 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Oriented Influence-Maximizing Data Acquisition for Learning and Optimization
Feb 23, 2026Active data acquisition is central to many learning and optimization tasks in deep neural networks, yet remains challenging because most approaches rely on predictive uncertainty estimates that are difficult to obtain reliably. To this end, we propose Goal-Oriented Influence- Maximizing Data Acquisition (GOIMDA), an active acquisition algorithm that avoids explicit posterior inference while remaining uncertainty-aware through inverse curvature. GOIMDA selects inputs by maximizing their expected influence on a user-specified goal functional, such as test loss, predictive entropy, or the value of an optimizer-recommended design. Leveraging first-order influence functions, we derive a tractable acquisition rule that combines the goal gradient, training-loss curvature, and candidate sensitivity to model parameters. We show theoretically that, for generalized linear models, GOIMDA approximates predictive-entropy minimization up to a correction term accounting for goal alignment and prediction bias, thereby, yielding uncertainty-aware behavior without maintaining a Bayesian posterior. Empirically, across learning tasks (including image and text classification) and optimization tasks (including noisy global optimization benchmarks and neural-network hyperparameter tuning), GOIMDA consistently reaches target performance with substantially fewer labeled samples or function evaluations than uncertainty-based active learning and Gaussian-process Bayesian optimization baselines.
Identifying Consistent Statements about Numerical Data with Dispersion-Corrected Subgroup Discovery
Apr 23, 2017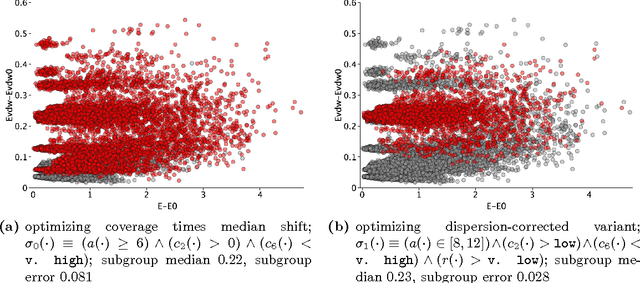
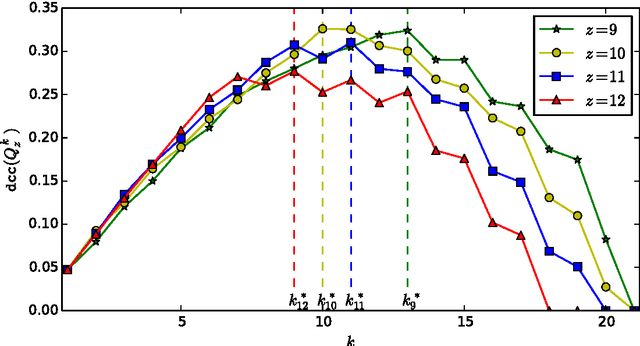
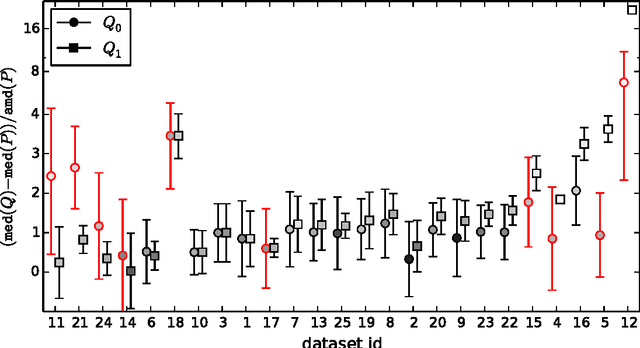
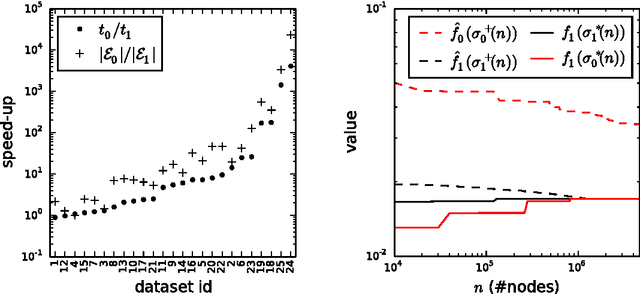
Existing algorithms for subgroup discovery with numerical targets do not optimize the error or target variable dispersion of the groups they find. This often leads to unreliable or inconsistent statements about the data, rendering practical applications, especially in scientific domains, futile. Therefore, we here extend the optimistic estimator framework for optimal subgroup discovery to a new class of objective functions: we show how tight estimators can be computed efficiently for all functions that are determined by subgroup size (non-decreasing dependence), the subgroup median value, and a dispersion measure around the median (non-increasing dependence). In the important special case when dispersion is measured using the average absolute deviation from the median, this novel approach yields a linear time algorithm. Empirical evaluation on a wide range of datasets shows that, when used within branch-and-bound search, this approach is highly efficient and indeed discovers subgroups with much smaller errors.