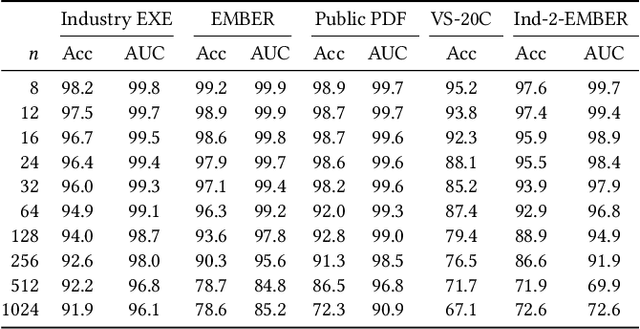
N-grams have been a common tool for information retrieval and machine learning applications for decades. In nearly all previous works, only a few values of $n$ are tested, with $n > 6$ being exceedingly rare. Larger values of $n$ are not tested due to computational burden or the fear of overfitting. In this work, we present a method to find the top-$k$ most frequent $n$-grams that is 60$\times$ faster for small $n$, and can tackle large $n\geq1024$. Despite the unprecedented size of $n$ considered, we show how these features still have predictive ability for malware classification tasks. More important, large $n$-grams provide benefits in producing features that are interpretable by malware analysis, and can be used to create general purpose signatures compatible with industry standard tools like Yara. Furthermore, the counts of common $n$-grams in a file may be added as features to publicly available human-engineered features that rival efficacy of professionally-developed features when used to train gradient-boosted decision tree models on the EMBER dataset.
