 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mixtures of Gaussians with Censored Data
May 06, 2023We study the problem of learning mixtures of Gaussians with censored data. Statistical learning with censored data is a classical problem, with numerous practical applications, however, finite-sample guarantees for even simple latent variable models such as Gaussian mixtures are missing. Formally, we are given censored data from a mixture of univariate Gaussians $$\sum_{i=1}^k w_i \mathcal{N}(\mu_i,\sigma^2),$$ i.e. the sample is observed only if it lies inside a set $S$. The goal is to learn the weights $w_i$ and the means $\mu_i$. We propose an algorithm that takes only $\frac{1}{\varepsilon^{O(k)}}$ samples to estimate the weights $w_i$ and the means $\mu_i$ within $\varepsilon$ error.
DAGMA: Learning DAGs via M-matrices and a Log-Determinant Acyclicity Characterization
Sep 16, 2022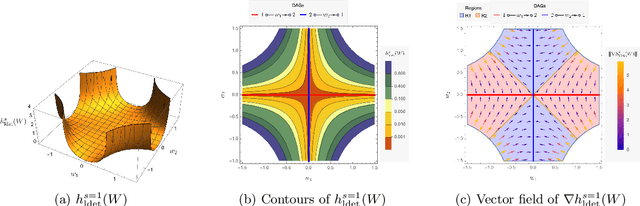
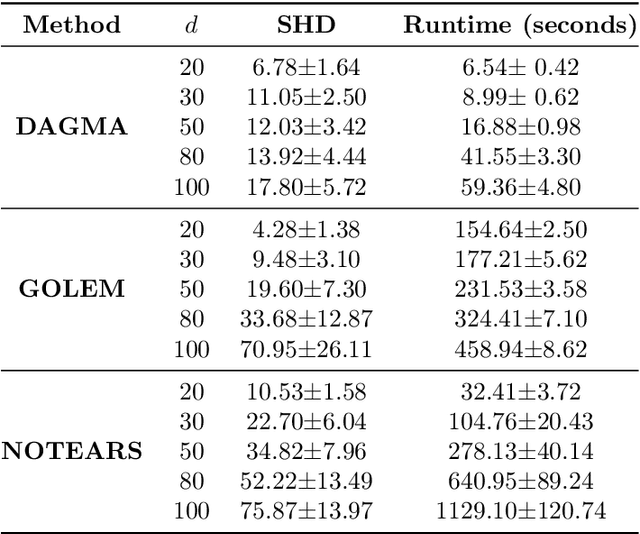
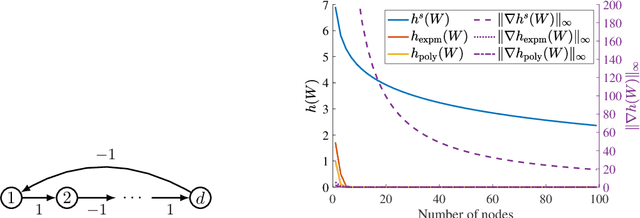
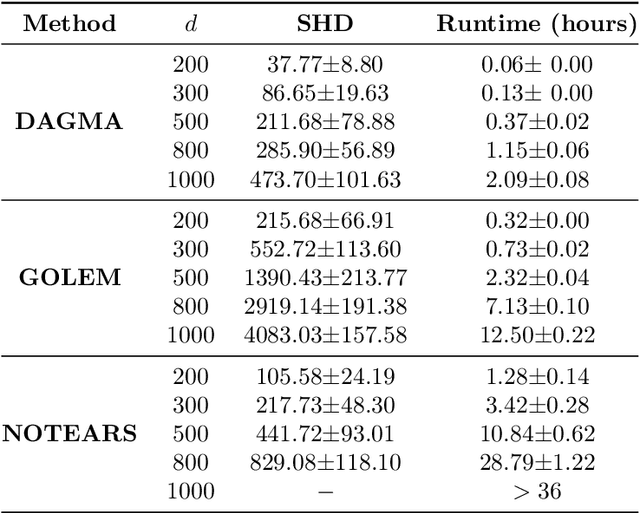
The combinatorial problem of learning directed acyclic graphs (DAGs) from data was recently framed as a purely continuous optimization problem by leveraging a differentiable acyclicity characterization of DAGs based on the trace of a matrix exponential function. Existing acyclicity characterizations are based on the idea that powers of an adjacency matrix contain information about walks and cycles. In this work, we propose a $\textit{fundamentally different}$ acyclicity characterization based on the log-determinant (log-det) function, which leverages the nilpotency property of DAGs. To deal with the inherent asymmetries of a DAG, we relate the domain of our log-det characterization to the set of $\textit{M-matrices}$, which is a key difference to the classical log-det function defined over the cone of positive definite matrices. Similar to acyclicity functions previously proposed, our characterization is also exact and differentiable. However, when compared to existing characterizations, our log-det function: (1) Is better at detecting large cycles; (2) Has better-behaved gradients; and (3) Its runtime is in practice about an order of magnitude faster. From the optimization side, we drop the typically used augmented Lagrangian scheme, and propose DAGMA ($\textit{Directed Acyclic Graphs via M-matrices