 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionable Conversational Quality Indicators for Improving Task-Oriented Dialog Systems
Sep 22, 2021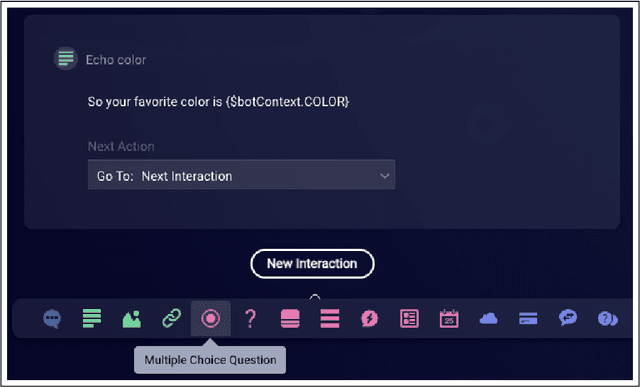
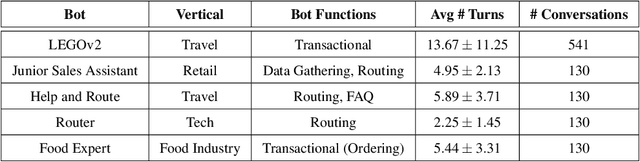
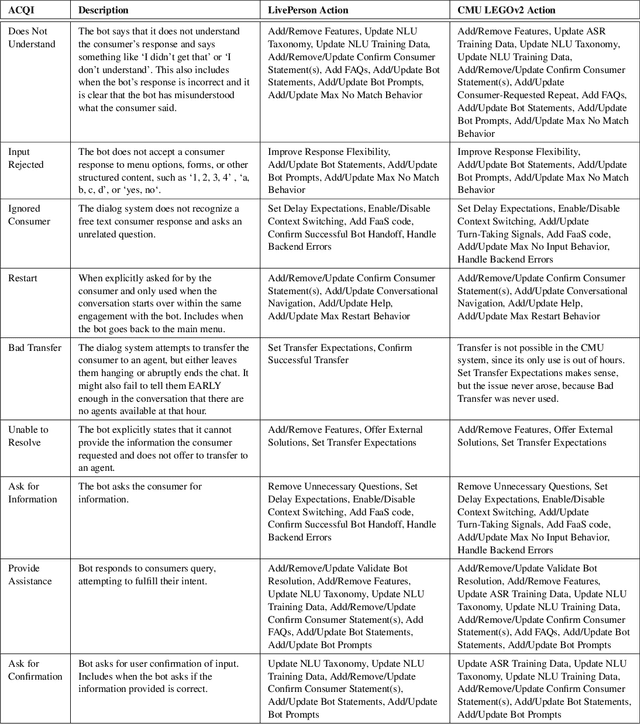
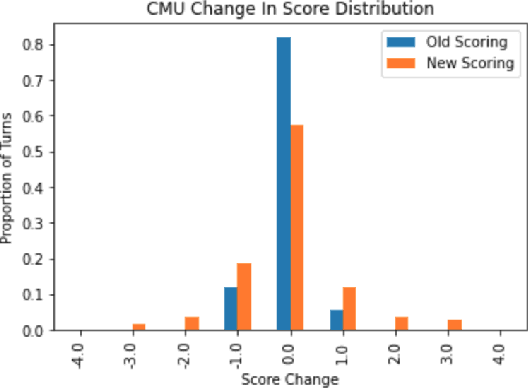
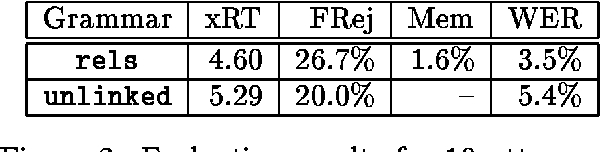
Automatic dialog systems have become a mainstream part of online customer service. Many such systems are built, maintained, and improved by customer service specialists, rather than dialog systems engineers and computer programmers. As conversations between people and machines become commonplace, it is critical to understand what is working, what is not, and what actions can be taken to reduce the frequency of inappropriate system responses. These analyses and recommendations need to be presented in terms that directly reflect the user experience rather than the internal dialog processing. This paper introduces and explains the use of Actionable Conversational Quality Indicators (ACQIs), which are used both to recognize parts of dialogs that can be improved, and to recommend how to improve them. This combines benefits of previous approaches, some of which have focused on producing dialog quality scoring while others have sought to categorize the types of errors the dialog system is making. We demonstrate the effectiveness of using ACQIs on LivePerson internal dialog systems used in commercial customer service applications, and on the publicly available CMU LEGOv2 conversational dataset (Raux et al. 2005). We report on the annotation and analysis of conversational datasets showing which ACQIs are important to fix in various situations. The annotated datasets are then used to build a predictive model which uses a turn-based vector embedding of the message texts and achieves an 79% weighted average f1-measure at the task of finding the correct ACQI for a given conversation. We predict that if such a model worked perfectly, the range of potential improvement actions a bot-builder must consider at each turn could be reduced by an average of 81%.
