 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuye Xu
NICE-Beam: Neural Integrated Covariance Estimators for Time-Varying Beamformers
Dec 08, 2021

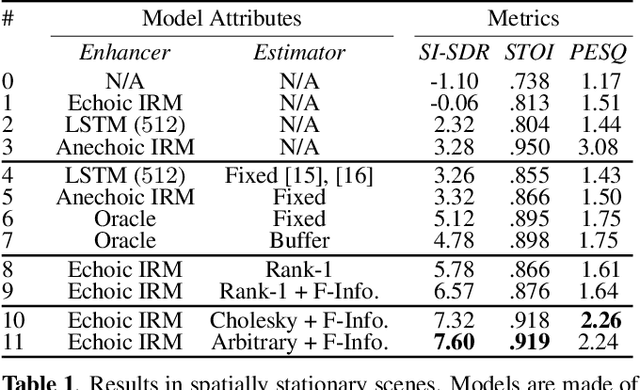

Estimating a time-varying spatial covariance matrix for a beamforming algorithm is a challenging task, especially for wearable devices, as the algorithm must compensate for time-varying signal statistics due to rapid pose-changes. In this paper, we propose Neural Integrated Covariance Estimators for Beamformers, NICE-Beam. NICE-Beam is a general technique for learning how to estimate time-varying spatial covariance matrices, which we apply to joint speech enhancement and dereverberation. It is based on training a neural network module to non-linearly track and leverage scene information across time. We integrate our solution into a beamforming pipeline, which enables simple training, faster than real-time inference, and a variety of test-time adaptation options. We evaluate the proposed model against a suite of baselines in scenes with both stationary and moving microphones. Our results show that the proposed method can outperform a hand-tuned estimator, despite the hand-tuned estimator using oracle source separation knowledge.
Multichannel Speech Enhancement without Beamforming
Oct 25, 2021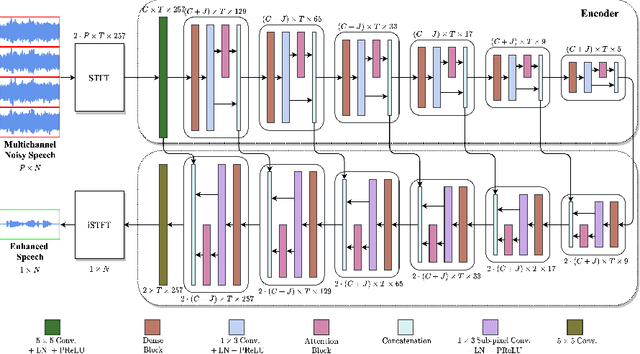
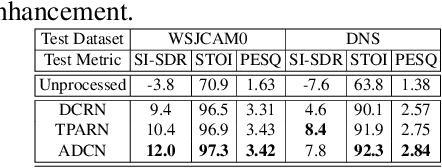
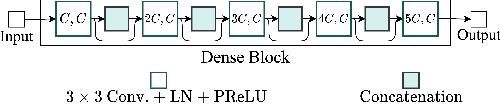
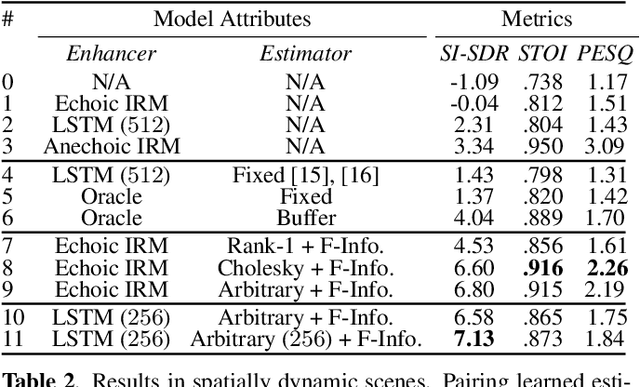
Deep neural networks are often coupled with traditional spatial filters, such as MVDR beamformers for effectively exploiting spatial information. Even though single-stage end-to-end supervised models can obtain impressive enhancement, combining them with a beamformer and a DNN-based post-filter in a multistage processing provides additional improvements. In this work, we propose a two-stage strategy for multi-channel speech enhancement that does not need a beamformer for additional performance. First, we propose a novel attentive dense convolutional network (ADCN) for predicting real and imaginary parts of complex spectrogram. ADCN obtains state-of-the-art results among single-stage models. Next, we use ADCN in the proposed strategy with a recently proposed triple-path attentive recurrent network (TPARN) for predicting waveform samples. The proposed strategy uses two insights; first, using different approaches in two stages; and second, using a stronger model in the first stage. We illustrate the efficacy of our strategy by evaluating multiple models in a two-stage approach with and without beamformer.