for Acyclicity}$), a method that resembles the central path for barrier methods. Each point in the central path of DAGMA is a solution to an unconstrained problem regularized by our log-det function, then we show that at the limit of the central path the solution is guaranteed to be a DAG. Finally, we provide extensive experiments for $\textit{linear}$ and $\textit{nonlinear}$ SEMs, and show that our approach can reach large speed-ups and smaller structural Hamming distances against state-of-the-art methods.
Identifiability of deep generative models under mixture priors without auxiliary information
Jun 20, 2022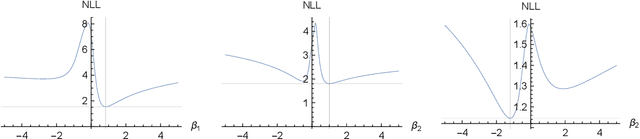


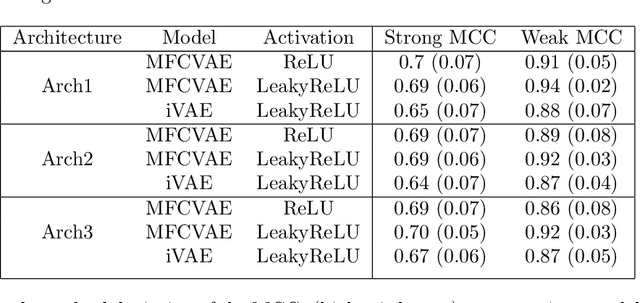
We prove identifiability of a broad class of deep latent variable models that (a) have universal approximation capabilities and (b) are the decoders of variational autoencoders that are commonly used in practice. Unlike existing work, our analysis does not require weak supervision, auxiliary information, or conditioning in the latent space. Recently, there has been a surge of works studying identifiability of such models. In these works, the main assumption is that along with the data, an auxiliary variable $u$ (also known as side information) is observed as well. At the same time, several works have empirically observed that this doesn't seem to be necessary in practice. In this work, we explain this behavior by showing that for a broad class of generative (i.e. unsupervised) models with universal approximation capabilities, the side information $u$ is not necessary: We prove identifiability of the entire generative model where we do not observe $u$ and only observe the data $x$. The models we consider are tightly connected with autoencoder architectures used in practice that leverage mixture priors in the latent space and ReLU/leaky-ReLU activations in the encoder. Our main result is an identifiability hierarchy that significantly generalizes previous work and exposes how different assumptions lead to different "strengths" of identifiability. For example, our weakest result establishes (unsupervised) identifiability up to an affine transformation, which already improves existing work. It's well known that these models have universal approximation capabilities and moreover, they have been extensively used in practice to learn representations of data.