Compiling Language Models from a Linguistically Motivated Unification Grammar
Jun 09, 2000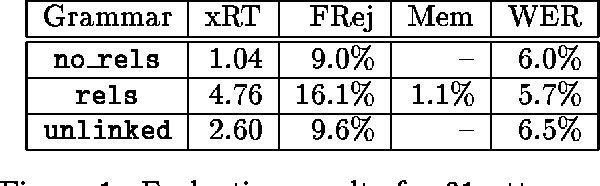
Systems now exist which are able to compile unification grammars into language models that can be included in a speech recognizer, but it is so far unclear whether non-trivial linguistically principled grammars can be used for this purpose. We describe a series of experiments which investigate the question empirically, by incrementally constructing a grammar and discovering what problems emerge when successively larger versions are compiled into finite state graph representations and used as language models for a medium-vocabulary recognition task.
A Compact Architecture for Dialogue Management Based on Scripts and Meta-Outputs
Jun 09, 2000We describe an architecture for spoken dialogue interfaces to semi-autonomous systems that transforms speech signals through successive representations of linguistic, dialogue, and domain knowledge. Each step produces an output, and a meta-output describing the transformation, with an executable program in a simple scripting language as the final result. The output/meta-output distinction permits perspicuous treatment of diverse tasks such as resolving pronouns, correcting user misconceptions, and optimizing scripts.
A Comparison of the XTAG and CLE Grammars for English
Jun 09, 2000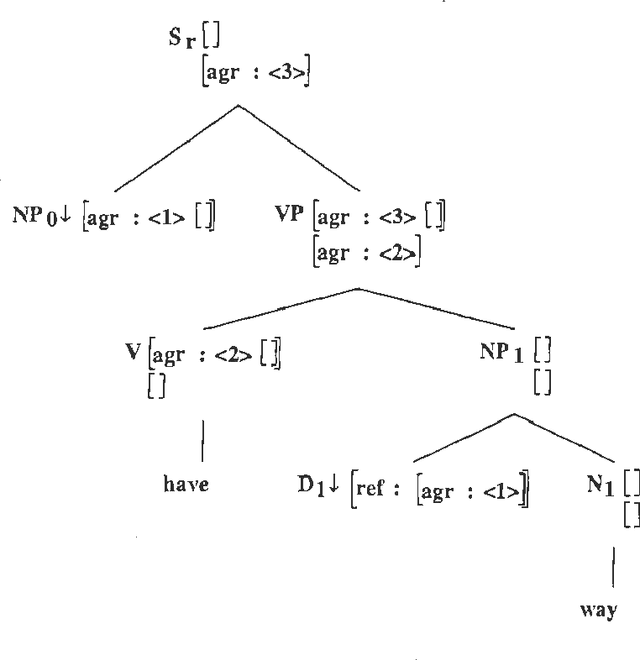
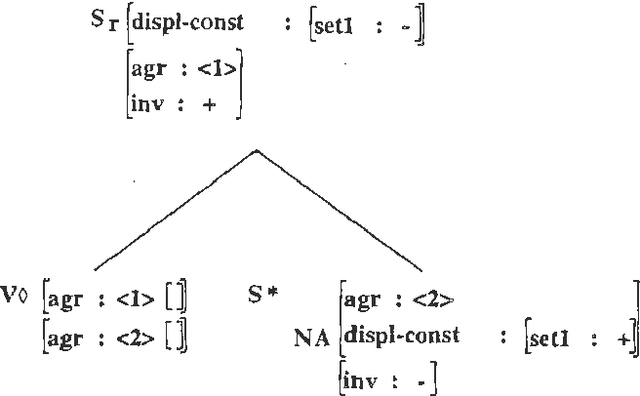
When people develop something intended as a large broad-coverage grammar, they usually have a more specific goal in mind. Sometimes this goal is covering a corpus; sometimes the developers have theoretical ideas they wish to investigate; most often, work is driven by a combination of these two main types of goal. What tends to happen after a while is that the community of people working with the grammar starts thinking of some phenomena as ``central'', and makes serious efforts to deal with them; other phenomena are labelled ``marginal'', and ignored. Before long, the distinction between ``central'' and ``marginal'' becomes so ingrained that it is automatic, and people virtually stop thinking about the ``marginal'' phenomena. In practice, the only way to bring the marginal things back into focus is to look at what other people are doing and compare it with one's own work. In this paper, we will take two large grammars, XTAG and the CLE, and examine each of them from the other's point of view. We will find in both cases not only that important things are missing, but that the perspective offered by the other grammar suggests simple and practical ways of filling in the holes. It turns out that there is a pleasing symmetry to the picture. XTAG has a very good treatment of complement structure, which the CLE to some extent lacks; conversely, the CLE offers a powerful and general account of adjuncts, which the XTAG grammar does not fully duplicate. If we examine the way in which each grammar does the thing it is good at, we find that the relevant methods are quite easy to port to the other framework, and in fact only involve generalization and systematization of existing mechanisms.
Accuracy, Coverage, and Speed: What Do They Mean to Users?
