 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWearable data from subjects playing Super Mario, sitting university exams, or performing physical exercise help detect acute mood episodes via self-supervised learning
Nov 07, 2023



Personal sensing, leveraging data passively and near-continuously collected with wearables from patients in their ecological environment, is a promising paradigm to monitor mood disorders (MDs), a major determinant of worldwide disease burden. However, collecting and annotating wearable data is very resource-intensive. Studies of this kind can thus typically afford to recruit only a couple dozens of patients. This constitutes one of the major obstacles to applying modern supervised machine learning techniques to MDs detection. In this paper, we overcome this data bottleneck and advance the detection of MDs acute episode vs stable state from wearables data on the back of recent advances in self-supervised learning (SSL). This leverages unlabelled data to learn representations during pre-training, subsequently exploited for a supervised task. First, we collected open-access datasets recording with an Empatica E4 spanning different, unrelated to MD monitoring, personal sensing tasks -- from emotion recognition in Super Mario players to stress detection in undergraduates -- and devised a pre-processing pipeline performing on-/off-body detection, sleep-wake detection, segmentation, and (optionally) feature extraction. With 161 E4-recorded subjects, we introduce E4SelfLearning, the largest to date open access collection, and its pre-processing pipeline. Second, we show that SSL confidently outperforms fully-supervised pipelines using either our novel E4-tailored Transformer architecture (E4mer) or classical baseline XGBoost: 81.23% against 75.35% (E4mer) and 72.02% (XGBoost) correctly classified recording segments from 64 (half acute, half stable) patients. Lastly, we illustrate that SSL performance is strongly associated with the specific surrogate task employed for pre-training as well as with unlabelled data availability.
V1T: large-scale mouse V1 response prediction using a Vision Transformer
Feb 27, 2023



Accurate predictive models of the visual cortex neural response to natural visual stimuli remain a challenge in computational neuroscience. In this work, we introduce V1T, a novel Vision Transformer based architecture that learns a shared visual and behavioral representation across animals. We evaluate our model on two large datasets recorded from mouse primary visual cortex and outperform previous convolution-based models by more than 12.7% in prediction performance. Moreover, we show that the attention weights learned by the Transformer correlate with the population receptive fields. Our model thus sets a new benchmark for neural response prediction and captures characteristic features of the visual cortex.
Neuronal Learning Analysis using Cycle-Consistent Adversarial Networks
Nov 25, 2021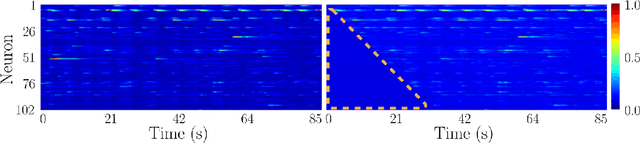
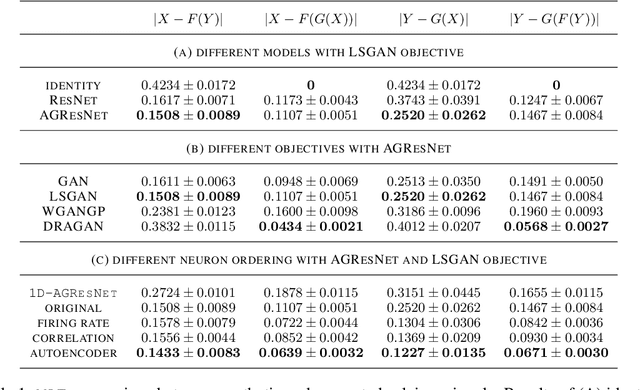
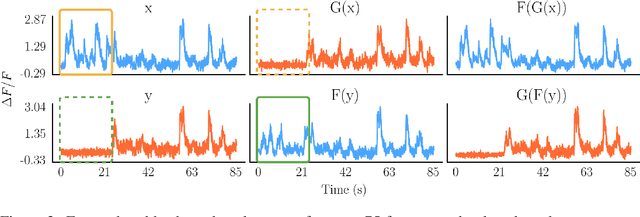