A non-graphical representation of conditional independence via the neighbourhood lattice
Jun 12, 2022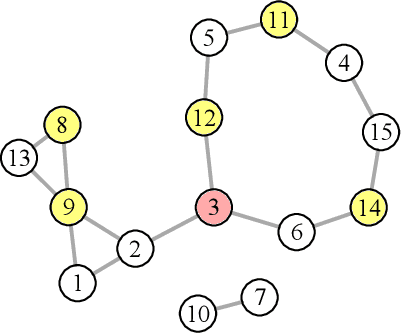

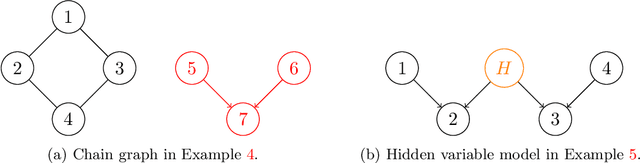

We introduce and study the neighbourhood lattice decomposition of a distribution, which is a compact, non-graphical representation of conditional independence that is valid in the absence of a faithful graphical representation. The idea is to view the set of neighbourhoods of a variable as a subset lattice, and partition this lattice into convex sublattices, each of which directly encodes a collection of conditional independence relations. We show that this decomposition exists in any compositional graphoid and can be computed efficiently and consistently in high-dimensions. {In particular, this gives a way to encode all of independence relations implied by a distribution that satisfies the composition axiom, which is strictly weaker than the faithfulness assumption that is typically assumed by graphical approaches.} We also discuss various special cases such as graphical models and projection lattices, each of which has intuitive interpretations. Along the way, we see how this problem is closely related to neighbourhood regression, which has been extensively studied in the context of graphical models and structural equations.
A super-polynomial lower bound for learning nonparametric mixtures
Mar 28, 2022
We study the problem of learning nonparametric distributions in a finite mixture, and establish a super-polynomial lower bound on the sample complexity of learning the component distributions in such models. Namely, we are given i.i.d. samples from $f$ where $$ f=\sum_{i=1}^k w_i f_i, \quad\sum_{i=1}^k w_i=1, \quad w_i>0 $$ and we are interested in learning each component $f_i$. Without any assumptions on $f_i$, this problem is ill-posed. In order to identify the components $f_i$, we assume that each $f_i$ can be written as a convolution of a Gaussian and a compactly supported density $\nu_i$ with $\text{supp}(\nu_i)\cap \text{supp}(\nu_j)=\emptyset$. Our main result shows that $\Omega((\frac{1}{\varepsilon})^{C\log\log \frac{1}{\varepsilon}})$ samples are required for estimating each $f_i$. The proof relies on a fast rate for approximation with Gaussians, which may be of independent interest. This result has important implications for the hardness of learning more general nonparametric latent variable models that arise in machine learning applications.
Optimal estimation of Gaussian DAG models
Jan 25, 2022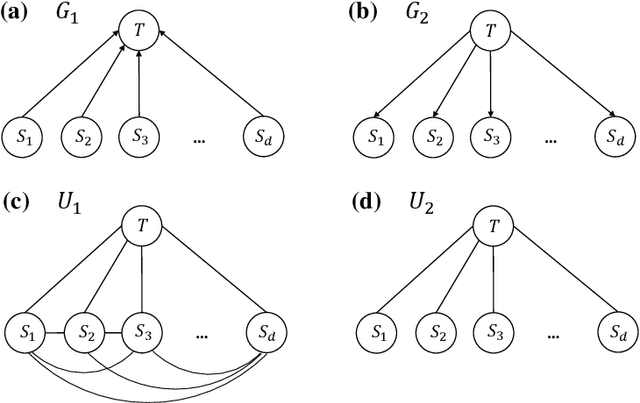
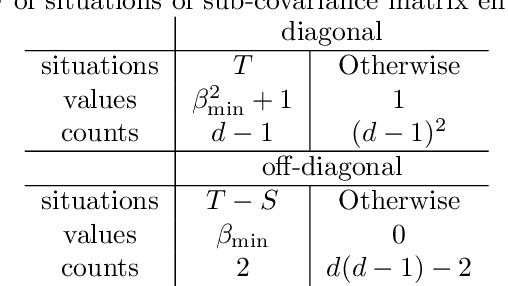
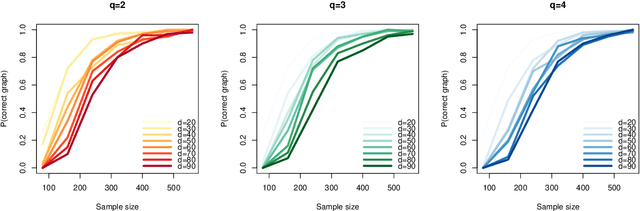
We study the optimal sample complexity of learning a Gaussian directed acyclic graph (DAG) from observational data. Our main result establishes the minimax optimal sample complexity for learning the structure of a linear Gaussian DAG model with equal variances to be $n\asymp q\log(d/q)$, where $q$ is the maximum number of parents and $d$ is the number of nodes. We further make comparisons with the classical problem of learning (undirected) Gaussian graphical models, showing that under the equal variance assumption, these two problems share the same optimal sample complexity. In other words, at least for Gaussian models with equal error variances, learning a directed graphical model is not more difficult than learning an undirected graphical model. Our results also extend to more general identification assumptions as well as subgaussian errors.
