 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Interpretable Models with Causal Guarantees
Jan 24, 2019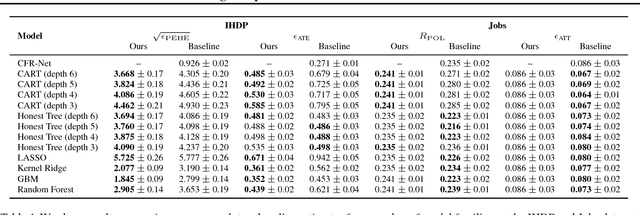
Machine learning has shown much promise in helping improve the quality of medical, legal, and economic decision-making. In these applications, machine learning models must satisfy two important criteria: (i) they must be causal, since the goal is typically to predict individual treatment effects, and (ii) they must be interpretable, so that human decision makers can validate and trust the model predictions. There has recently been much progress along each direction independently, yet the state-of-the-art approaches are fundamentally incompatible. We propose a framework for learning causal interpretable models---from observational data---that can be used to predict individual treatment effects. Our framework can be used with any algorithm for learning interpretable models. Furthermore, we prove an error bound on the treatment effects predicted by our model. Finally, in an experiment on real-world data, we show that the models trained using our framework significantly outperform a number of baselines.
Interpreting Blackbox Models via Model Extraction
May 22, 2018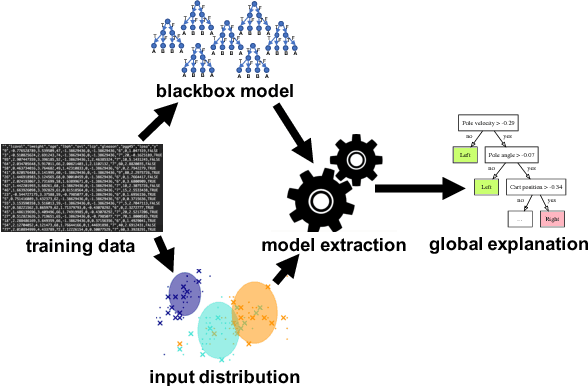

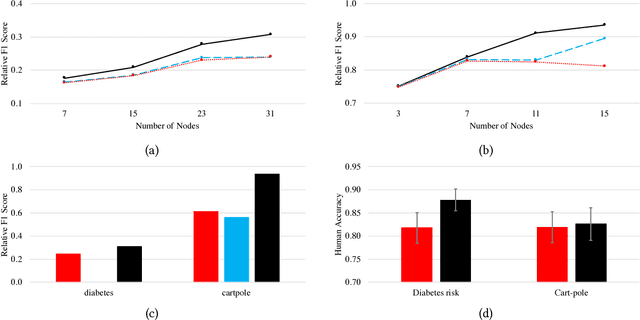
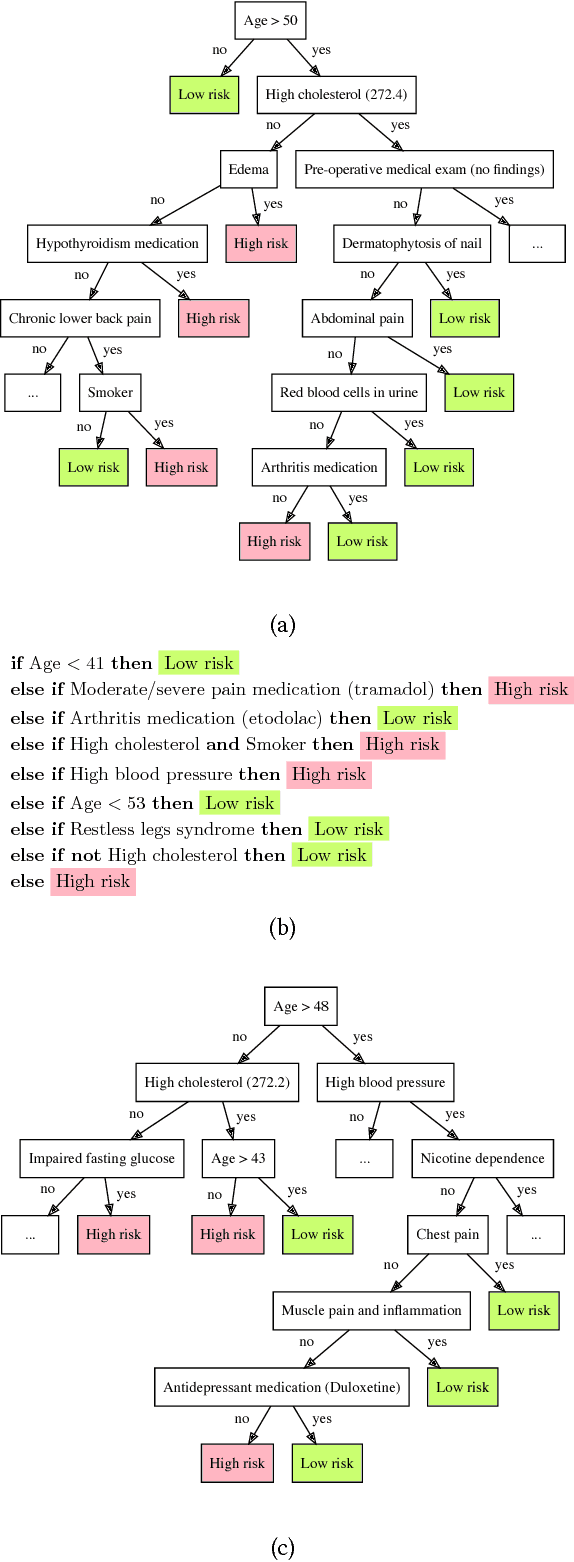
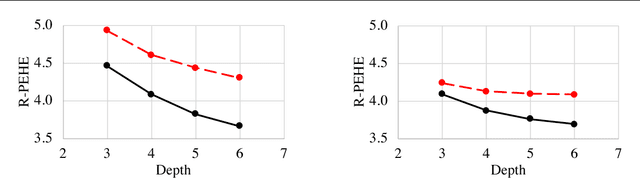
Interpretability has become incredibly important as machine learning is increasingly used to inform consequential decisions. We propose to construct global explanations of complex, blackbox models in the form of a decision tree approximating the original model---as long as the decision tree is a good approximation, then it mirrors the computation performed by the blackbox model. We devise a novel algorithm for extracting decision tree explanations that actively samples new training points to avoid overfitting. We evaluate our algorithm on a random forest to predict diabetes risk and a learned controller for cart-pole. Compared to several baselines, our decision trees are both substantially more accurate and equally or more interpretable based on a user study. Finally, we describe several insights provided by our interpretations, including a causal issue validated by a physician.
Interpretability via Model Extraction
Mar 13, 2018
The ability to interpret machine learning models has become increasingly important now that machine learning is used to inform consequential decisions. We propose an approach called model extraction for interpreting complex, blackbox models. Our approach approximates the complex model using a much more interpretable model; as long as the approximation quality is good, then statistical properties of the complex model are reflected in the interpretable model. We show how model extraction can be used to understand and debug random forests and neural nets trained on several datasets from the UCI Machine Learning Repository, as well as control policies learned for several classical reinforcement learning problems.