 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Servoing for Robotic On-Orbit Servicing: A Survey
Sep 03, 2024



On-orbit servicing (OOS) activities will power the next big step for sustainable exploration and commercialization of space. Developing robotic capabilities for autonomous OOS operations is a priority for the space industry. Visual Servoing (VS) enables robots to achieve the precise manoeuvres needed for critical OOS missions by utilizing visual information for motion control. This article presents an overview of existing VS approaches for autonomous OOS operations with space manipulator systems (SMS). We divide the approaches according to their contribution to the typical phases of a robotic OOS mission: a) Recognition, b) Approach, and c) Contact. We also present a discussion on the reviewed VS approaches, identifying current trends. Finally, we highlight the challenges and areas for future research on VS techniques for robotic OOS.
Object-centric Reconstruction and Tracking of Dynamic Unknown Objects using 3D Gaussian Splatting
May 30, 2024Generalizable perception is one of the pillars of high-level autonomy in space robotics. Estimating the structure and motion of unknown objects in dynamic environments is fundamental for such autonomous systems. Traditionally, the solutions have relied on prior knowledge of target objects, multiple disparate representations, or low-fidelity outputs unsuitable for robotic operations. This work proposes a novel approach to incrementally reconstruct and track a dynamic unknown object using a unified representation -- a set of 3D Gaussian blobs that describe its geometry and appearance. The differentiable 3D Gaussian Splatting framework is adapted to a dynamic object-centric setting. The input to the pipeline is a sequential set of RGB-D images. 3D reconstruction and 6-DoF pose tracking tasks are tackled using first-order gradient-based optimization. The formulation is simple, requires no pre-training, assumes no prior knowledge of the object or its motion, and is suitable for online applications. The proposed approach is validated on a dataset of 10 unknown spacecraft of diverse geometry and texture under arbitrary relative motion. The experiments demonstrate successful 3D reconstruction and accurate 6-DoF tracking of the target object in proximity operations over a short to medium duration. The causes of tracking drift are discussed and potential solutions are outlined.
Leveraging Procedural Generation for Learning Autonomous Peg-in-Hole Assembly in Space
May 02, 2024The ability to autonomously assemble structures is crucial for the development of future space infrastructure. However, the unpredictable conditions of space pose significant challenges for robotic systems, necessitating the development of advanced learning techniques to enable autonomous assembly. In this study, we present a novel approach for learning autonomous peg-in-hole assembly in the context of space robotics. Our focus is on enhancing the generalization and adaptability of autonomous systems through deep reinforcement learning. By integrating procedural generation and domain randomization, we train agents in a highly parallelized simulation environment across a spectrum of diverse scenarios with the aim of acquiring a robust policy. The proposed approach is evaluated using three distinct reinforcement learning algorithms to investigate the trade-offs among various paradigms. We demonstrate the adaptability of our agents to novel scenarios and assembly sequences while emphasizing the potential of leveraging advanced simulation techniques for robot learning in space. Our findings set the stage for future advancements in intelligent robotic systems capable of supporting ambitious space missions and infrastructure development beyond Earth.
GraspLDM: Generative 6-DoF Grasp Synthesis using Latent Diffusion Models
Dec 18, 2023



Vision-based grasping of unknown objects in unstructured environments is a key challenge for autonomous robotic manipulation. A practical grasp synthesis system is required to generate a diverse set of 6-DoF grasps from which a task-relevant grasp can be executed. Although generative models are suitable for learning such complex data distributions, existing models have limitations in grasp quality, long training times, and a lack of flexibility for task-specific generation. In this work, we present GraspLDM- a modular generative framework for 6-DoF grasp synthesis that uses diffusion models as priors in the latent space of a VAE. GraspLDM learns a generative model of object-centric $SE(3)$ grasp poses conditioned on point clouds. GraspLDM's architecture enables us to train task-specific models efficiently by only re-training a small de-noising network in the low-dimensional latent space, as opposed to existing models that need expensive re-training. Our framework provides robust and scalable models on both full and single-view point clouds. GraspLDM models trained with simulation data transfer well to the real world and provide an 80\% success rate for 80 grasp attempts of diverse test objects, improving over existing generative models. We make our implementation available at https://github.com/kuldeepbrd1/graspldm .