Tradeoffs of Linear Mixed Models in Genome-wide Association Studies
Nov 05, 2021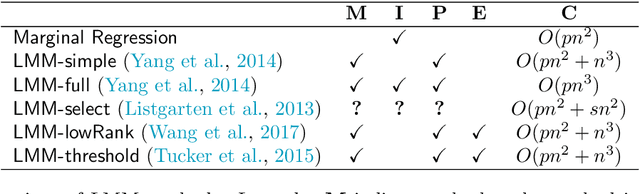
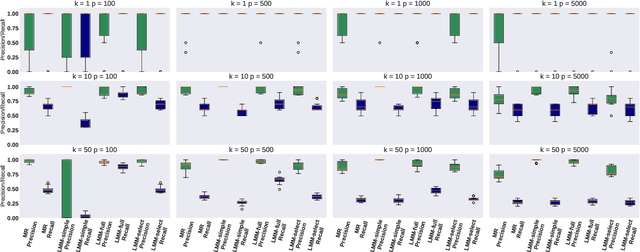
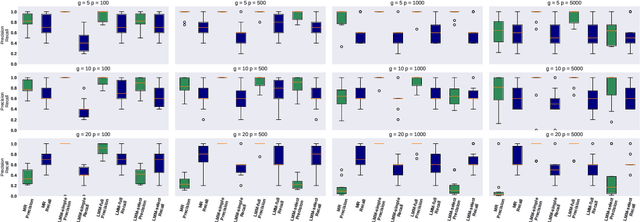
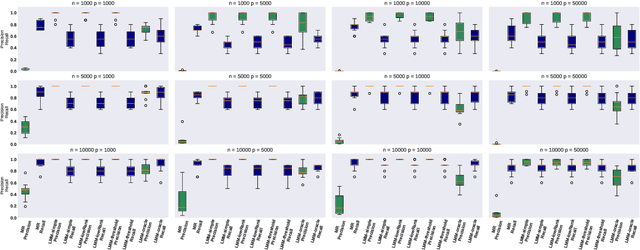
Motivated by empirical arguments that are well-known from the genome-wide association studies (GWAS) literature, we study the statistical properties of linear mixed models (LMMs) applied to GWAS. First, we study the sensitivity of LMMs to the inclusion of a candidate SNP in the kinship matrix, which is often done in practice to speed up computations. Our results shed light on the size of the error incurred by including a candidate SNP, providing a justification to this technique in order to trade-off velocity against veracity. Second, we investigate how mixed models can correct confounders in GWAS, which is widely accepted as an advantage of LMMs over traditional methods. We consider two sources of confounding factors, population stratification and environmental confounding factors, and study how different methods that are commonly used in practice trade-off these two confounding factors differently.
