 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Reward: A Bounded Measure of Agent Environment Coupling
Mar 01, 2026Real-world reinforcement learning (RL) agents operate in closed-loop systems where actions shape future observations, making reliable deployment under distribution shifts a persistent challenge. Existing monitoring relies on reward or task metrics, capturing outcomes but missing early coupling failures. We introduce bipredictability (P) as the ratio of shared information in the observation, action, outcome loop to the total available information, a principled, real time measure of interaction effectiveness with provable bounds, comparable across tasks. An auxiliary monitor, the Information Digital Twin (IDT), computes P and its diagnostic components from the interaction stream. We evaluate SAC and PPO agents on MuJoCo HalfCheetah under eight agent, and environment-side perturbations across 168 trials. Under nominal operation, agents exhibit P = 0.33 plus minus 0.02, below the classical bound of 0.5, revealing an informational cost of action selection. The IDT detects 89.3% of perturbations versus 44.0% for reward based monitoring, with 4.4x lower median latency. Bipredictability enables early detection of interaction degradation before performance drops and provides a prerequisite signal for closed loop self regulation in deployed RL systems.
A Mathematical Theory of Agency and Intelligence
Feb 26, 2026To operate reliably under changing conditions, complex systems require feedback on how effectively they use resources, not just whether objectives are met. Current AI systems process vast information to produce sophisticated predictions, yet predictions can appear successful while the underlying interaction with the environment degrades. What is missing is a principled measure of how much of the total information a system deploys is actually shared between its observations, actions, and outcomes. We prove this shared fraction, which we term bipredictability, P, is intrinsic to any interaction, derivable from first principles, and strictly bounded: P can reach unity in quantum systems, P equal to, or smaller than 0.5 in classical systems, and lower once agency (action selection) is introduced. We confirm these bounds in a physical system (double pendulum), reinforcement learning agents, and multi turn LLM conversations. These results distinguish agency from intelligence: agency is the capacity to act on predictions, whereas intelligence additionally requires learning from interaction, self-monitoring of its learning effectiveness, and adapting the scope of observations, actions, and outcomes to restore effective learning. By this definition, current AI systems achieve agency but not intelligence. Inspired by thalamocortical regulation in biological systems, we demonstrate a feedback architecture that monitors P in real time, establishing a prerequisite for adaptive, resilient AI.
Student/Teacher Advising through Reward Augmentation
Feb 07, 2020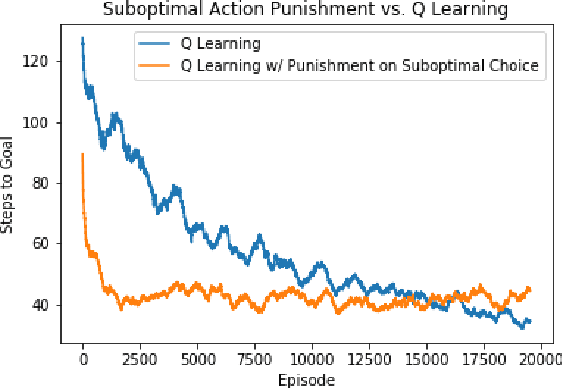
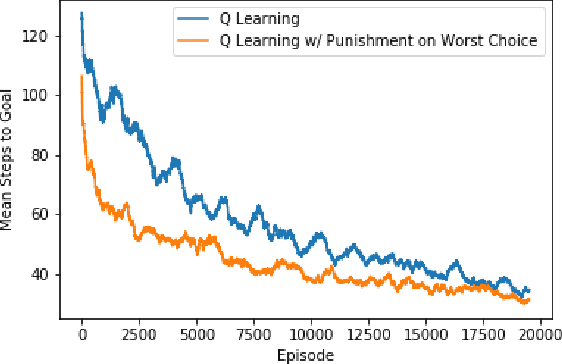
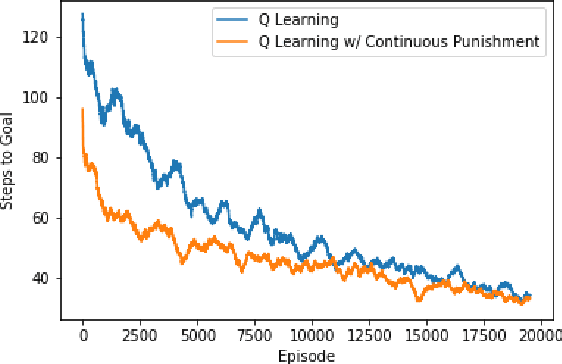
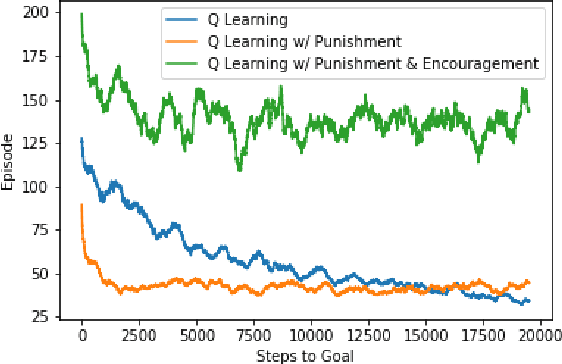
Transfer learning is an important new subfield of multiagent reinforcement learning that aims to help an agent learn about a problem by using knowledge that it has gained solving another problem, or by using knowledge that is communicated to it by an agent who already knows the problem. This is useful when one wishes to change the architecture or learning algorithm of an agent (so that the new knowledge need not be built "from scratch"), when new agents are frequently introduced to the environment with no knowledge, or when an agent must adapt to similar but different problems. Great progress has been made in the agent-to-agent case using the Teacher/Student framework proposed by (Torrey and Taylor 2013). However, that approach requires that learning from a teacher be treated differently from learning in every other reinforcement learning context. In this paper, I propose a method which allows the teacher/student framework to be applied in a way that fits directly and naturally into the more general reinforcement learning framework by integrating the teacher feedback into the reward signal received by the learning agent. I show that this approach can significantly improve the rate of learning for an agent playing a one-player stochastic game; I give examples of potential pitfalls of the approach; and I propose further areas of research building on this framework.