Engineering a Simplified 0-Bit Consistent Weighted Sampling
Oct 23, 2018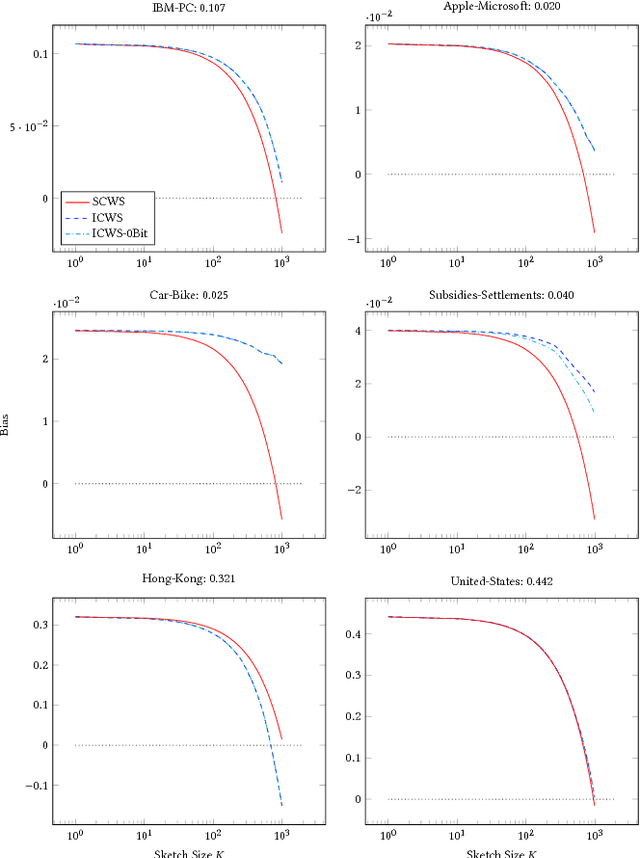
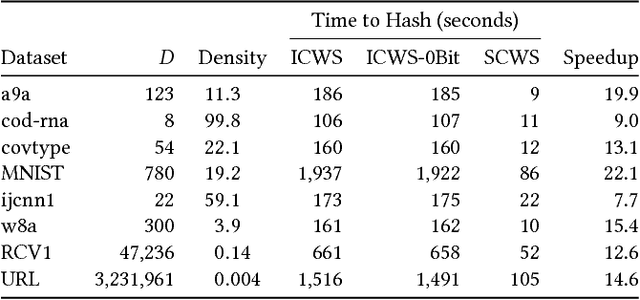
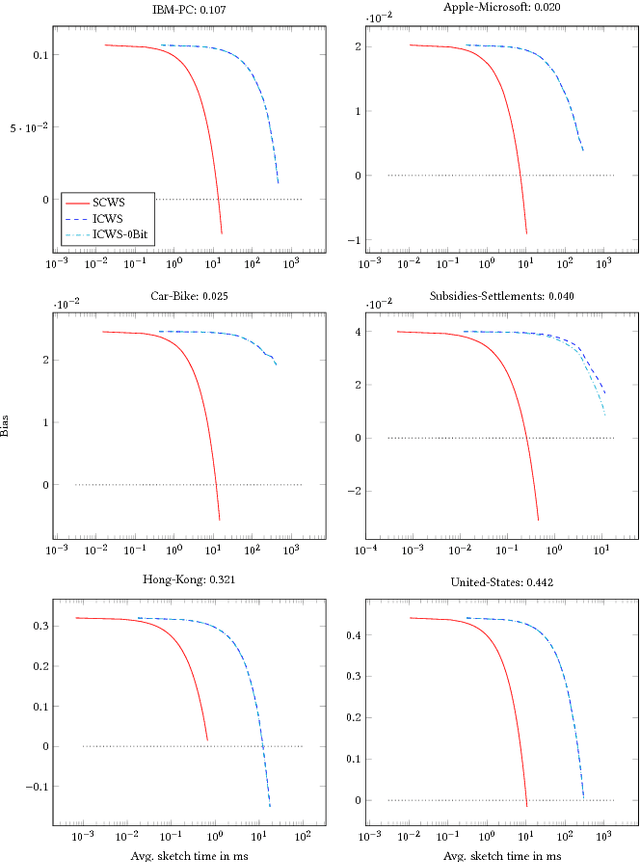
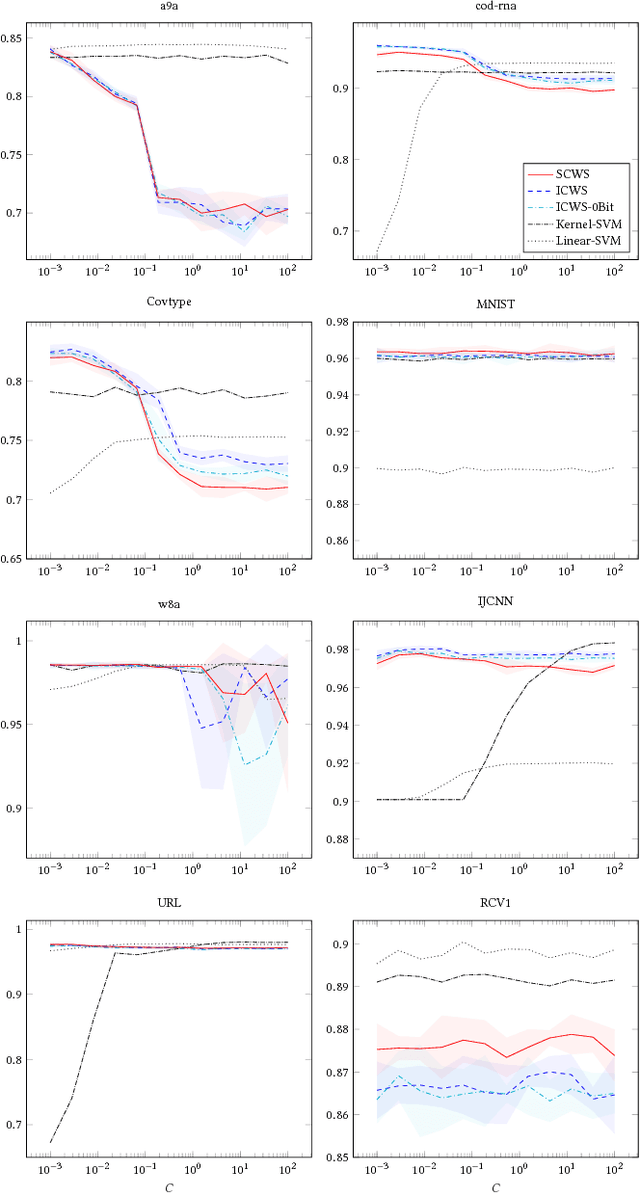
The Min-Hashing approach to sketching has become an important tool in data analysis, information retrial, and classification. To apply it to real-valued datasets, the ICWS algorithm has become a seminal approach that is widely used, and provides state-of-the-art performance for this problem space. However, ICWS suffers a computational burden as the sketch size K increases. We develop a new Simplified approach to the ICWS algorithm, that enables us to obtain over 20x speedups compared to the standard algorithm. The veracity of our approach is demonstrated empirically on multiple datasets and scenarios, showing that our new Simplified CWS obtains the same quality of results while being an order of magnitude faster.
