 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVCD: A New Method for Unsupervised Change Detection in the Open-Vocabulary Era
Dec 18, 2025



Change detection (CD) identifies scene changes from multi-temporal observations and is widely used in urban development and environmental monitoring. Most existing CD methods rely on supervised learning, making performance strongly dataset-dependent and incurring high annotation costs; they typically focus on a few predefined categories and generalize poorly to diverse scenes. With the rise of vision foundation models such as SAM2 and CLIP, new opportunities have emerged to relax these constraints. We propose Unified Open-Vocabulary Change Detection (UniVCD), an unsupervised, open-vocabulary change detection method built on frozen SAM2 and CLIP. UniVCD detects category-agnostic changes across diverse scenes and imaging geometries without any labeled data or paired change images. A lightweight feature alignment module is introduced to bridge the spatially detailed representations from SAM2 and the semantic priors from CLIP, enabling high-resolution, semantically aware change estimation while keeping the number of trainable parameters small. On top of this, a streamlined post-processing pipeline is further introduced to suppress noise and pseudo-changes, improving the detection accuracy for objects with well-defined boundaries. Experiments on several public BCD (Binary Change Detection) and SCD (Semantic Change Detection) benchmarks show that UniVCD achieves consistently strong performance and matches or surpasses existing open-vocabulary CD methods in key metrics such as F1 and IoU. The results demonstrate that unsupervised change detection with frozen vision foundation models and lightweight multi-modal alignment is a practical and effective paradigm for open-vocabulary CD. Code and pretrained models will be released at https://github.com/Die-Xie/UniVCD.
Efficient Masked Image Compression with Position-Indexed Self-Attention
Apr 17, 2025In recent years, image compression for high-level vision tasks has attracted considerable attention from researchers. Given that object information in images plays a far more crucial role in downstream tasks than background information, some studies have proposed semantically structuring the bitstream to selectively transmit and reconstruct only the information required by these tasks. However, such methods structure the bitstream after encoding, meaning that the coding process still relies on the entire image, even though much of the encoded information will not be transmitted. This leads to redundant computations. Traditional image compression methods require a two-dimensional image as input, and even if the unimportant regions of the image are set to zero by applying a semantic mask, these regions still participate in subsequent computations as part of the image. To address such limitations, we propose an image compression method based on a position-indexed self-attention mechanism that encodes and decodes only the visible parts of the masked image. Compared to existing semantic-structured compression methods, our approach can significantly reduce computational costs.
