 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automatic Interaction Detection Hybrid Model for Bankcard Response Classification
Jan 02, 2019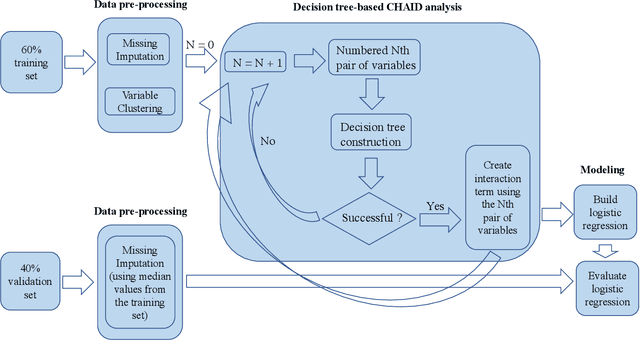
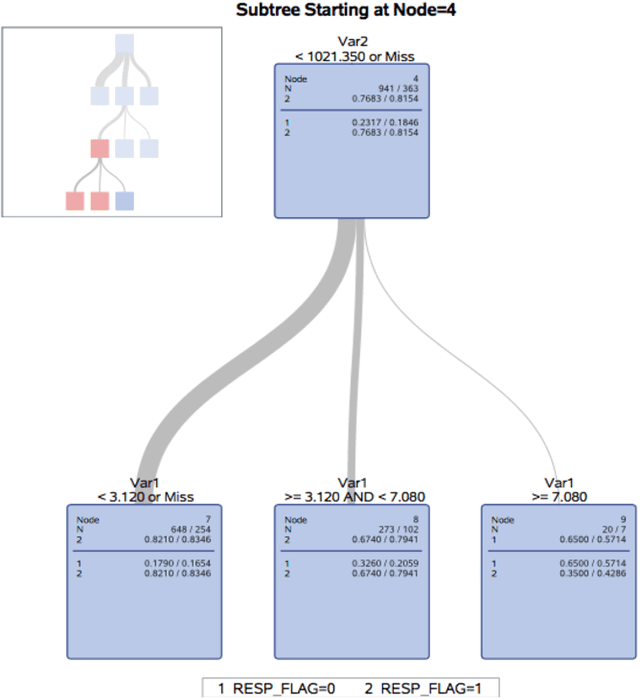
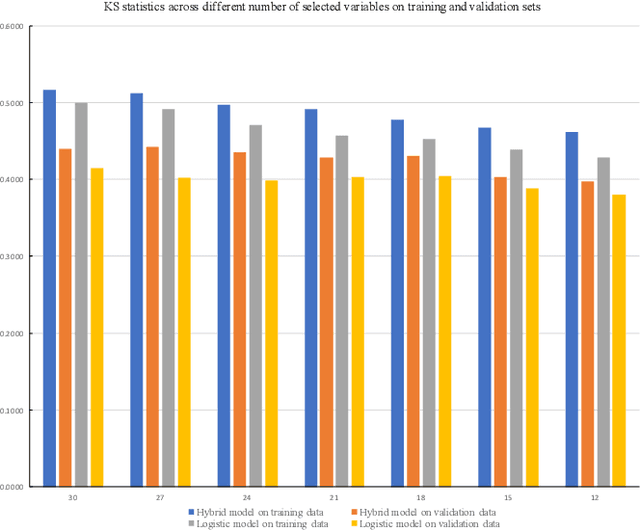
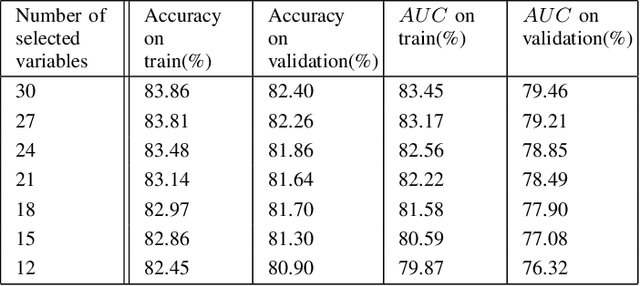
In this paper, we propose a hybrid bankcard response model, which integrates decision tree based chi-square automatic interaction detection (CHAID) into logistic regression. In the first stage of the hybrid model, CHAID analysis is used to detect the possibly potential variable interactions. Then in the second stage, these potential interactions are served as the additional input variables in logistic regression. The motivation of the proposed hybrid model is that adding variable interactions may improve the performance of logistic regression. To demonstrate the effectiveness of the proposed hybrid model, it is evaluated on a real credit customer response data set. As the results reveal, by identifying potential interactions among independent variables, the proposed hybrid approach outperforms the logistic regression without searching for interactions in terms of classification accuracy, the area under the receiver operating characteristic curve (ROC), and Kolmogorov-Smirnov (KS) statistics. Furthermore, CHAID analysis for interaction detection is much more computationally efficient than the stepwise search mentioned above and some identified interactions are shown to have statistically significant predictive power on the target variable. Last but not least, the customer profile created based on the CHAID tree provides a reasonable interpretation of the interactions, which is the required by regulations of the credit industry. Hence, this study provides an alternative for handling bankcard classification tasks.
