 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAS-LitEval : Multi-Agent System for Literary Translation Quality Assessment
Jun 17, 2025Literary translation requires preserving cultural nuances and stylistic elements, which traditional metrics like BLEU and METEOR fail to assess due to their focus on lexical overlap. This oversight neglects the narrative consistency and stylistic fidelity that are crucial for literary works. To address this, we propose MAS-LitEval, a multi-agent system using Large Language Models (LLMs) to evaluate translations based on terminology, narrative, and style. We tested MAS-LitEval on translations of The Little Prince and A Connecticut Yankee in King Arthur's Court, generated by various LLMs, and compared it to traditional metrics. \textbf{MAS-LitEval} outperformed these metrics, with top models scoring up to 0.890 in capturing literary nuances. This work introduces a scalable, nuanced framework for Translation Quality Assessment (TQA), offering a practical tool for translators and researchers.
Data Augmentation Strategies for Improving Sequential Recommender Systems
Mar 26, 2022
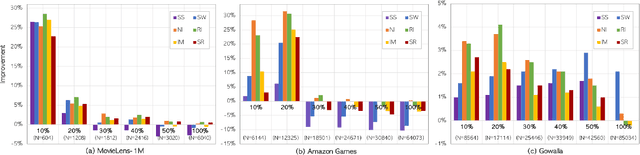
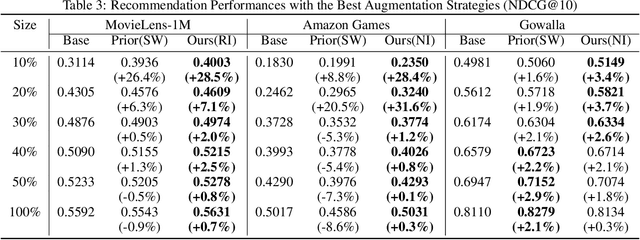
Sequential recommender systems have recently achieved significant performance improvements with the exploitation of deep learning (DL) based methods. However, although various DL-based methods have been introduced, most of them only focus on the transformations of network structure, neglecting the importance of other influential factors including data augmentation. Obviously, DL-based models require a large amount of training data in order to estimate parameters well and achieve high performances, which leads to the early efforts to increase the training data through data augmentation in computer vision and speech domains. In this paper, we seek to figure out that various data augmentation strategies can improve the performance of sequential recommender systems, especially when the training dataset is not large enough. To this end, we propose a simple set of data augmentation strategies, all of which transform original item sequences in the way of direct corruption and describe how data augmentation changes the performance. Extensive experiments on the latest DL-based model show that applying data augmentation can help the model generalize better, and it can be significantly effective to boost model performances especially when the amount of training data is small. Furthermore, it is shown that our proposed strategies can improve performances to a better or competitive level to existing strategies suggested in the prior works.
Enhancing VAEs for Collaborative Filtering: Flexible Priors & Gating Mechanisms
Nov 03, 2019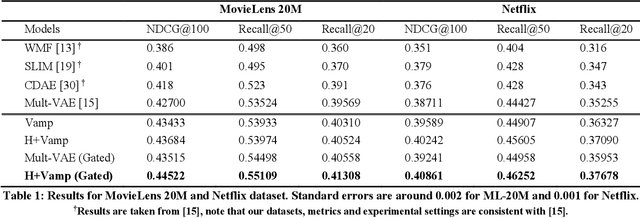
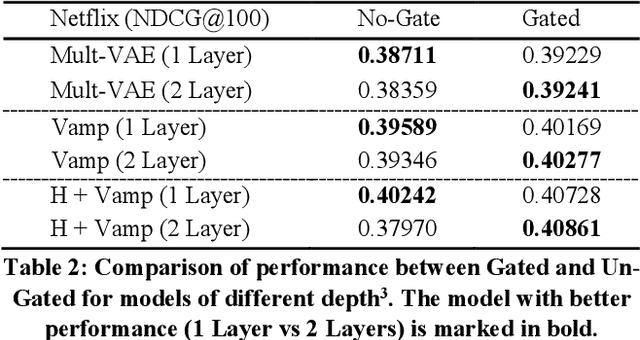
Neural network based models for collaborative filtering have started to gain attention recently. One branch of research is based on using deep generative models to model user preferences where variational autoencoders were shown to produce state-of-the-art results. However, there are some potentially problematic characteristics of the current variational autoencoder for CF. The first is the too simplistic prior that VAEs incorporate for learning the latent representations of user preference. The other is the model's inability to learn deeper representations with more than one hidden layer for each network. Our goal is to incorporate appropriate techniques to mitigate the aforementioned problems of variational autoencoder CF and further improve the recommendation performance. Our work is the first to apply flexible priors to collaborative filtering and show that simple priors (in original VAEs) may be too restrictive to fully model user preferences and setting a more flexible prior gives significant gains. We experiment with the VampPrior, originally proposed for image generation, to examine the effect of flexible priors in CF. We also show that VampPriors coupled with gating mechanisms outperform SOTA results including the Variational Autoencoder for Collaborative Filtering by meaningful margins on 2 popular benchmark datasets (MovieLens & Netflix).