Evaluation of Position and Velocity Based Forward Dynamics Compliance Control (FDCC) for Robotic Interactions in Position Controlled Robots
Oct 24, 2022



In robotic manipulation, end-effector compliance is an essential precondition for performing contact-rich tasks, such as machining, assembly, and human-robot interaction. Most robotic arms are position-controlled stiff systems at a hardware level. Thus, adding compliance becomes essential. Compliance in those systems has been recently achieved using Forward dynamics compliance control (FDCC), which, owing to its virtual forward dynamics model, can be implemented on both position and velocity-controlled robots. This paper evaluates the choice of control interface (and hence the control domain), which, although considered trivial, is essential due to differences in their characteristics. In some cases, the choice is restricted to the available hardware interface. However, given the option to choose, the velocity-based control interface makes a better candidate for compliance control because of smoother compliant behaviour, reduced interaction forces, and work done. To prove these points, in this paper FDCC is evaluated on the UR10e six-DOF manipulator with velocity and position control modes. The evaluation is based on force-control benchmarking metrics using 3D-printed artefacts. Real experiments favour the choice of velocity control over position control.
Emulating On-Orbit Interactions Using Forward Dynamics Based Cartesian Motion
Sep 30, 2022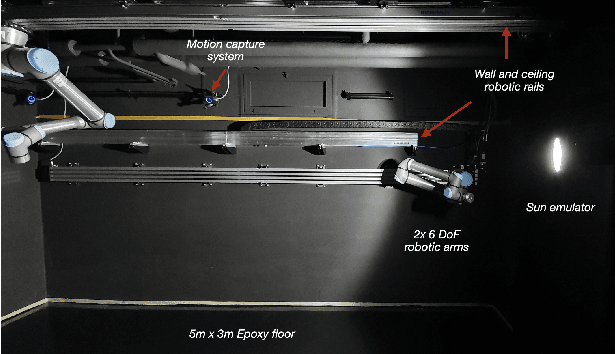
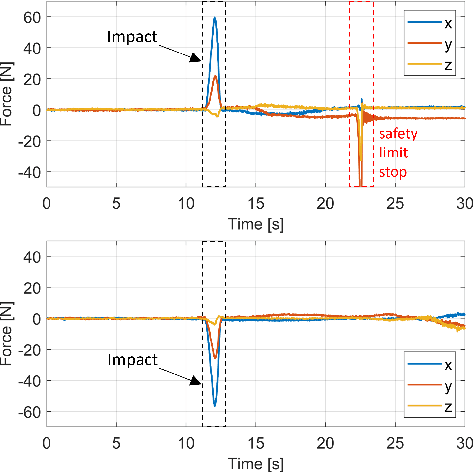
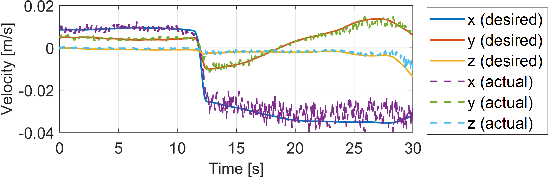
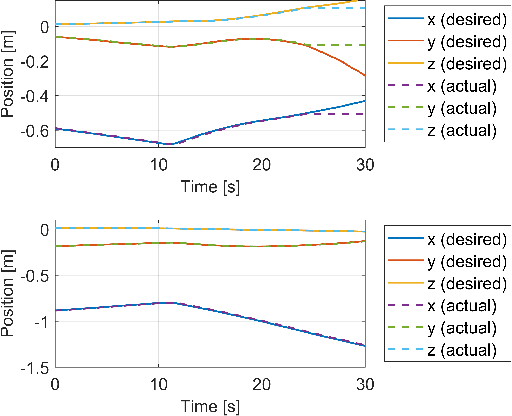
The paper presents a novel Hardware-In-the-Loop (HIL) emulation framework of on-orbit interactions using on-ground robotic manipulators. It combines Virtual Forward Dynamic Model (VFDM) for Cartesian motion control of robotic manipulators with an Orbital Dynamics Simulator (ODS) based on the Clohessy Wiltshire (CW) Model. VFDM-based Inverse Kinematics (IK) solver is known to have better motion tracking, path accuracy, and solver convergency than traditional IK solvers. Therefore it provides a stable Cartesian motion for manipulator-based HIL on-orbit emulations. The framework is tested on a ROS-based robotics testbed to emulate two scenarios: free-floating satellite motion and free-floating interaction (collision). Mock-ups of two satellites are mounted at the robots' end-effectors. Forces acting on the mock-ups are measured through an in-built F/T sensor on each robotic arm. During the tests, the relative motion of the mock-ups is expressed with respect to a moving observer rotating at a fixed angular velocity in a circular orbit rather than their motion in the inertial frame. The ODS incorporates the force and torque values on the fly and delivers the corresponding satellite motions to the virtual forward dynamics model as online trajectories. Results are comparable to other free-floating HIL emulators. Fidelity between the simulated motion and robot-mounted mock-up motion is confirmed.