A two-stage hybrid model by using artificial neural networks as feature construction algorithms
Dec 06, 2018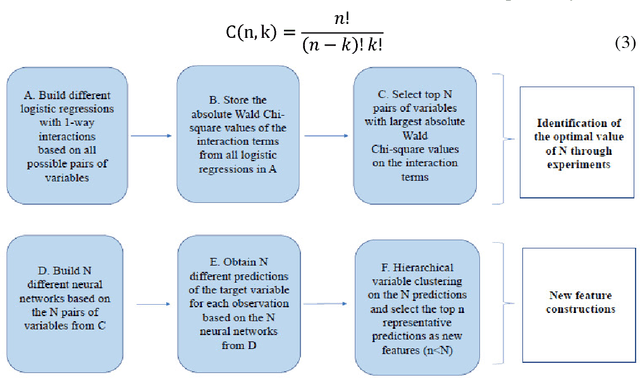
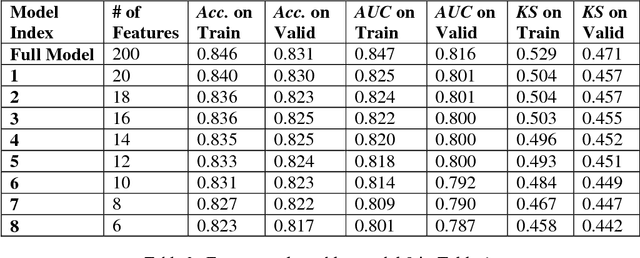
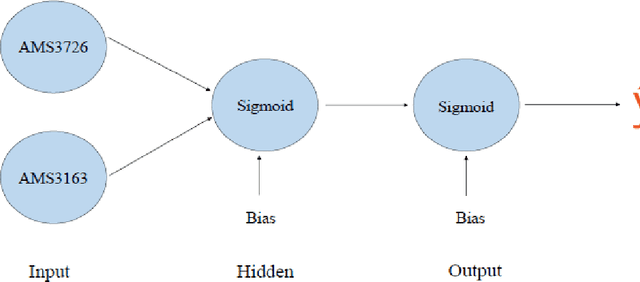
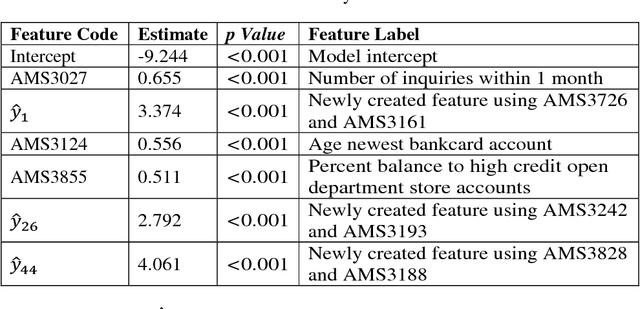
We propose a two-stage hybrid approach with neural networks as the new feature construction algorithms for bankcard response classifications. The hybrid model uses a very simple neural network structure as the new feature construction tool in the first stage, then the newly created features are used as the additional input variables in logistic regression in the second stage. The model is compared with the traditional one-stage model in credit customer response classification. It is observed that the proposed two-stage model outperforms the one-stage model in terms of accuracy, the area under ROC curve, and KS statistic. By creating new features with the neural network technique, the underlying nonlinear relationships between variables are identified. Furthermore, by using a very simple neural network structure, the model could overcome the drawbacks of neural networks in terms of its long training time, complex topology, and limited interpretability.