Jun 09, 2000Speech is becoming increasingly popular as an interface modality, especially in hands- and eyes-busy situations where the use of a keyboard or mouse is difficult. However, despite the fact that many have hailed speech as being inherently usable (since everyone already knows how to talk), most users of speech input are left feeling disappointed by the quality of the interaction. Clearly, there is much work to be done on the design of usable spoken interfaces. We believe that there are two major problems in the design of speech interfaces, namely, (a) the people who are currently working on the design of speech interfaces are, for the most part, not interface designers and therefore do not have as much experience with usability issues as we in the CHI community do, and (b) speech, as an interface modality, has vastly different properties than other modalities, and therefore requires different usability measures.
Turning Speech Into Scripts
Jun 09, 2000We describe an architecture for implementing spoken natural language dialogue interfaces to semi-autonomous systems, in which the central idea is to transform the input speech signal through successive levels of representation corresponding roughly to linguistic knowledge, dialogue knowledge, and domain knowledge. The final representation is an executable program in a simple scripting language equivalent to a subset of Cshell. At each stage of the translation process, an input is transformed into an output, producing as a byproduct a "meta-output" which describes the nature of the transformation performed. We show how consistent use of the output/meta-output distinction permits a simple and perspicuous treatment of apparently diverse topics including resolution of pronouns, correction of user misconceptions, and optimization of scripts. The methods described have been concretely realized in a prototype speech interface to a simulation of the Personal Satellite Assistant.
* Working notes from AAAI Spring Symposium
Status of the XTAG System
Nov 03, 1994XTAG is an ongoing project to develop a wide-coverage grammar for English, based on the Feature-based Lexicalized Tree Adjoining Grammar (FB-LTAG) formalism. The XTAG system integrates a morphological analyzer, an N-best part-of-speech tagger, an Early-style parser and an X-window interface, along with a wide-coverage grammar for English developed using the system. This system serves as a linguist's workbench for developing FB-LTAG specifications. This paper presents a description of and recent improvements to the various components of the XTAG system. It also presents the recent performance of the wide-coverage grammar on various corpora and compares it against the performance of other wide-coverage and domain-specific grammars.
* uuencoded compressed ps file. 4 pages
Determining Determiner Sequencing: A Syntactic Analysis for English
Nov 03, 1994Previous work on English determiners has primarily concentrated on their semantics or scoping properties rather than their complex ordering behavior. The little work that has been done on determiner ordering generally splits determiners into three subcategories. However, this small number of categories does not capture the finer distinctions necessary to correctly order determiners. This paper presents a syntactic account of determiner sequencing based on eight independently identified semantic features. Complex determiners, such as genitives, partitives, and determiner modifying adverbials, are also presented. This work has been implemented as part of XTAG, a wide-coverage grammar for English based in the Feature-Based, Lexicalized Tree Adjoining Grammar (FB-LTAG) formalism.