Lessons from a Space Lab -- An Image Acquisition Perspective
Aug 18, 2022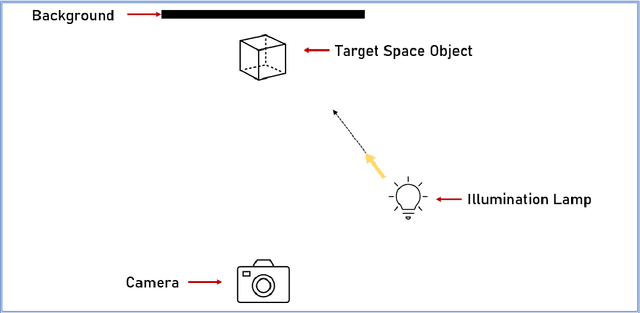
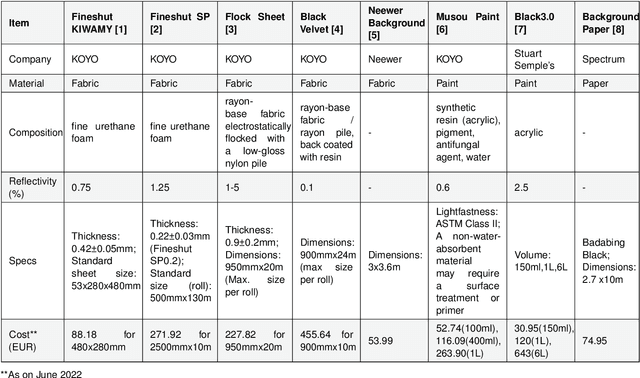
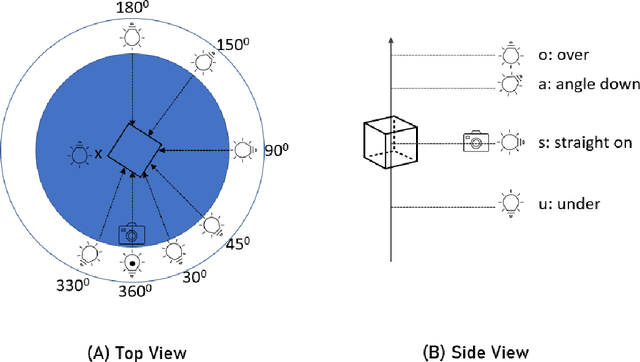
The use of Deep Learning (DL) algorithms has improved the performance of vision-based space applications in recent years. However, generating large amounts of annotated data for training these DL algorithms has proven challenging. While synthetically generated images can be used, the DL models trained on synthetic data are often susceptible to performance degradation, when tested in real-world environments. In this context, the Interdisciplinary Center of Security, Reliability and Trust (SnT) at the University of Luxembourg has developed the 'SnT Zero-G Lab', for training and validating vision-based space algorithms in conditions emulating real-world space environments. An important aspect of the SnT Zero-G Lab development was the equipment selection. From the lessons learned during the lab development, this article presents a systematic approach combining market survey and experimental analyses for equipment selection. In particular, the article focus on the image acquisition equipment in a space lab: background materials, cameras and illumination lamps. The results from the experiment analyses show that the market survey complimented by experimental analyses is required for effective equipment selection in a space lab development project.