TADRN: Triple-Attentive Dual-Recurrent Network for Ad-hoc Array Multichannel Speech Enhancement
Oct 22, 2021


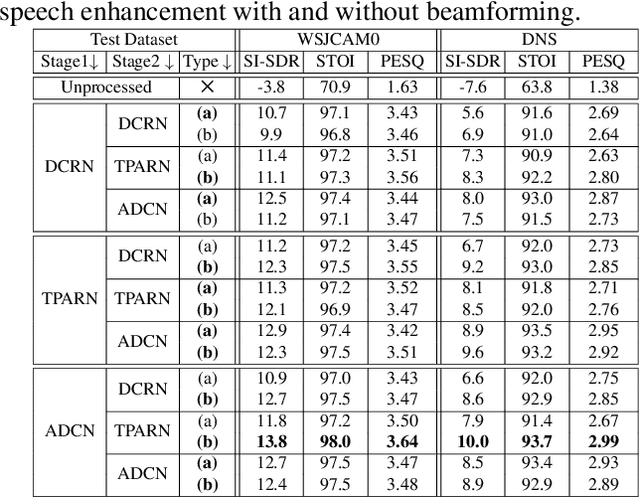
Deep neural networks (DNNs) have been successfully used for multichannel speech enhancement in fixed array geometries. However, challenges remain for ad-hoc arrays with unknown microphone placements. We propose a deep neural network based approach for ad-hoc array processing: Triple-Attentive Dual-Recurrent Network (TADRN). TADRN uses self-attention across channels for learning spatial information and a dual-path attentive recurrent network (ARN) for temporal modeling. Temporal modeling is done independently for all channels by dividing a signal into smaller chunks and using an intra-chunk ARN for local modeling and an inter-chunk ARN for global modeling. Consequently, TADRN uses triple-path attention: inter-channel, intra-chunk, and inter-chunk, and dual-path recurrence: intra-chunk and inter-chunk. Experimental results show excellent performance of TADRN. We demonstrate that TADRN improves speech enhancement by leveraging additional randomly placed microphones, even at locations far from the target source. Additionally, large improvements in objective scores are observed when poorly placed microphones in the scene are complemented with more effective microphone positions, such as those closer to a target source.