Understanding how activity in neural circuits reshapes following task learning could reveal fundamental mechanisms of learning. Thanks to the recent advances in neural imaging technologies, high-quality recordings can be obtained from hundreds of neurons over multiple days or even weeks. However, the complexity and dimensionality of population responses pose significant challenges for analysis. Existing methods of studying neuronal adaptation and learning often impose strong assumptions on the data or model, resulting in biased descriptions that do not generalize. In this work, we use a variant of deep generative models called - CycleGAN, to learn the unknown mapping between pre- and post-learning neural activities recorded $\textit{in vivo}$. We develop an end-to-end pipeline to preprocess, train and evaluate calcium fluorescence signals, and a procedure to interpret the resulting deep learning models. To assess the validity of our method, we first test our framework on a synthetic dataset with known ground-truth transformation. Subsequently, we applied our method to neural activities recorded from the primary visual cortex of behaving mice, where the mice transition from novice to expert-level performance in a visual-based virtual reality experiment. We evaluate model performance on generated calcium signals and their inferred spike trains. To maximize performance, we derive a novel approach to pre-sort neurons such that convolutional-based networks can take advantage of the spatial information that exists in neural activities. In addition, we incorporate visual explanation methods to improve the interpretability of our work and gain insights into the learning process as manifested in the cellular activities. Together, our results demonstrate that analyzing neuronal learning processes with data-driven deep unsupervised methods holds the potential to unravel changes in an unbiased way.
CalciumGAN: A Generative Adversarial Network Model for Synthesising Realistic Calcium Imaging Data of Neuronal Populations
Sep 08, 2020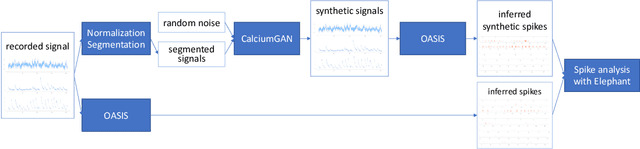
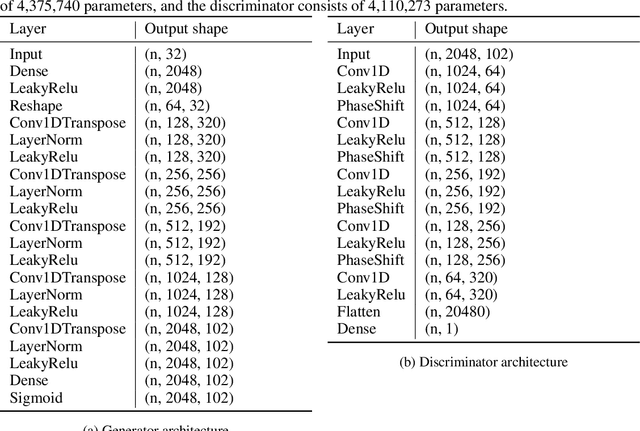
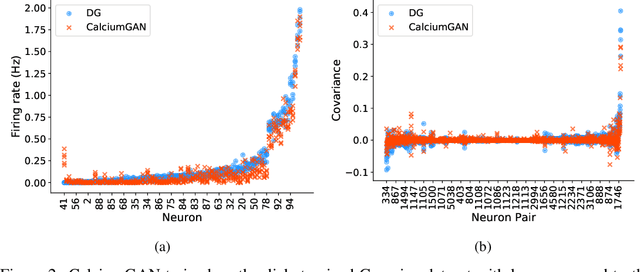

Calcium imaging has become a powerful and popular technique to monitor the activity of large populations of neurons in vivo. However, for ethical considerations and despite recent technical developments, recordings are still constrained to a limited number of trials and animals. This limits the amount of data available from individual experiments and hinders the development of analysis techniques and models for more realistic size of neuronal populations. The ability to artificially synthesize realistic neuronal calcium signals could greatly alleviate this problem by scaling up the number of trials. Here we propose a Generative Adversarial Network (GAN) model to generate realistic calcium signals as seen in neuronal somata with calcium imaging. To this end, we adapt the WaveGAN architecture and train it with the Wasserstein distance. We test the model on artificial data with known ground-truth and show that the distribution of the generated signals closely resembles the underlying data distribution. Then, we train the model on real calcium signals recorded from the primary visual cortex of behaving mice and confirm that the deconvolved spike trains match the statistics of the recorded data. Together, these results demonstrate that our model can successfully generate realistic calcium imaging data, thereby providing the means to augment existing datasets of neuronal activity for enhanced data exploration and modeling.
Unsupervised Cipher Cracking Using Discrete GANs
Jan 15, 2018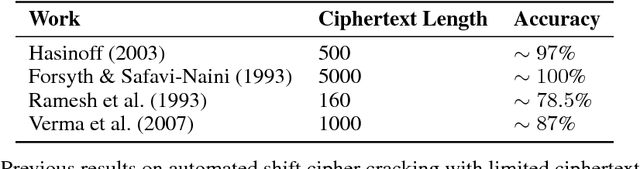


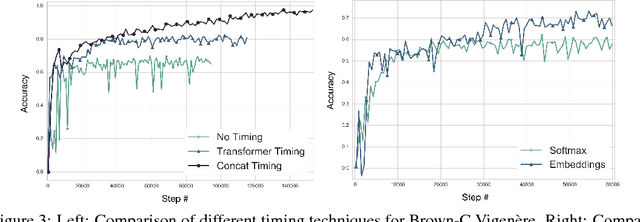
This work details CipherGAN, an architecture inspired by CycleGAN used for inferring the underlying cipher mapping given banks of unpaired ciphertext and plaintext. We demonstrate that CipherGAN is capable of cracking language data enciphered using shift and Vigenere ciphers to a high degree of fidelity and for vocabularies much larger than previously achieved. We present how CycleGAN can be made compatible with discrete data and train in a stable way. We then prove that the technique used in CipherGAN avoids the common problem of uninformative discrimination associated with GANs applied to discrete data.