Static Malware Detection & Subterfuge: Quantifying the Robustness of Machine Learning and Current Anti-Virus
Jun 12, 2018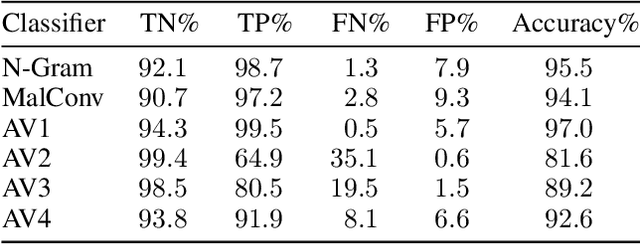
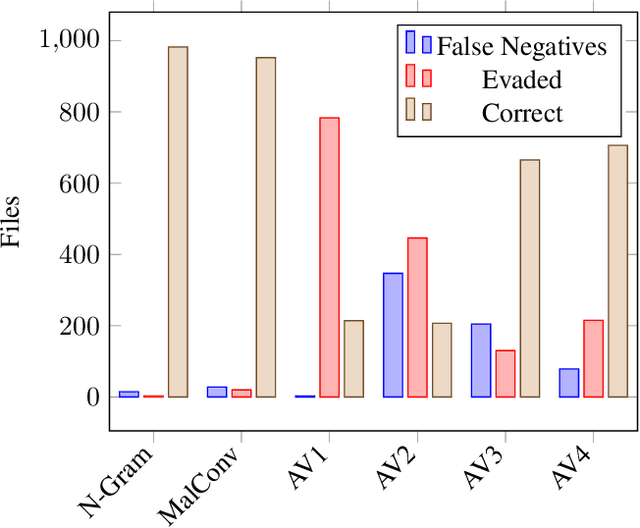
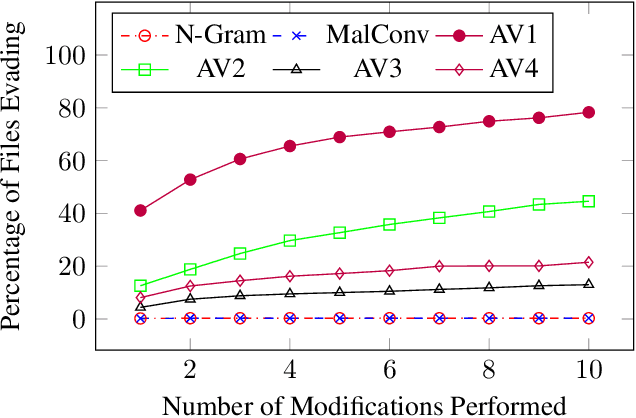
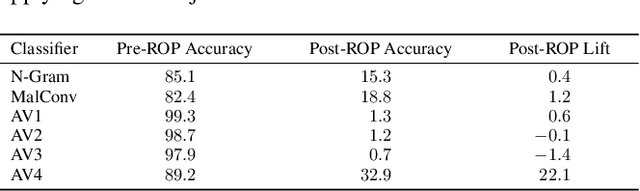
As machine-learning (ML) based systems for malware detection become more prevalent, it becomes necessary to quantify the benefits compared to the more traditional anti-virus (AV) systems widely used today. It is not practical to build an agreed upon test set to benchmark malware detection systems on pure classification performance. Instead we tackle the problem by creating a new testing methodology, where we evaluate the change in performance on a set of known benign & malicious files as adversarial modifications are performed. The change in performance combined with the evasion techniques then quantifies a system's robustness against that approach. Through these experiments we are able to show in a quantifiable way how purely ML based systems can be more robust than AV products at detecting malware that attempts evasion through modification, but may be slower to adapt in the face of significantly novel attacks.
