 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Sample Deep Learning
Jul 21, 2023Deep Learning (DL) , a variant of the neural network algorithms originally proposed in the 1980s, has made surprising progress in Artificial Intelligence (AI), ranging from language translation, protein folding, autonomous cars, and more recently human-like language models (CHATbots), all that seemed intractable until very recently. Despite the growing use of Deep Learning (DL) networks, little is actually understood about the learning mechanisms and representations that makes these networks effective across such a diverse range of applications. Part of the answer must be the huge scale of the architecture and of course the large scale of the data, since not much has changed since 1987. But the nature of deep learned representations remain largely unknown. Unfortunately training sets with millions or billions of tokens have unknown combinatorics and Networks with millions or billions of hidden units cannot easily be visualized and their mechanisms cannot be easily revealed. In this paper, we explore these questions with a large (1.24M weights; VGG) DL in a novel high density sample task (5 unique tokens with at minimum 500 exemplars per token) which allows us to more carefully follow the emergence of category structure and feature construction. We use various visualization methods for following the emergence of the classification and the development of the coupling of feature detectors and structures that provide a type of graphical bootstrapping, From these results we harvest some basic observations of the learning dynamics of DL and propose a new theory of complex feature construction based on our results.
A Study of Actor and Action Semantic Retention in Video Supervoxel Segmentation
Nov 13, 2013


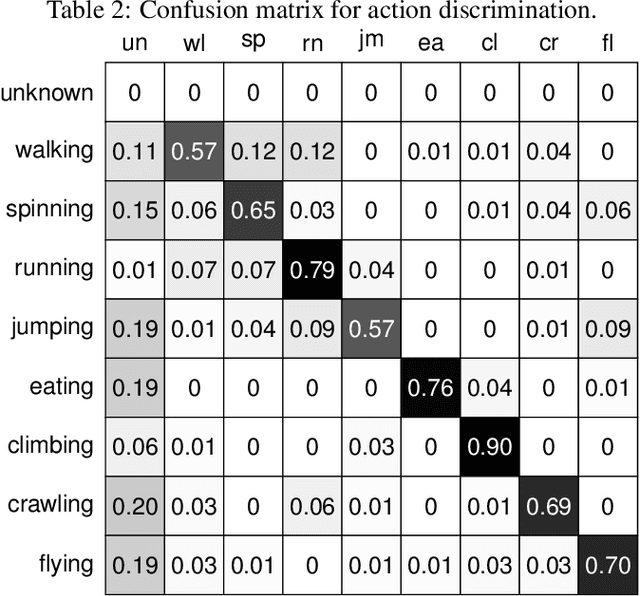
Existing methods in the semantic computer vision community seem unable to deal with the explosion and richness of modern, open-source and social video content. Although sophisticated methods such as object detection or bag-of-words models have been well studied, they typically operate on low level features and ultimately suffer from either scalability issues or a lack of semantic meaning. On the other hand, video supervoxel segmentation has recently been established and applied to large scale data processing, which potentially serves as an intermediate representation to high level video semantic extraction. The supervoxels are rich decompositions of the video content: they capture object shape and motion well. However, it is not yet known if the supervoxel segmentation retains the semantics of the underlying video content. In this paper, we conduct a systematic study of how well the actor and action semantics are retained in video supervoxel segmentation. Our study has human observers watching supervoxel segmentation videos and trying to discriminate both actor (human or animal) and action (one of eight everyday actions). We gather and analyze a large set of 640 human perceptions over 96 videos in 3 different supervoxel scales. Furthermore, we conduct machine recognition experiments on a feature defined on supervoxel segmentation, called supervoxel shape context, which is inspired by the higher order processes in human perception. Our ultimate findings suggest that a significant amount of semantics have been well retained in the video supervoxel segmentation and can be used for further video analysis.