Vision-Based Safety System for Barrierless Human-Robot Collaboration
Aug 03, 2022
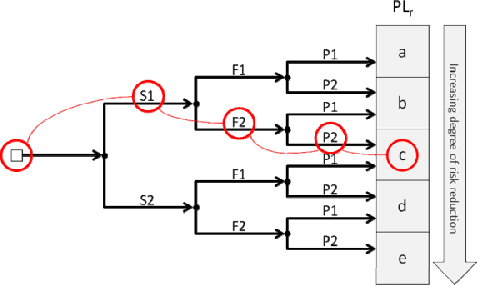
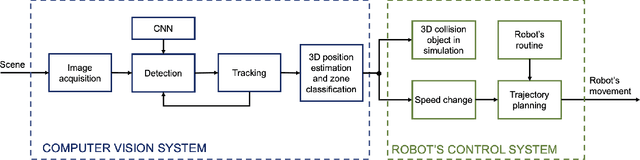
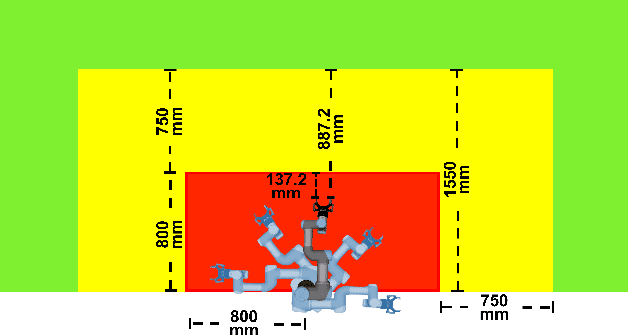
Human safety has always been the main priority when working near an industrial robot. With the rise of Human-Robot Collaborative environments, physical barriers to avoiding collisions have been disappearing, increasing the risk of accidents and the need for solutions that ensure a safe Human-Robot Collaboration. This paper proposes a safety system that implements Speed and Separation Monitoring (SSM) type of operation. For this, safety zones are defined in the robot's workspace following current standards for industrial collaborative robots. A deep learning-based computer vision system detects, tracks, and estimates the 3D position of operators close to the robot. The robot control system receives the operator's 3D position and generates 3D representations of them in a simulation environment. Depending on the zone where the closest operator was detected, the robot stops or changes its operating speed. Three different operation modes in which the human and robot interact are presented. Results show that the vision-based system can correctly detect and classify in which safety zone an operator is located and that the different proposed operation modes ensure that the robot's reaction and stop time are within the required time limits to guarantee safety.
Learning to Grasp on the Moon from 3D Octree Observations with Deep Reinforcement Learning
Aug 01, 2022
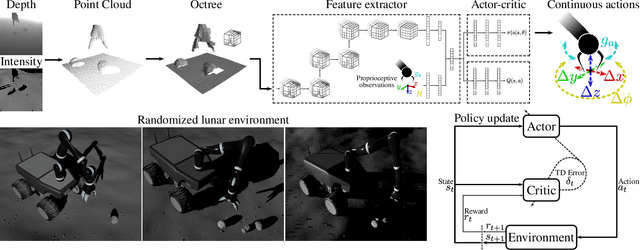
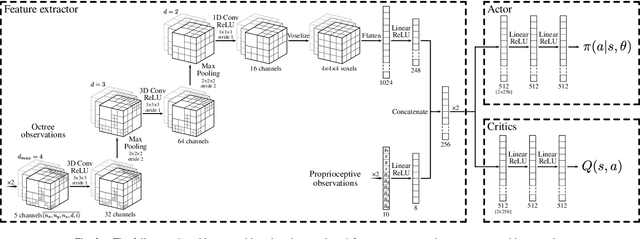
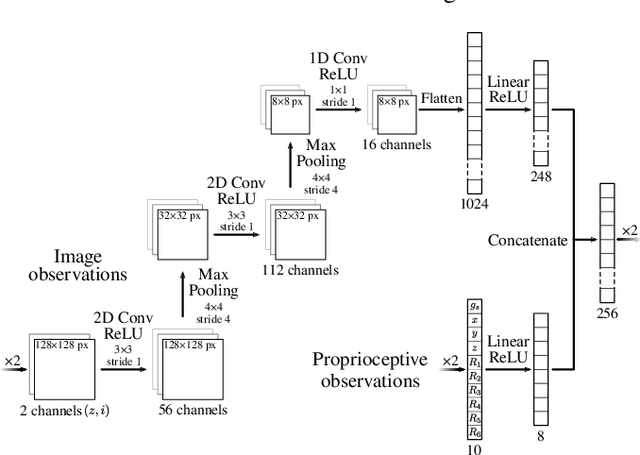
Extraterrestrial rovers with a general-purpose robotic arm have many potential applications in lunar and planetary exploration. Introducing autonomy into such systems is desirable for increasing the time that rovers can spend gathering scientific data and collecting samples. This work investigates the applicability of deep reinforcement learning for vision-based robotic grasping of objects on the Moon. A novel simulation environment with procedurally-generated datasets is created to train agents under challenging conditions in unstructured scenes with uneven terrain and harsh illumination. A model-free off-policy actor-critic algorithm is then employed for end-to-end learning of a policy that directly maps compact octree observations to continuous actions in Cartesian space. Experimental evaluation indicates that 3D data representations enable more effective learning of manipulation skills when compared to traditionally used image-based observations. Domain randomization improves the generalization of learned policies to novel scenes with previously unseen objects and different illumination conditions. To this end, we demonstrate zero-shot sim-to-real transfer by evaluating trained agents on a real robot in a Moon-analogue facility.