TPARN: Triple-path Attentive Recurrent Network for Time-domain Multichannel Speech Enhancement
Oct 20, 2021
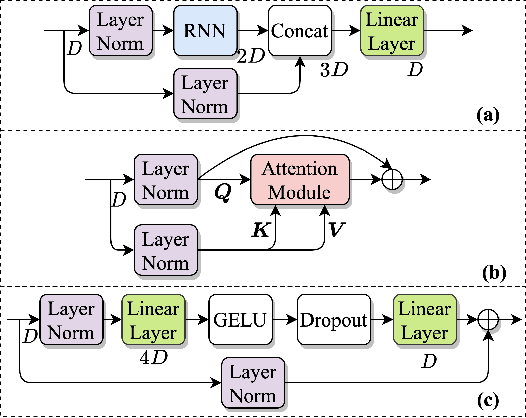
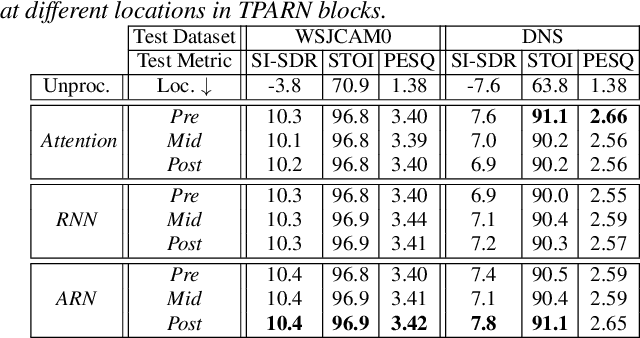
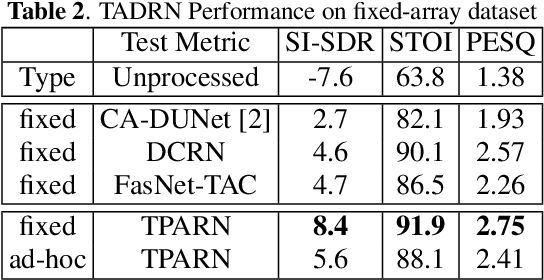
In this work, we propose a new model called triple-path attentive recurrent network (TPARN) for multichannel speech enhancement in the time domain. TPARN extends a single-channel dual-path network to a multichannel network by adding a third path along the spatial dimension. First, TPARN processes speech signals from all channels independently using a dual-path attentive recurrent network (ARN), which is a recurrent neural network (RNN) augmented with self-attention. Next, an ARN is introduced along the spatial dimension for spatial context aggregation. TPARN is designed as a multiple-input and multiple-output architecture to enhance all input channels simultaneously. Experimental results demonstrate the superiority of TPARN over existing state-of-the-art approaches.
Continual self-training with bootstrapped remixing for speech enhancement
Oct 19, 2021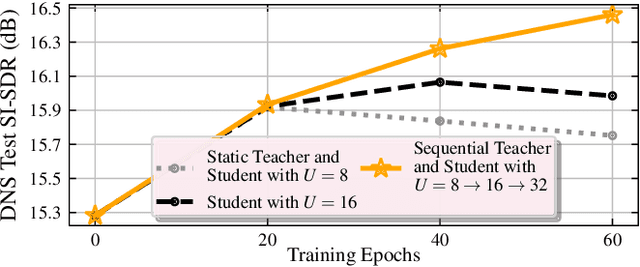
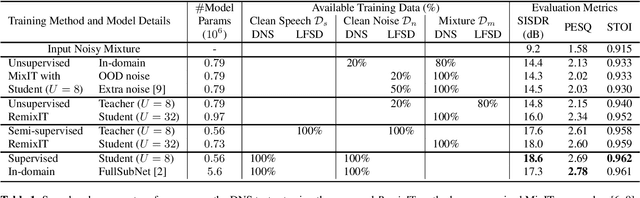
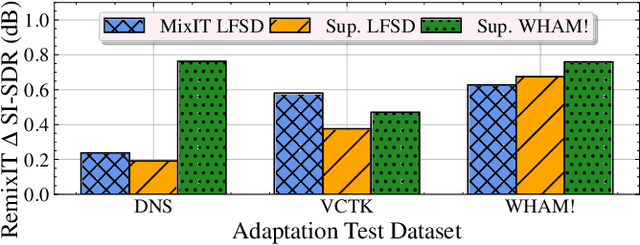
We propose RemixIT, a simple and novel self-supervised training method for speech enhancement. The proposed method is based on a continuously self-training scheme that overcomes limitations from previous studies including assumptions for the in-domain noise distribution and having access to clean target signals. Specifically, a separation teacher model is pre-trained on an out-of-domain dataset and is used to infer estimated target signals for a batch of in-domain mixtures. Next, we bootstrap the mixing process by generating artificial mixtures using permuted estimated clean and noise signals. Finally, the student model is trained using the permuted estimated sources as targets while we periodically update teacher's weights using the latest student model. Our experiments show that RemixIT outperforms several previous state-of-the-art self-supervised methods under multiple speech enhancement tasks. Additionally, RemixIT provides a seamless alternative for semi-supervised and unsupervised domain adaptation for speech enhancement tasks, while being general enough to be applied to any separation task and paired with any separation model.