Toward Metric Indexes for Incremental Insertion and Querying
Jan 12, 2018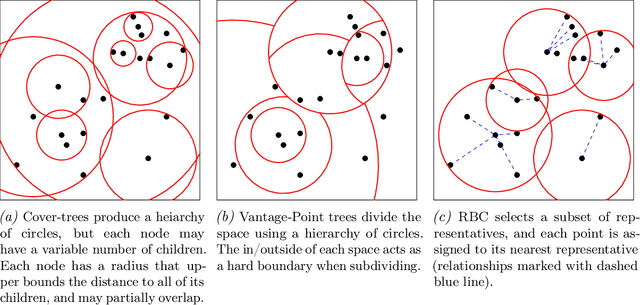
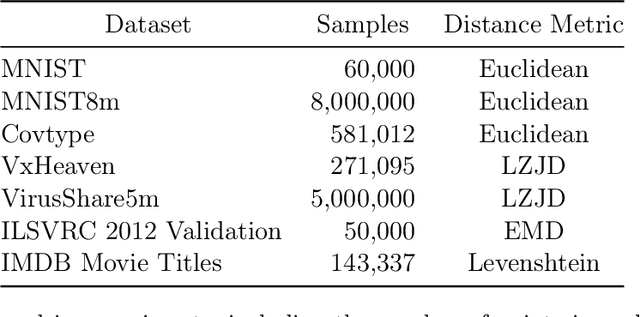
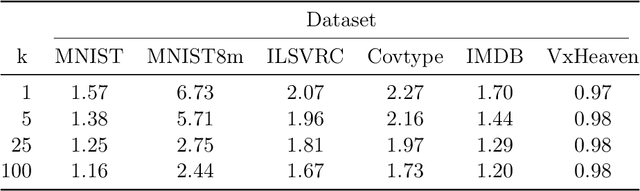
In this work we explore the use of metric index structures, which accelerate nearest neighbor queries, in the scenario where we need to interleave insertions and queries during deployment. This use-case is inspired by a real-life need in malware analysis triage, and is surprisingly understudied. Existing literature tends to either focus on only final query efficiency, often does not support incremental insertion, or does not support arbitrary distance metrics. We modify and improve three algorithms to support our scenario of incremental insertion and querying with arbitrary metrics, and evaluate them on multiple datasets and distance metrics while varying the value of $k$ for the desired number of nearest neighbors. In doing so we determine that our improved Vantage-Point tree of Minimum-Variance performs best for this scenario.
Learning the PE Header, Malware Detection with Minimal Domain Knowledge
Nov 11, 2017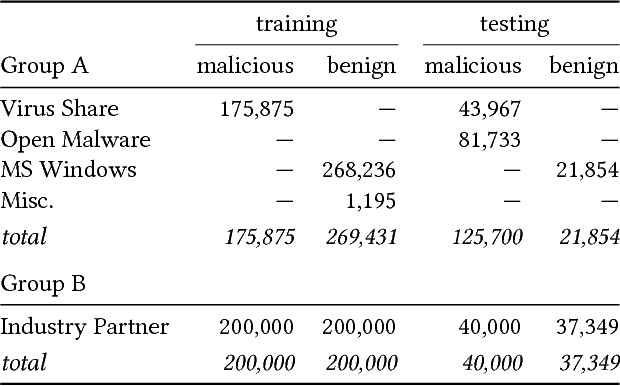
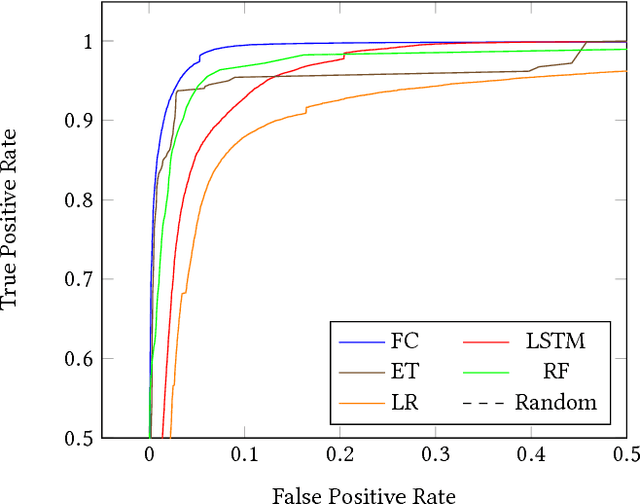

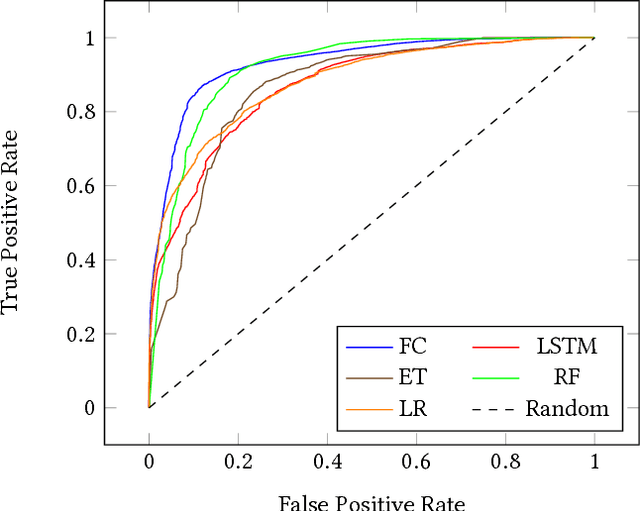
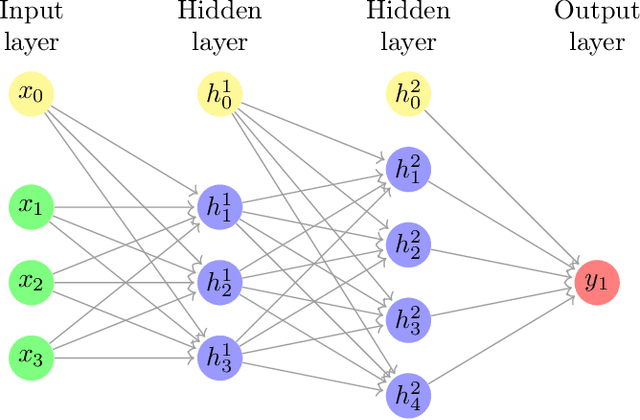
