 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLJ-Bench: Ontology-Based Benchmark for U.S. Crime
Mar 21, 2026The potential of Large Language Models (LLMs) to provide harmful information remains a significant concern due to the vast breadth of illegal queries they may encounter. Unfortunately, existing benchmarks only focus on a handful types of illegal activities, and are not grounded in legal works. In this work, we introduce an ontology of crime-related concepts grounded in the legal frameworks of Model Panel Code, which serves as an influential reference for criminal law and has been adopted by many U.S. states, and instantiated using Californian Law. This structured knowledge forms the foundation for LJ-Bench, the first comprehensive benchmark designed to evaluate LLM robustness against a wide range of illegal activities. Spanning 76 distinct crime types organized taxonomically, LJ-Bench enables systematic assessment of diverse attacks, revealing valuable insights into LLM vulnerabilities across various crime categories: LLMs exhibit heightened susceptibility to attacks targeting societal harm rather than those directly impacting individuals. Our benchmark aims to facilitate the development of more robust and trustworthy LLMs. The LJ-Bench benchmark and LJ-Ontology, along with experiments implementation for reproducibility are publicly available at https://github.com/AndreaTseng/LJ-Bench.
The Open Review-Based (ORB) dataset: Towards Automatic Assessment of Scientific Papers and Experiment Proposals in High-Energy Physics
Nov 29, 2023



With the Open Science approach becoming important for research, the evolution towards open scientific-paper reviews is making an impact on the scientific community. However, there is a lack of publicly available resources for conducting research activities related to this subject, as only a limited number of journals and conferences currently allow access to their review process for interested parties. In this paper, we introduce the new comprehensive Open Review-Based dataset (ORB); it includes a curated list of more than 36,000 scientific papers with their more than 89,000 reviews and final decisions. We gather this information from two sources: the OpenReview.net and SciPost.org websites. However, given the volatile nature of this domain, the software infrastructure that we introduce to supplement the ORB dataset is designed to accommodate additional resources in the future. The ORB deliverables include (1) Python code (interfaces and implementations) to translate document data and metadata into a structured and high-level representation, (2) an ETL process (Extract, Transform, Load) to facilitate the automatic updates from defined sources and (3) data files representing the structured data. The paper presents our data architecture and an overview of the collected data along with relevant statistics. For illustration purposes, we also discuss preliminary Natural-Language-Processing-based experiments that aim to predict (1) papers' acceptance based on their textual embeddings, and (2) grading statistics inferred from embeddings as well. We believe ORB provides a valuable resource for researchers interested in open science and review, with our implementation easing the use of this data for further analysis and experimentation. We plan to update ORB as the field matures as well as introduce new resources even more fitted to dedicated scientific domains such as High-Energy Physics.
IEDM, an Ontology for Irradiation Experiment Data Management
Jan 16, 2019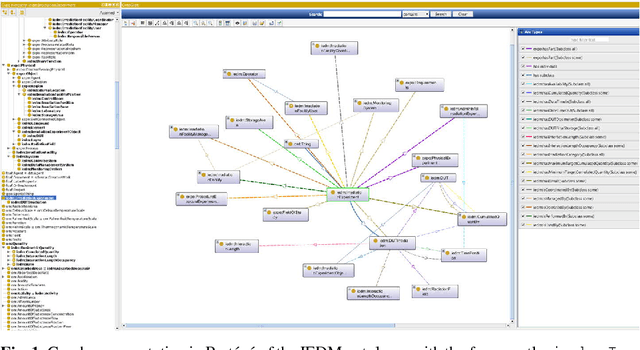
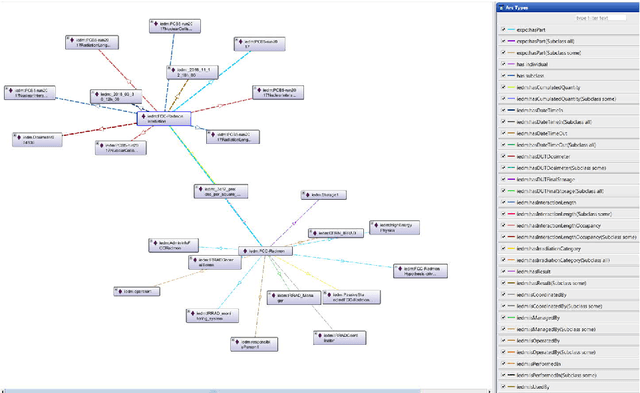
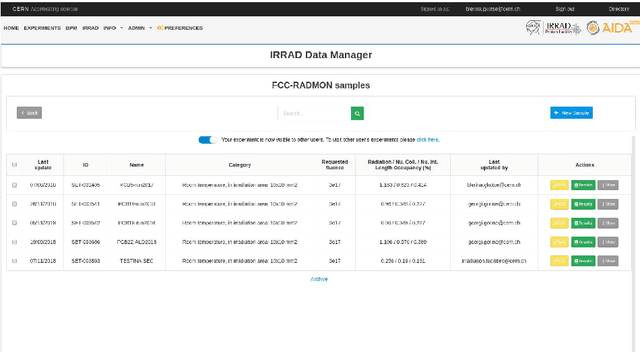
Irradiation experiments (IE) are an essential step in the development of High-Energy Physics (HEP) particle accelerators and detectors. They assess the radiation hardness of materials used in HEP experimental devices by simulating, in a short time, the common long-term degradation effects due to their bombardment by high-energy particles. IEs are also used in other scientific and industrial fields such as medicine (e.g., for cancer treatment, medical imaging, etc.), space/avionics (e.g., for radiation testing of payload equipment) as well as in industry (e.g., for food sterilization). Usually carried out with ionizing radiation, these complex processes require highly specialized infrastructures: the irradiation facilities. Currently, hundreds of such facilities exist worldwide. To help develop best practices and promote computer-assisted handling and management of IEs, we introduce IEDM, a new OWL-based Irradiation Experiment Data Management ontology. This paper provides an overview of the classes and properties of IEDM. Since one of the key design choices for IEDM was to maximize the reuse of existing foundational ontologies such as the Ontology of Scientific Experiments (EXPO), the Ontology of Units of Measure (OM) and the Friend-of-a-Friend Ontology (FOAF), we discuss the methodological issues of the integration of IEDM with these imported ontologies. We illustrate the use of IEDM via an actual IE recently performed at IRRAD, the CERN proton irradiation facility. Finally, we discuss other motivations for this work, including the use of IEDM for the generation of user interfaces for IE management, and their impact on our methodology.