NOTMAD: Estimating Bayesian Networks with Sample-Specific Structures and Parameters
Nov 01, 2021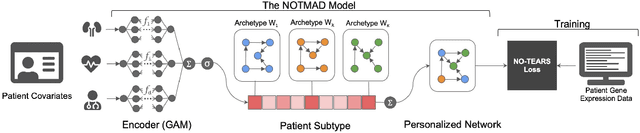


Context-specific Bayesian networks (i.e. directed acyclic graphs, DAGs) identify context-dependent relationships between variables, but the non-convexity induced by the acyclicity requirement makes it difficult to share information between context-specific estimators (e.g. with graph generator functions). For this reason, existing methods for inferring context-specific Bayesian networks have favored breaking datasets into subsamples, limiting statistical power and resolution, and preventing the use of multidimensional and latent contexts. To overcome this challenge, we propose NOTEARS-optimized Mixtures of Archetypal DAGs (NOTMAD). NOTMAD models context-specific Bayesian networks as the output of a function which learns to mix archetypal networks according to sample context. The archetypal networks are estimated jointly with the context-specific networks and do not require any prior knowledge. We encode the acyclicity constraint as a smooth regularization loss which is back-propagated to the mixing function; in this way, NOTMAD shares information between context-specific acyclic graphs, enabling the estimation of Bayesian network structures and parameters at even single-sample resolution. We demonstrate the utility of NOTMAD and sample-specific network inference through analysis and experiments, including patient-specific gene expression networks which correspond to morphological variation in cancer.
Structure learning in polynomial time: Greedy algorithms, Bregman information, and exponential families
Oct 28, 2021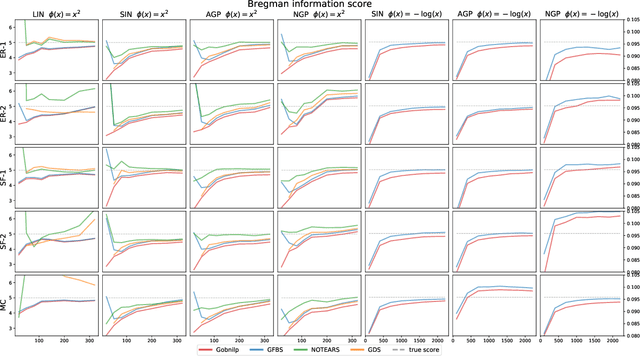
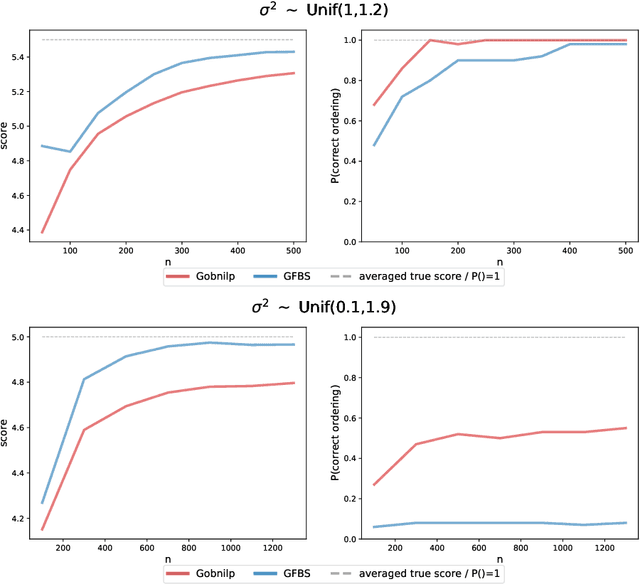
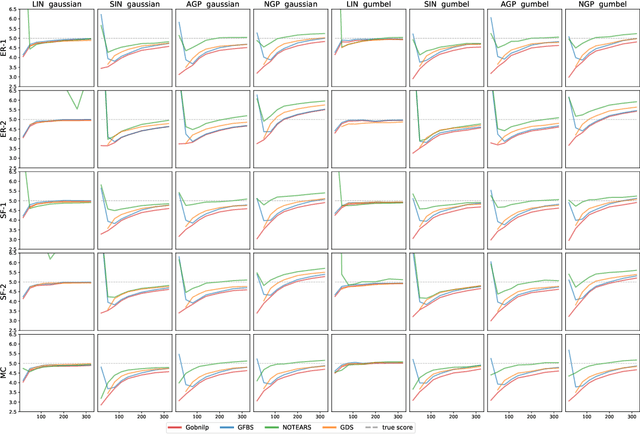
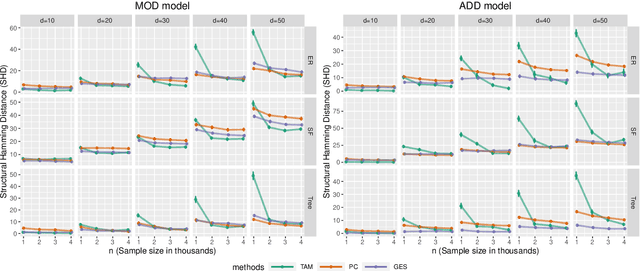
Greedy algorithms have long been a workhorse for learning graphical models, and more broadly for learning statistical models with sparse structure. In the context of learning directed acyclic graphs, greedy algorithms are popular despite their worst-case exponential runtime. In practice, however, they are very efficient. We provide new insight into this phenomenon by studying a general greedy score-based algorithm for learning DAGs. Unlike edge-greedy algorithms such as the popular GES and hill-climbing