Many efforts have been made to use various forms of domain knowledge in malware detection. Currently there exist two common approaches to malware detection without domain knowledge, namely byte n-grams and strings. In this work we explore the feasibility of applying neural networks to malware detection and feature learning. We do this by restricting ourselves to a minimal amount of domain knowledge in order to extract a portion of the Portable Executable (PE) header. By doing this we show that neural networks can learn from raw bytes without explicit feature construction, and perform even better than a domain knowledge approach that parses the PE header into explicit features.
Malware Detection by Eating a Whole EXE
Oct 25, 2017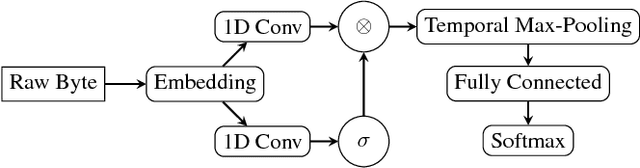


In this work we introduce malware detection from raw byte sequences as a fruitful research area to the larger machine learning community. Building a neural network for such a problem presents a number of interesting challenges that have not occurred in tasks such as image processing or NLP. In particular, we note that detection from raw bytes presents a sequence problem with over two million time steps and a problem where batch normalization appear to hinder the learning process. We present our initial work in building a solution to tackle this problem, which has linear complexity dependence on the sequence length, and allows for interpretable sub-regions of the binary to be identified. In doing so we will discuss the many challenges in building a neural network to process data at this scale, and the methods we used to work around them.