XTAG system - A Wide Coverage Grammar for English
Oct 20, 1994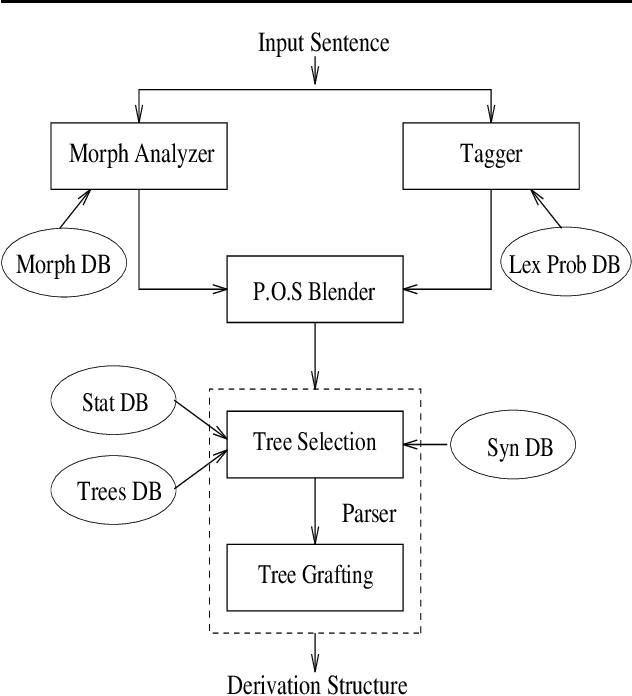

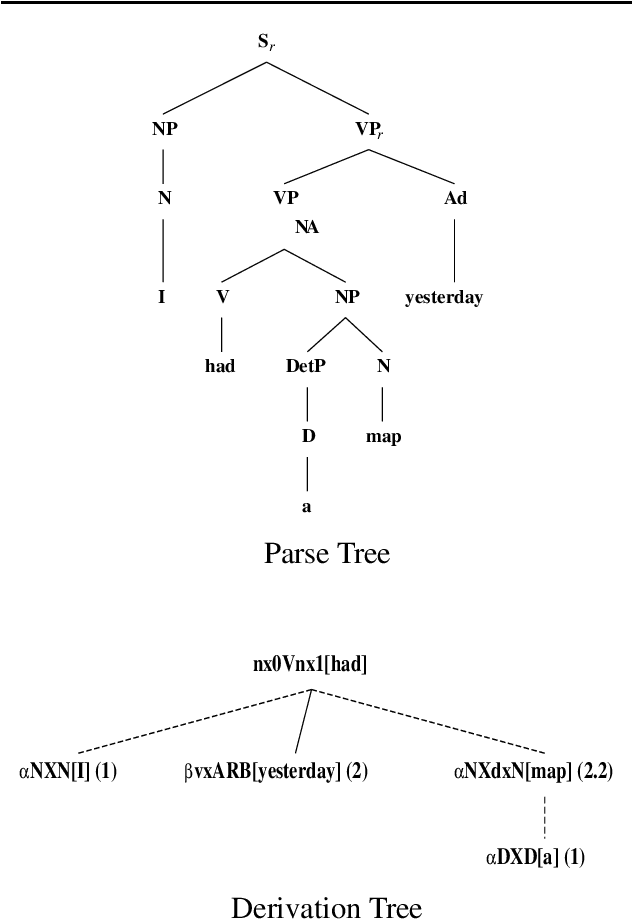
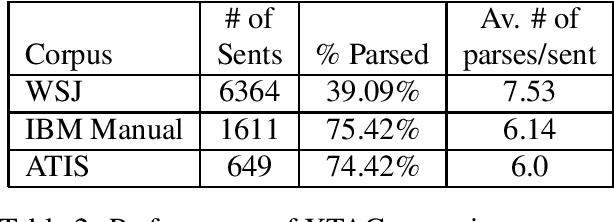
This paper presents the XTAG system, a grammar development tool based on the Tree Adjoining Grammar (TAG) formalism that includes a wide-coverage syntactic grammar for English. The various components of the system are discussed and preliminary evaluation results from the parsing of various corpora are given. Results from the comparison of XTAG against the IBM statistical parser and the Alvey Natural Language Tool parser are also given.
* ps file. 7 pages