 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclostationarity Analysis as a Complement to Self-Supervised Representations for Speech Deepfake Detection
Mar 04, 2026Speech deepfake detection (SDD) is essential for maintaining trust in voice-driven technologies and digital media. Although recent SDD systems increasingly rely on self-supervised learning (SSL) representations that capture rich contextual information, complementary signal-driven acoustic features remain important for modeling fine-grained structural properties of speech. Most existing acoustic front ends are based on time-frequency representations, which do not fully exploit higher-order spectral dependencies inherent in speech signals. We introduce a cyclostationarity-inspired acoustic feature extraction framework for SDD based on spectral correlation density (SCD). The proposed features model periodic statistical structures in speech by capturing spectral correlations between frequency components. In particular, we propose temporally structured SCD features that characterize the evolution of spectral and cyclic-frequency components over time. The effectiveness and complementarity of the proposed features are evaluated using multiple countermeasure architectures, including convolutional neural networks, SSL-based embedding systems, and hybrid fusion models. Experiments on ASVspoof 2019 LA, ASVspoof 2021 DF, and ASVspoof 5 demonstrate that SCD-based features provide complementary discriminative information to SSL embeddings and conventional acoustic representations. In particular, fusion of SSL and SCD embeddings reduces the equal error rate on ASVspoof 2019 LA from $8.28\%$ to $0.98\%$, and yields consistent improvements on the challenging ASVspoof 5 dataset. The results highlight cyclostationary signal analysis as a theoretically grounded and effective front end for speech deepfake detection.
Joint Optimization of Speaker and Spoof Detectors for Spoofing-Robust Automatic Speaker Verification
Oct 02, 2025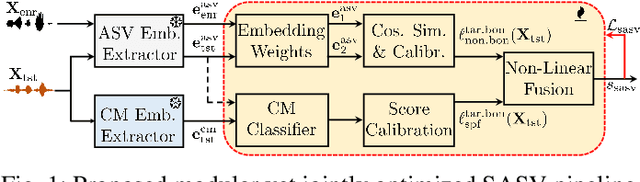
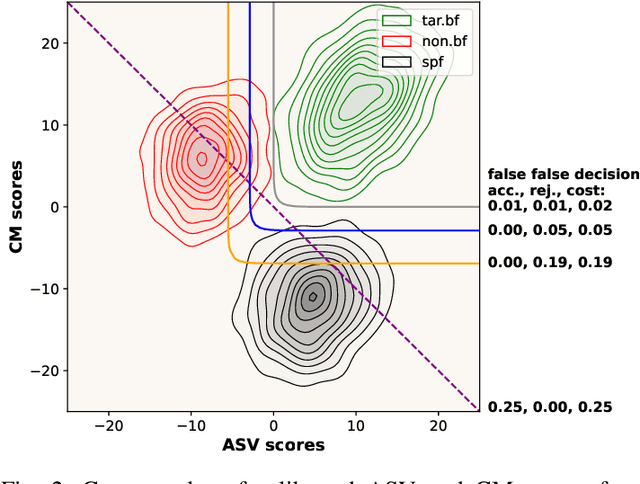
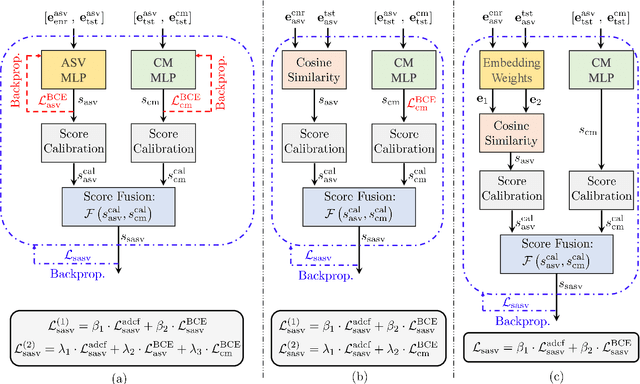
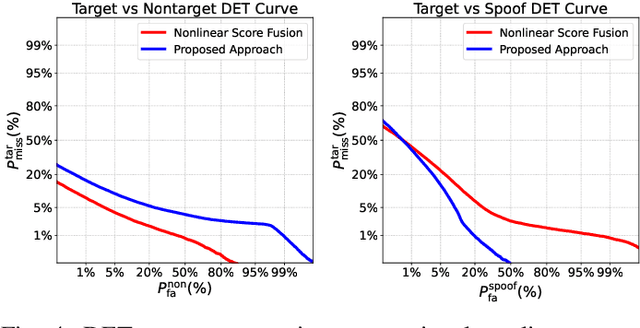
Spoofing-robust speaker verification (SASV) combines the tasks of speaker and spoof detection to authenticate speakers under adversarial settings. Many SASV systems rely on fusion of speaker and spoof cues at embedding, score or decision levels, based on independently trained subsystems. In this study, we respect similar modularity of the two subsystems, by integrating their outputs using trainable back-end classifiers. In particular, we explore various approaches for directly optimizing the back-end for the recently-proposed SASV performance metric (a-DCF) as a training objective. Our experiments on the ASVspoof 5 dataset demonstrate two important findings: (i) nonlinear score fusion consistently improves a-DCF over linear fusion, and (ii) the combination of weighted cosine scoring for speaker detection with SSL-AASIST for spoof detection achieves state-of-the-art performance, reducing min a-DCF to 0.196 and SPF-EER to 7.6%. These contributions highlight the importance of modular design, calibrated integration, and task-aligned optimization for advancing robust and interpretable SASV systems.
Spoofing-Robust Speaker Verification Using Parallel Embedding Fusion: BTU Speech Group's Approach for ASVspoof5 Challenge
Aug 28, 2024



This paper introduces the parallel network-based spoofing-aware speaker verification (SASV) system developed by BTU Speech Group for the ASVspoof5 Challenge. The SASV system integrates ASV and CM systems to enhance security against spoofing attacks. Our approach employs score and embedding fusion from ASV models (ECAPA-TDNN, WavLM) and CM models (AASIST). The fused embeddings are processed using a simple DNN structure, optimizing model performance with a combination of recently proposed a-DCF and BCE losses. We introduce a novel parallel network structure where two identical DNNs, fed with different inputs, independently process embeddings and produce SASV scores. The final SASV probability is derived by averaging these scores, enhancing robustness and accuracy. Experimental results demonstrate that the proposed parallel DNN structure outperforms traditional single DNN methods, offering a more reliable and secure speaker verification system against spoofing attacks.
Optimizing a-DCF for Spoofing-Robust Speaker Verification
Jul 04, 2024



Automatic speaker verification (ASV) systems are vulnerable to spoofing attacks such as text-to-speech. In this study, we propose a novel spoofing-robust ASV back-end classifier, optimized directly for the recently introduced, architecture-agnostic detection cost function (a-DCF). We combine a-DCF and binary cross-entropy (BCE) losses to optimize the network weights, combined by a novel, straightforward detection threshold optimization technique. Experiments on the ASVspoof2019 database demonstrate considerable improvement over the baseline optimized using BCE only (from minimum a-DCF of 0.1445 to 0.1254), representing 13% relative improvement. These initial promising results demonstrate that it is possible to adjust an ASV system to find appropriate balance across the contradicting aims of user convenience and security against adversaries.