 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUFFIN: Protein Unit Discovery with Functional Supervision
Apr 16, 2026Proteins carry out biological functions through the coordinated action of groups of residues organized into structural arrangements. These arrangements, which we refer to as protein units, exist at an intermediate scale, being larger than individual residues yet smaller than entire proteins. A deeper understanding of protein function can be achieved by identifying these units and their associations with function. However, existing approaches either focus on residue-level signals, rely on curated annotations, or segment protein structures without incorporating functional information, thereby limiting interpretable analysis of structure-function relationships. We introduce PUFFIN, a data-driven framework for discovering protein units by jointly learning structural partitioning and functional supervision. PUFFIN represents proteins as residue-level structure graphs and applies a graph neural network with a structure-aware pooling mechanism that partitions each protein into multi-residue units, with functional supervision that shapes the partition. We show that the learned units are structurally coherent, exhibit organized associations with molecular function, and show meaningful correspondence with curated InterPro annotations. Together, these results demonstrate that PUFFIN provides an interpretable framework for analyzing structure-function relationships using learned protein units and their statistical function associations. We made our source code available at https://github.com/boun-tabi-lifelu/puffin.
Balancing Methods for Multi-label Text Classification with Long-Tailed Class Distribution
Sep 10, 2021
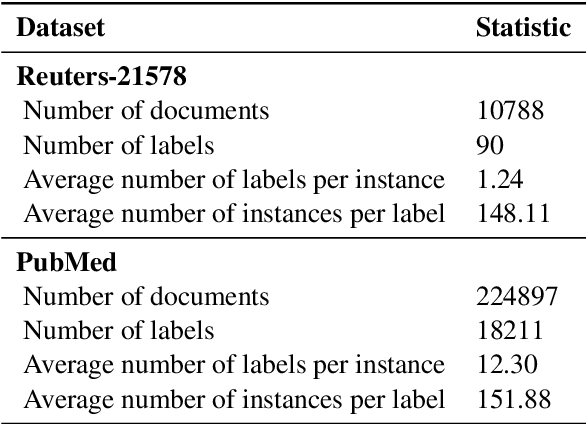
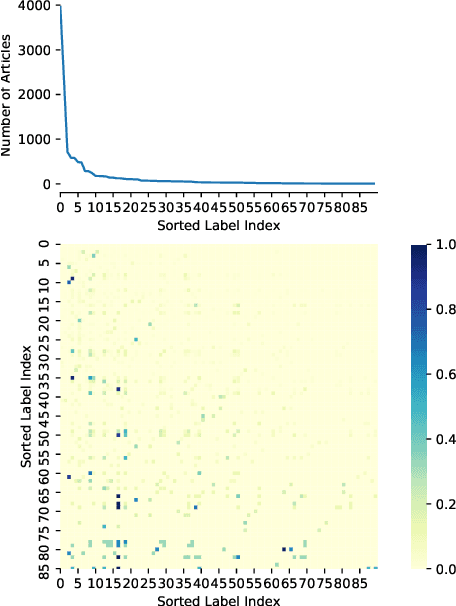
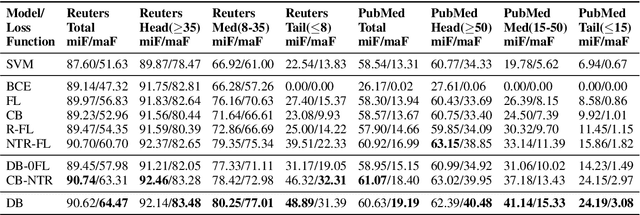
Multi-label text classification is a challenging task because it requires capturing label dependencies. It becomes even more challenging when class distribution is long-tailed. Resampling and re-weighting are common approaches used for addressing the class imbalance problem, however, they are not effective when there is label dependency besides class imbalance because they result in oversampling of common labels. Here, we introduce the application of balancing loss functions for multi-label text classification. We perform experiments on a general domain dataset with 90 labels (Reuters-21578) and a domain-specific dataset from PubMed with 18211 labels. We find that a distribution-balanced loss function, which inherently addresses both the class imbalance and label linkage problems, outperforms commonly used loss functions. Distribution balancing methods have been successfully used in the image recognition field. Here, we show their effectiveness in natural language processing. Source code is available at https://github.com/blessu/BalancedLossNLP.