Soft Hierarchical Graph Recurrent Networks for Many-Agent Partially Observable Environments
Sep 05, 2021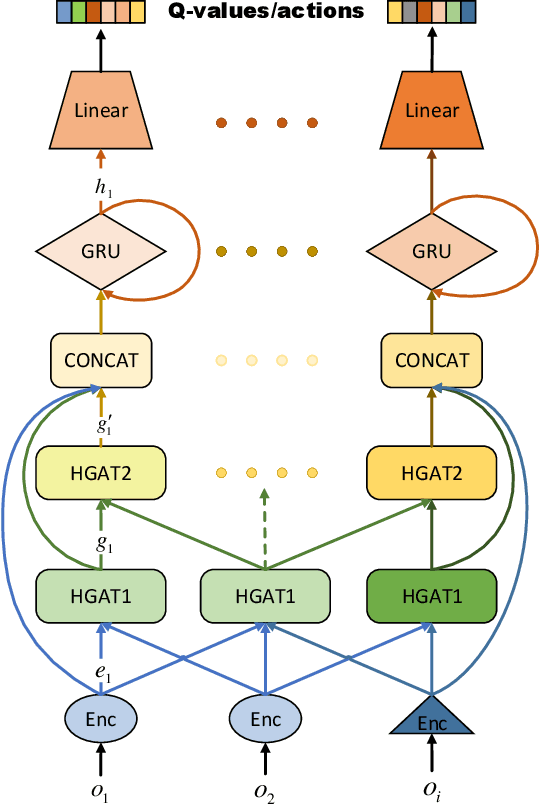
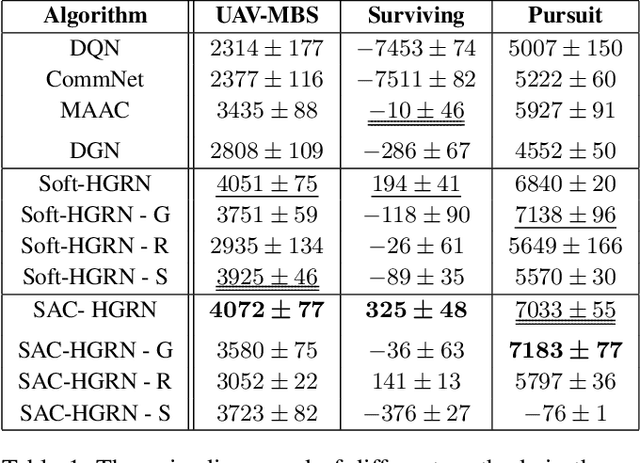
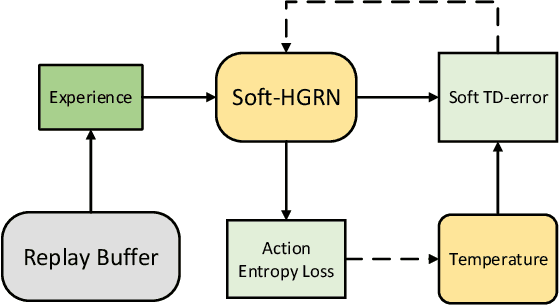
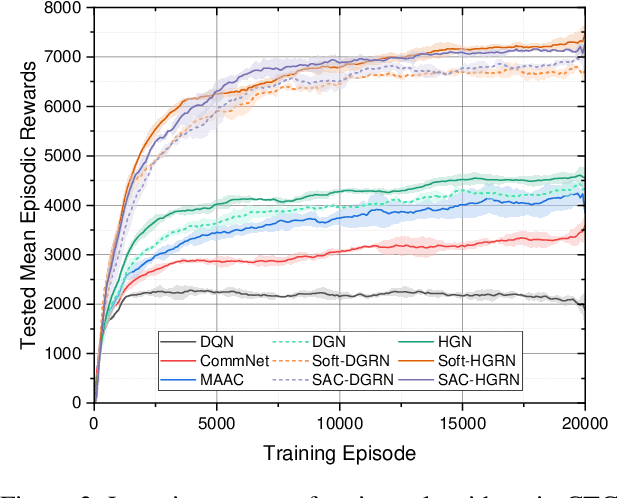
The recent progress in multi-agent deep reinforcement learning(MADRL) makes it more practical in real-world tasks, but its relatively poor scalability and the partially observable constraints raise challenges to its performance and deployment. Based on our intuitive observation that the human society could be regarded as a large-scale partially observable environment, where each individual has the function of communicating with neighbors and remembering its own experience, we propose a novel network structure called hierarchical graph recurrent network(HGRN) for multi-agent cooperation under partial observability. Specifically, we construct the multi-agent system as a graph, use the hierarchical graph attention network(HGAT) to achieve communication between neighboring agents, and exploit GRU to enable agents to record historical information. To encourage exploration and improve robustness, we design a maximum-entropy learning method to learn stochastic policies of a configurable target action entropy. Based on the above technologies, we proposed a value-based MADRL algorithm called Soft-HGRN and its actor-critic variant named SAC-HRGN. Experimental results based on three homogeneous tasks and one heterogeneous environment not only show that our approach achieves clear improvements compared with four baselines, but also demonstrates the interpretability, scalability, and transferability of the proposed model. Ablation studies prove the function and necessity of each component.
Experience Augmentation: Boosting and Accelerating Off-Policy Multi-Agent Reinforcement Learning
May 20, 2020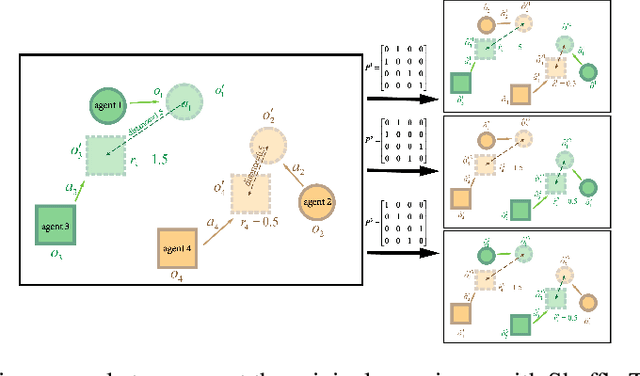

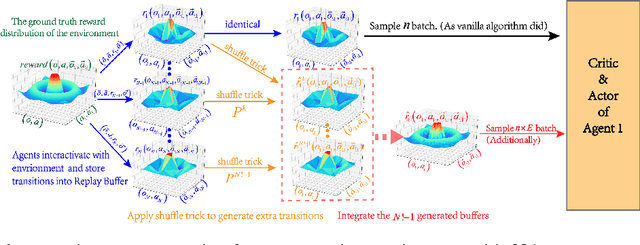

Exploration of the high-dimensional state action space is one of the biggest challenges in Reinforcement Learning (RL), especially in multi-agent domain. We present a novel technique called Experience Augmentation, which enables a time-efficient and boosted learning based on a fast, fair and thorough exploration to the environment. It can be combined with arbitrary off-policy MARL algorithms and is applicable to either homogeneous or heterogeneous environments. We demonstrate our approach by combining it with MADDPG and verifing the performance in two homogeneous and one heterogeneous environments. In the best performing scenario, the MADDPG with experience augmentation reaches to the convergence reward of vanilla MADDPG with 1/4 realistic time, and its convergence beats the original model by a significant margin. Our ablation studies show that experience augmentation is a crucial ingredient which accelerates the training process and boosts the convergence.