Incorporating Real-world Noisy Speech in Neural-network-based Speech Enhancement Systems
Sep 21, 2021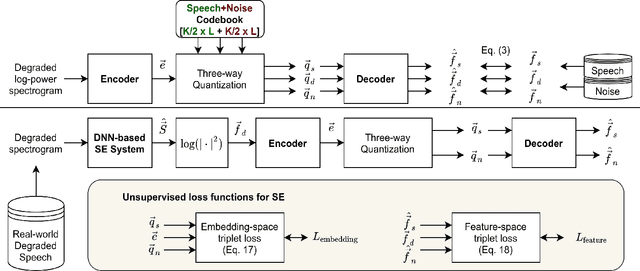

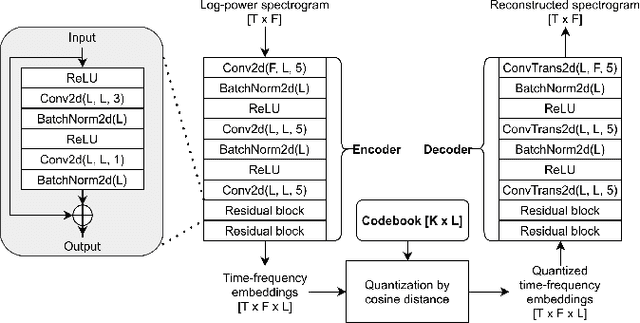
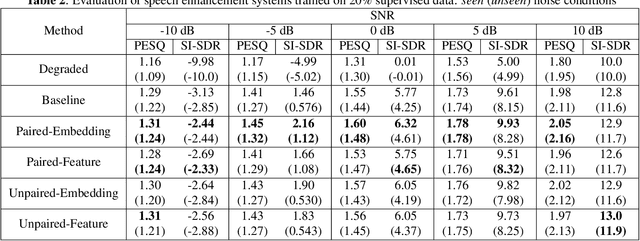
Supervised speech enhancement relies on parallel databases of degraded speech signals and their clean reference signals during training. This setting prohibits the use of real-world degraded speech data that may better represent the scenarios where such systems are used. In this paper, we explore methods that enable supervised speech enhancement systems to train on real-world degraded speech data. Specifically, we propose a semi-supervised approach for speech enhancement in which we first train a modified vector-quantized variational autoencoder that solves a source separation task. We then use this trained autoencoder to further train an enhancement network using real-world noisy speech data by computing a triplet-based unsupervised loss function. Experiments show promising results for incorporating real-world data in training speech enhancement systems.
