 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Difficulty of Automatically Generated Questions via Reinforcement Learning with Synthetic Preference
Oct 10, 2024



As the cultural heritage sector increasingly adopts technologies like Retrieval-Augmented Generation (RAG) to provide more personalised search experiences and enable conversations with collections data, the demand for specialised evaluation datasets has grown. While end-to-end system testing is essential, it's equally important to assess individual components. We target the final, answering task, which is well-suited to Machine Reading Comprehension (MRC). Although existing MRC datasets address general domains, they lack the specificity needed for cultural heritage information. Unfortunately, the manual creation of such datasets is prohibitively expensive for most heritage institutions. This paper presents a cost-effective approach for generating domain-specific MRC datasets with increased difficulty using Reinforcement Learning from Human Feedback (RLHF) from synthetic preference data. Our method leverages the performance of existing question-answering models on a subset of SQuAD to create a difficulty metric, assuming that more challenging questions are answered correctly less frequently. This research contributes: (1) A methodology for increasing question difficulty using PPO and synthetic data; (2) Empirical evidence of the method's effectiveness, including human evaluation; (3) An in-depth error analysis and study of emergent phenomena; and (4) An open-source codebase and set of three llama-2-chat adapters for reproducibility and adaptation.
Bi-Link: Bridging Inductive Link Predictions from Text via Contrastive Learning of Transformers and Prompts
Oct 26, 2022



Inductive knowledge graph completion requires models to comprehend the underlying semantics and logic patterns of relations. With the advance of pretrained language models, recent research have designed transformers for link prediction tasks. However, empirical studies show that linearizing triples affects the learning of relational patterns, such as inversion and symmetry. In this paper, we propose Bi-Link, a contrastive learning framework with probabilistic syntax prompts for link predictions. Using grammatical knowledge of BERT, we efficiently search for relational prompts according to learnt syntactical patterns that generalize to large knowledge graphs. To better express symmetric relations, we design a symmetric link prediction model, establishing bidirectional linking between forward prediction and backward prediction. This bidirectional linking accommodates flexible self-ensemble strategies at test time. In our experiments, Bi-Link outperforms recent baselines on link prediction datasets (WN18RR, FB15K-237, and Wikidata5M). Furthermore, we construct Zeshel-Ind as an in-domain inductive entity linking the environment to evaluate Bi-Link. The experimental results demonstrate that our method yields robust representations which can generalize under domain shift.
Angular Gap: Reducing the Uncertainty of Image Difficulty through Model Calibration
Jul 18, 2022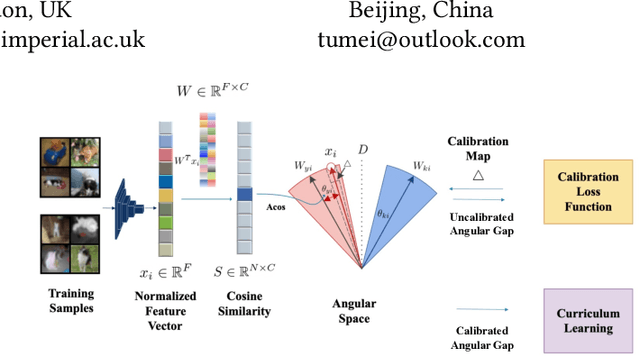
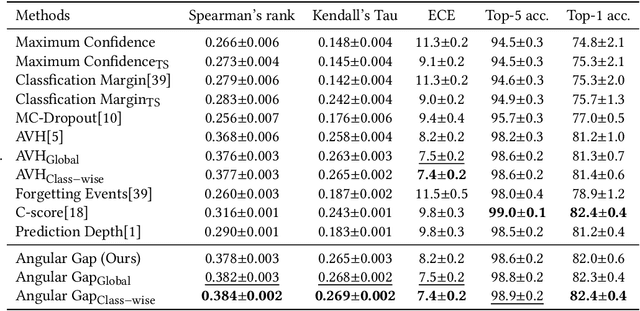
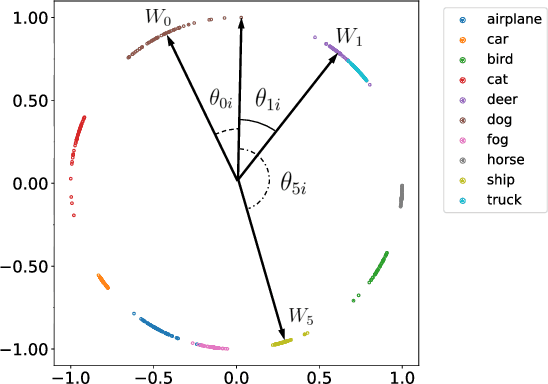
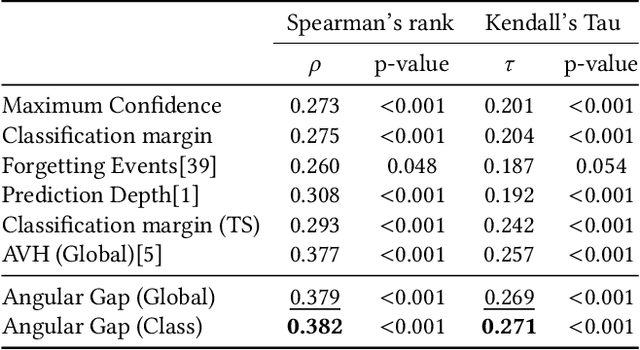
Curriculum learning needs example difficulty to proceed from easy to hard. However, the credibility of image difficulty is rarely investigated, which can seriously affect the effectiveness of curricula. In this work, we propose Angular Gap, a measure of difficulty based on the difference in angular distance between feature embeddings and class-weight embeddings built by hyperspherical learning. To ascertain difficulty estimation, we introduce class-wise model calibration, as a post-training technique, to the learnt hyperbolic space. This bridges the gap between probabilistic model calibration and angular distance estimation of hyperspherical learning. We show the superiority of our calibrated Angular Gap over recent difficulty metrics on CIFAR10-H and ImageNetV2. We further propose Angular Gap based curriculum learning for unsupervised domain adaptation that can translate from learning easy samples to mining hard samples. We combine this curriculum with a state-of-the-art self-training method, Cycle Self Training (CST). The proposed Curricular CST learns robust representations and outperforms recent baselines on Office31 and VisDA 2017.