 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepASL: Enabling Ubiquitous and Non-Intrusive Word and Sentence-Level Sign Language Translation
Oct 18, 2018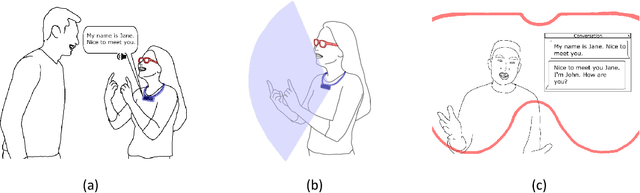
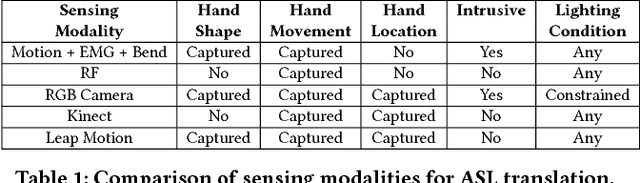
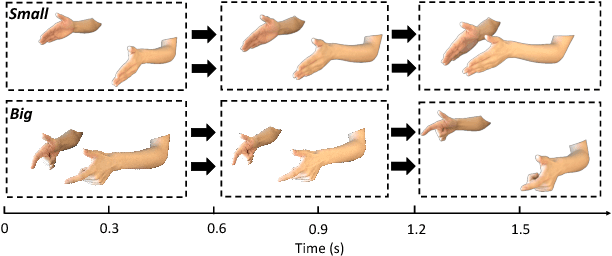
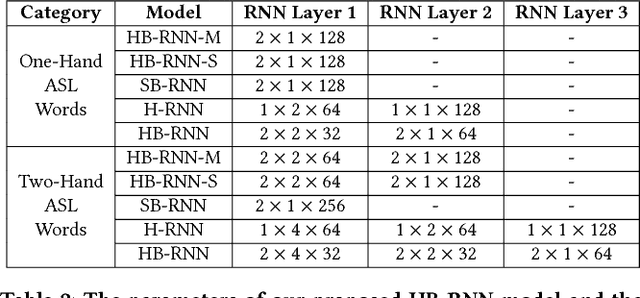
There is an undeniable communication barrier between deaf people and people with normal hearing ability. Although innovations in sign language translation technology aim to tear down this communication barrier, the majority of existing sign language translation systems are either intrusive or constrained by resolution or ambient lighting conditions. Moreover, these existing systems can only perform single-sign ASL translation rather than sentence-level translation, making them much less useful in daily-life communication scenarios. In this work, we fill this critical gap by presenting DeepASL, a transformative deep learning-based sign language translation technology that enables ubiquitous and non-intrusive American Sign Language (ASL) translation at both word and sentence levels. DeepASL uses infrared light as its sensing mechanism to non-intrusively capture the ASL signs. It incorporates a novel hierarchical bidirectional deep recurrent neural network (HB-RNN) and a probabilistic framework based on Connectionist Temporal Classification (CTC) for word-level and sentence-level ASL translation respectively. To evaluate its performance, we have collected 7,306 samples from 11 participants, covering 56 commonly used ASL words and 100 ASL sentences. DeepASL achieves an average 94.5% word-level translation accuracy and an average 8.2% word error rate on translating unseen ASL sentences. Given its promising performance, we believe DeepASL represents a significant step towards breaking the communication barrier between deaf people and hearing majority, and thus has the significant potential to fundamentally change deaf people's lives.
A Stochastic Large-scale Machine Learning Algorithm for Distributed Features and Observations
Mar 29, 2018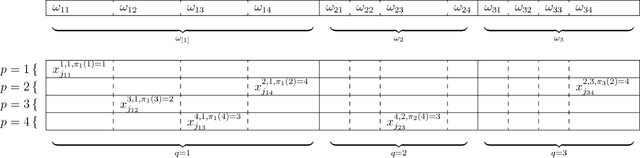

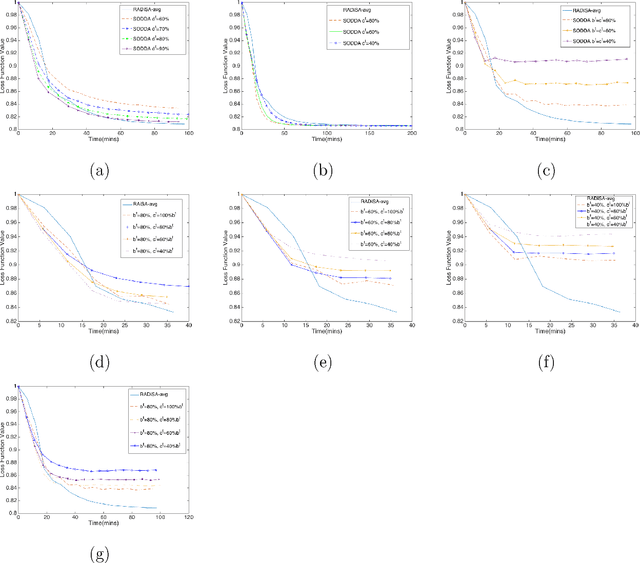
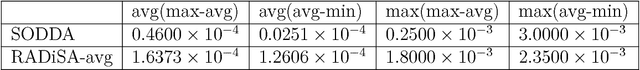
As the size of modern data sets exceeds the disk and memory capacities of a single computer, machine learning practitioners have resorted to parallel and distributed computing. Given that optimization is one of the pillars of machine learning and predictive modeling, distributed optimization methods have recently garnered ample attention, in particular when either observations or features are distributed, but not both. We propose a general stochastic algorithm where observations, features, and gradient components can be sampled in a double distributed setting, i.e., with both features and observations distributed. Very technical analyses establish convergence properties of the algorithm under different conditions on the learning rate (diminishing to zero or constant). Computational experiments in Spark demonstrate a superior performance of our algorithm versus a benchmark in early iterations of the algorithm, which is due to the stochastic components of the algorithm.