NORESQA -- A Framework for Speech Quality Assessment using Non-Matching References
Sep 16, 2021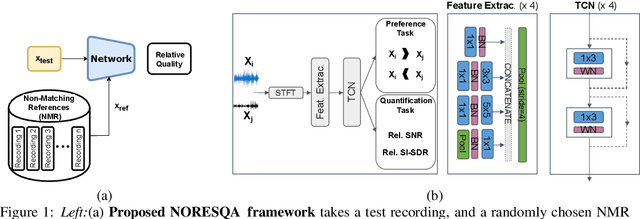
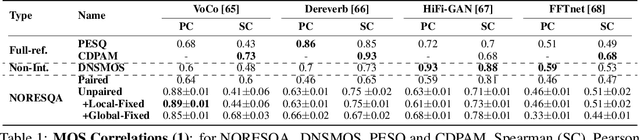
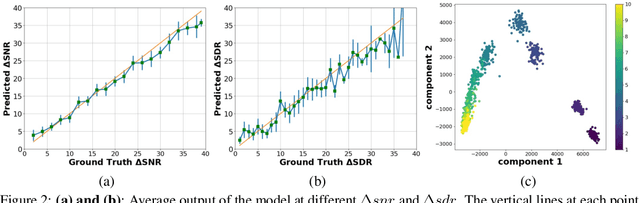
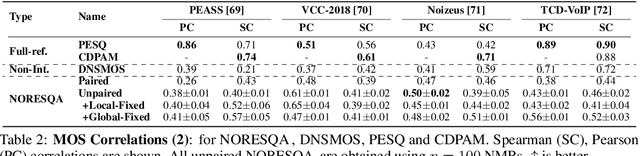
The perceptual task of speech quality assessment (SQA) is a challenging task for machines to do. Objective SQA methods that rely on the availability of the corresponding clean reference have been the primary go-to approaches for SQA. Clearly, these methods fail in real-world scenarios where the ground truth clean references are not available. In recent years, non-intrusive methods that train neural networks to predict ratings or scores have attracted much attention, but they suffer from several shortcomings such as lack of robustness, reliance on labeled data for training and so on. In this work, we propose a new direction for speech quality assessment. Inspired by human's innate ability to compare and assess the quality of speech signals even when they have non-matching contents, we propose a novel framework that predicts a subjective relative quality score for the given speech signal with respect to any provided reference without using any subjective data. We show that neural networks trained using our framework produce scores that correlate well with subjective mean opinion scores (MOS) and are also competitive to methods such as DNSMOS, which explicitly relies on MOS from humans for training networks. Moreover, our method also provides a natural way to embed quality-related information in neural networks, which we show is helpful for downstream tasks such as speech enhancement.
Online Self-Attentive Gated RNNs for Real-Time Speaker Separation
Jul 27, 2021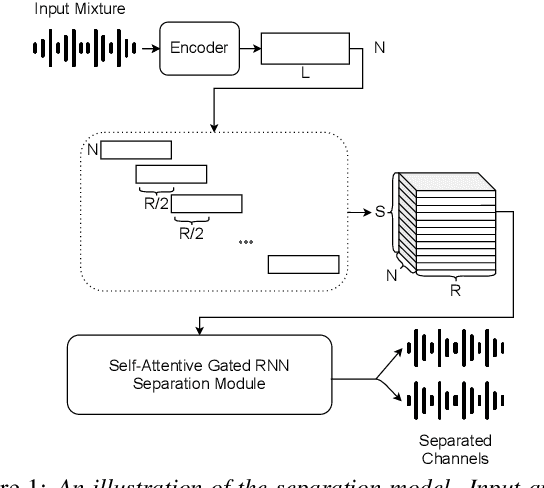
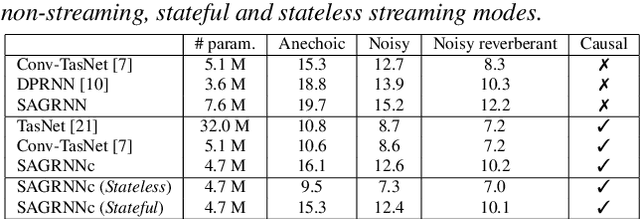
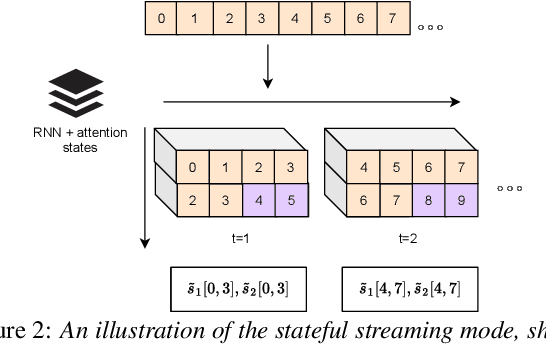

Deep neural networks have recently shown great success in the task of blind source separation, both under monaural and binaural settings. Although these methods were shown to produce high-quality separations, they were mainly applied under offline settings, in which the model has access to the full input signal while separating the signal. In this study, we convert a non-causal state-of-the-art separation model into a causal and real-time model and evaluate its performance under both online and offline settings. We compare the performance of the proposed model to several baseline methods under anechoic, noisy, and noisy-reverberant recording conditions while exploring both monaural and binaural inputs and outputs. Our findings shed light on the relative difference between causal and non-causal models when performing separation. Our stateful implementation for online separation leads to a minor drop in performance compared to the offline model; 0.8dB for monaural inputs and 0.3dB for binaural inputs while reaching a real-time factor of 0.65. Samples can be found under the following link: https://kwanum.github.io/sagrnnc-stream-results/.