algorithms, our approach is vertex-greedy and requires at most a polynomial number of score evaluations. We then show how recent polynomial-time algorithms for learning DAG models are a special case of this algorithm, thereby illustrating how these order-based algorithms can be rigourously interpreted as score-based algorithms. This observation suggests new score functions and optimality conditions based on the duality between Bregman divergences and exponential families, which we explore in detail. Explicit sample and computational complexity bounds are derived. Finally, we provide extensive experiments suggesting that this algorithm indeed optimizes the score in a variety of settings.
Efficient Bayesian network structure learning via local Markov boundary search
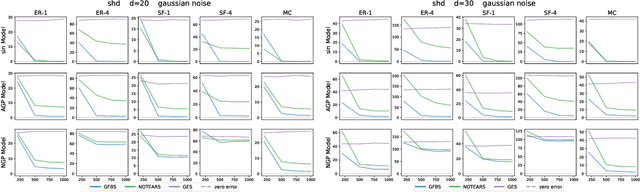
Oct 12, 2021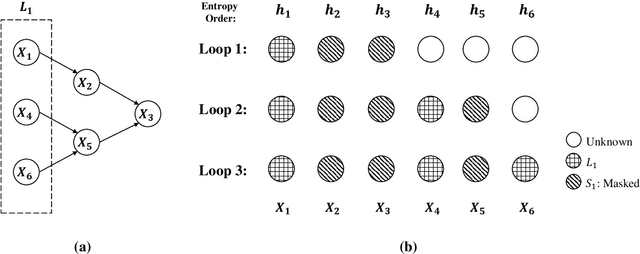
We analyze the complexity of learning directed acyclic graphical models from observational data in general settings without specific distributional assumptions. Our approach is information-theoretic and uses a local Markov boundary search procedure in order to recursively construct ancestral sets in the underlying graphical model. Perhaps surprisingly, we show that for certain graph ensembles, a simple forward greedy search algorithm (i.e. without a backward pruning phase) suffices to learn the Markov boundary of each node. This substantially improves the sample complexity, which we show is at most polynomial in the number of nodes. This is then applied to learn the entire graph under a novel identifiability condition that generalizes existing conditions from the literature. As a matter of independent interest, we establish finite-sample guarantees for the problem of recovering Markov boundaries from data. Moreover, we apply our results to the special case of polytrees, for which the assumptions simplify, and provide explicit conditions under which polytrees are identifiable and learnable in polynomial time. We further illustrate the performance of the algorithm, which is easy to implement, in a simulation study. Our approach is general, works for discrete or continuous distributions without distributional assumptions, and as such sheds light on the minimal assumptions required to efficiently learn the structure of directed graphical models from data.