DPLM: A Deep Perceptual Spatial-Audio Localization Metric
May 29, 2021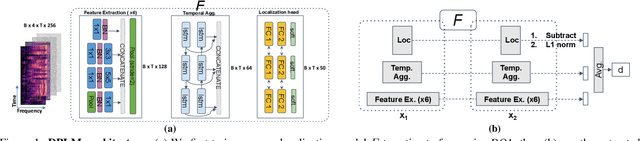
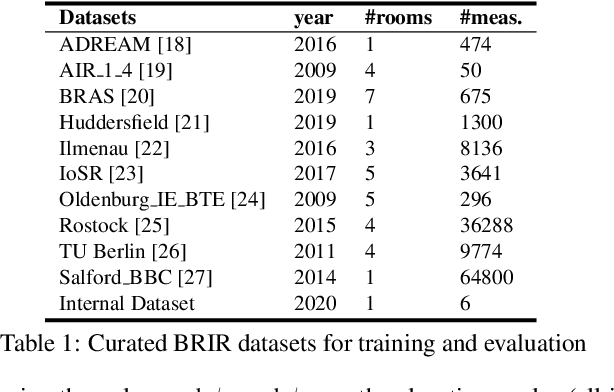
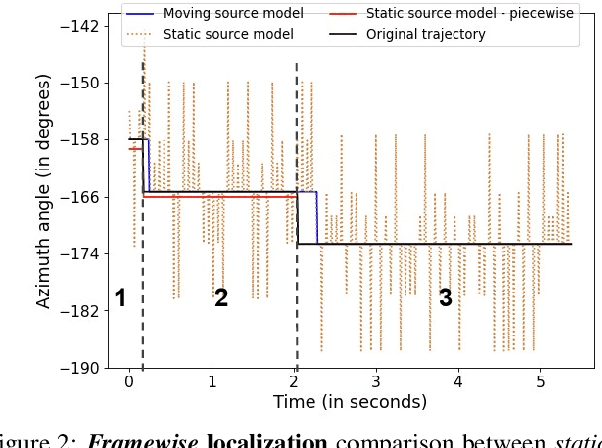

Subjective evaluations are critical for assessing the perceptual realism of sounds in audio-synthesis driven technologies like augmented and virtual reality. However, they are challenging to set up, fatiguing for users, and expensive. In this work, we tackle the problem of capturing the perceptual characteristics of localizing sounds. Specifically, we propose a framework for building a general purpose quality metric to assess spatial localization differences between two binaural recordings. We model localization similarity by utilizing activation-level distances from deep networks trained for direction of arrival (DOA) estimation. Our proposed metric (DPLM) outperforms baseline metrics on correlation with subjective ratings on a diverse set of datasets, even without the benefit of any human-labeled training data.